 |
VOOZH | about |
|
VOOZH | about |
TrueFoundry recognized in Gartner Hype Cycle for Platform Engineering 2026. Read the full report →
Join our VAR & VAD ecosystem — deliver enterprise AI governance across LLMs, MCPs & Agents. Become a Partner →
Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Blazingly fast way to build, track and deploy your models!
Part 1 made the diagnosis: tokenmaxxing is not an AI usage problem; it is a control-plane problem. If raw tokens become a target, people will optimize for raw tokens. If governed AI leverage becomes the operating model, the platform can encourage adoption while bounding cost, risk, and operational noise. This part makes that architecture concrete.
The thesis is simple. Every AI request leaving an enterprise application is, whether you treat it that way or not, a runtime event with cost, safety, and audit consequences. The single highest-leverage place to attach controls to those events is the gateway — the layer that sits between every application and every model and tool backend. A dashboard built downstream can describe what happened. Only the gateway can decide what happens next.
A dashboard reports a problem. A gateway prevents the next one. The architecture below is what makes that distinction operational.
A governed AI request needs four envelopes wrapped around it before it leaves the application. Think of this as the OSI model for enterprise AI — each layer has a specific responsibility and a specific failure mode when it is absent.
| Envelope | What It Contains | Failure Mode Without It |
|---|---|---|
| 🪪 IDENTITY | User, team, project, workflow, environment, cost center, ticket or artifact link | Unattributable spend spikes; no FinOps chargebacks; dashboard shows totals only |
| 🔒 POLICY | Rate limits, budgets, model allowlists, routing, retries, fallbacks, timeouts | Runaway agents; surprise invoices; no circuit breakers; premium-model sprawl |
| 🛡️ SAFETY | LLM input/output guardrails + MCP pre-/post-tool hooks | PII leakage in prompts; prompt injection; credential exposure in outputs |
| 📡 OBSERVABILITY | Resolved model, applied config, latency phases, request/response logs, OTEL export | Unreproducible incidents; blind cost attribution; no regression root-cause |
These envelopes have to be on the request path, not in a report someone reads on Friday. A dashboard built after the fact can describe a problem; only an envelope on the live request can shape the next call. This is the architectural principle that separates a governed AI platform from an analytics add-on.
The first implementation standard is a strict metadata contract. Use string-valued keys, send them on every request, and make them required in your SDK wrappers, internal client libraries, bot frameworks, and agent templates. The cost of one missing field shows up later as a missing invoice line, an unattributable spike, or a guardrail event that no one can route to an owner.
// JSON — minimum metadata contract// Treat as a strict schema, not a suggestion.{
"team": "payments-platform", // maps to FinOps cost center"project_id": "proj-agentic-refactor", // rate/budget scoping key"workflow": "repo-understanding", // routing and policy selector"surface": "ide-agent", // hourly rate-limit selector"environment": "production", // budget tier selector"cost_center": "eng-core", // accounting integration"ticket_id": "ENG-18472", // outcome join key — THE most important field"policy_version": "ai-leverage-v1"// audit trail}
// Python SDK — never skip the metadata header:// extra_headers={"X-TFY-METADATA": json.dumps(metadata)}Tagging is the cheapest engineering work in this entire architecture and the first thing that breaks when teams skip it.
In the TrueFoundry gateway, this travels as the X-TFY-METADATA header. The same key namespace then powers everything downstream: budgets apply per project, rate limits apply per workflow, dashboards group by team, traces join to tickets, and finance allocates spend by cost center. There is no second source of truth.
The architectural objective is not to add knobs. It is to keep a tight mapping between every realistic failure mode and the specific control that prevents it. Here is the complete taxonomy:
| Failure Mode | Control Mechanism | TrueFoundry Docs |
|---|---|---|
| Runaway agent loops | tokens_per_hour rate limit per project/workflow | docs/ai-gateway/ratelimiting |
| Minimum-spend incentives | Project budgets + high-spend review; no individual leaderboards | docs/ai-gateway/budgetlimiting |
| Premium-model overuse | Virtual model routing by workflow and complexity | docs/ai-gateway/load-balancing-overview |
| Unsafe tool calls (agentic) | MCP pre-tool + post-tool guardrails; Cedar/OPA permissions | docs/ai-gateway/guardrails-overview |
| PII leakage in prompts | Input guardrail: PII redaction before model sees content | docs/ai-gateway/tfy-pii |
| Prompt injection attacks | Input guardrail: injection detection; validates, then cancels | docs/ai-gateway/commonly-used-guardrails |
| Credential exposure in outputs | Output guardrail: secrets detection (validate + mutate modes) | docs/ai-gateway/secrets-detection |
| Hard-to-debug regressions | Resolved model, applied config, server-timing phase headers | docs/ai-gateway/headers |
| Prompt drift across providers | Versioned prompt management with per-target overrides | docs/ai-gateway/prompt-management |
| Outcome-blind dashboards | Join gateway metrics to PRs/tickets via ticket_id key | docs/ai-gateway/analytics |
| Multi-cloud lock-in | Virtual models abstract provider names from app code | docs/ai-gateway/load-balancing-overview |
| Silent provider outages | Priority-based fallback routing with per-target retry config | docs/ai-gateway/load-balancing-overview |
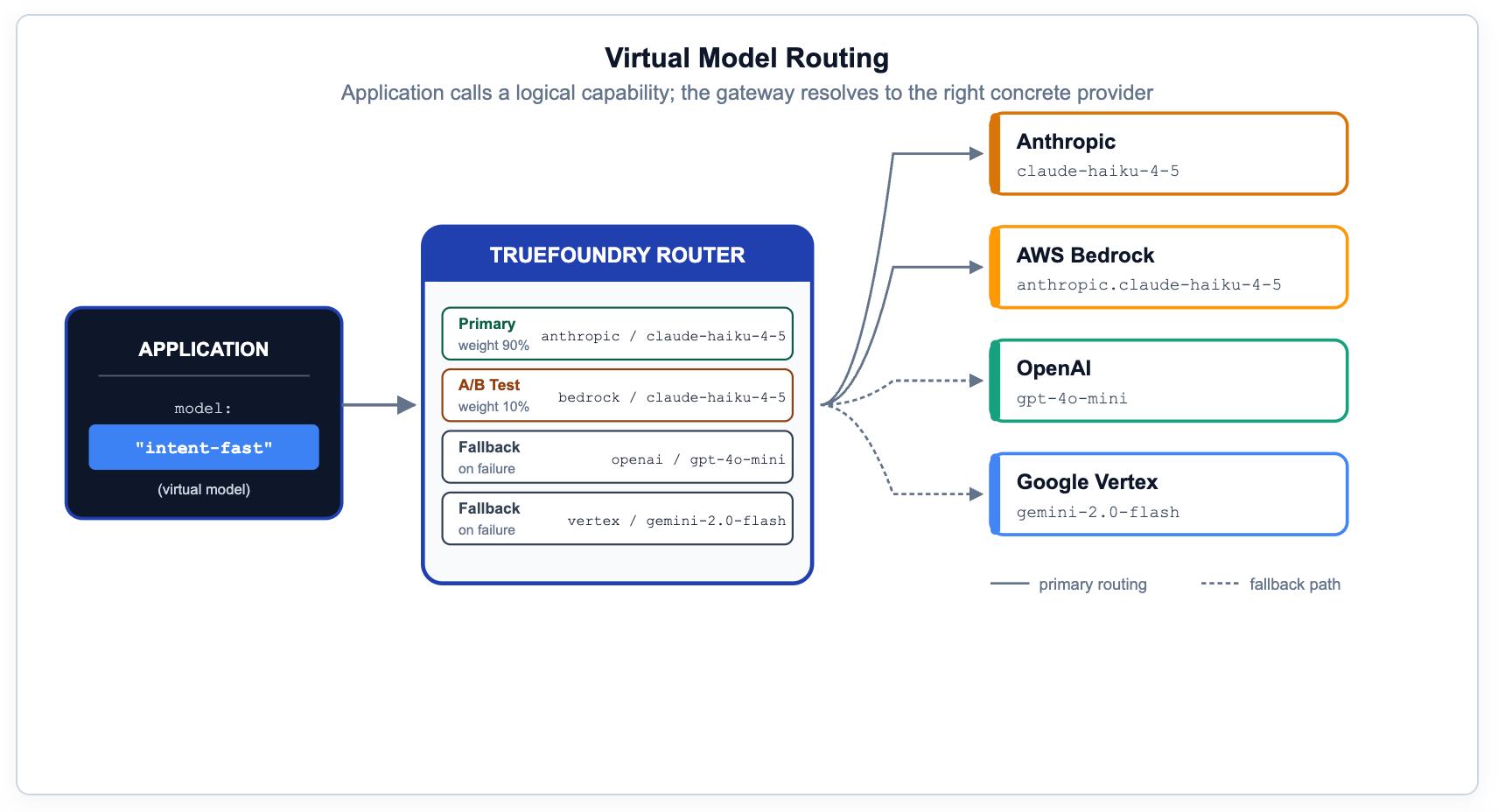
If application code names a specific provider model, you have lost the ability to migrate, test, A/B, or fail over without code changes. The right pattern is to expose logical capabilities — names like prod/engineering-assistant or prod/frontier-reasoning — and let the gateway resolve them to physical targets based on metadata, priority, weight, or measured latency.
In TrueFoundry, this is what Virtual Models and the routing config are for. The same rules cover canary rollouts, regional preference, on-prem-with-cloud-fallback, and provider-specific prompt overrides. This is the most underrated capability in the governance stack — it makes compliance, cost optimization, and model migration invisible to application developers.
# YAML — gateway-load-balancing-config# Evaluated top-to-bottom; first match wins.name:engineering-agent-routingtype:gateway-load-balancing-configrules:# Simple repo questions: cheap-first with frontier fallback.-id:'simple-repo-questions'type:priority-based-routingwhen:models: ['prod/engineering-assistant']
metadata:workflow:'repo-understanding'load_balance_targets:-target:openai-main/gpt-4o-minipriority:0retry_config: {attempts:2, delay:100, on_status_codes: ['429','500']}
fallback_status_codes: ['429', '500', '502', '503']
-target:anthropic-main/claude-sonnetpriority:1# Security-critical: strongest reasoner first.-id:'security-critical-review'type:priority-based-routingwhen:metadata:workflow:'security-review'load_balance_targets:-target:anthropic-main/claude-opuspriority:0-target:openai-main/gpt-4.1priority:1# Cost-sensitive batch: on-prem first, cloud as overflow.-id:'batch-processing-jobs'type:priority-based-routingwhen:metadata:surface:'batch-pipeline'load_balance_targets:-target:on-prem/llama-3.1-70bpriority:0-target:openai-main/gpt-4o-minipriority:1Routing documentation: truefoundry.com/docs/ai-gateway/load-balancing-overview
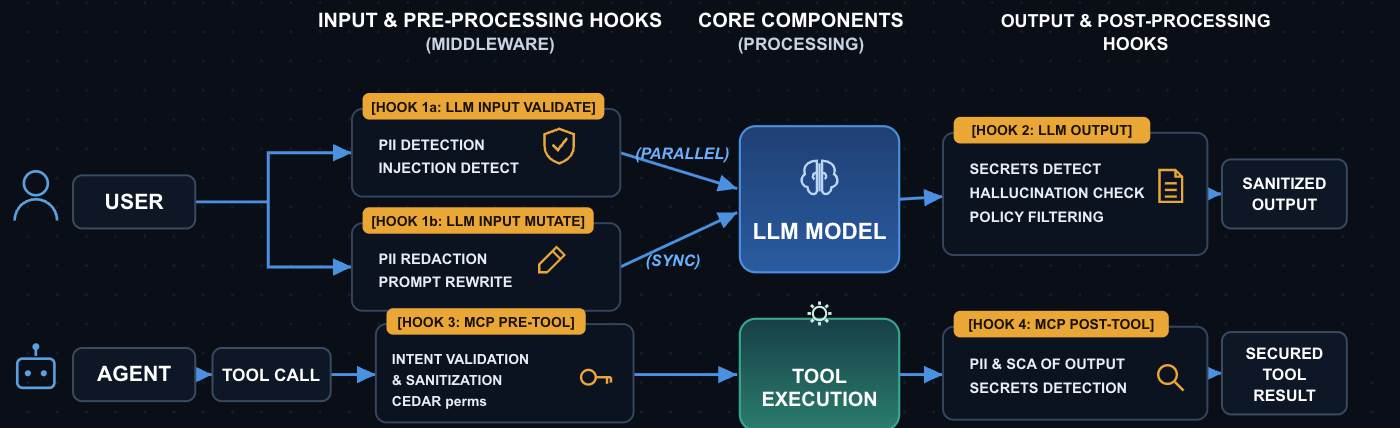
Once AI applications hit production they handle real user data and, in agentic setups, take real actions through tools. The safety perimeter is not one thing. It is four hooks, sitting at the four moments where the gateway can intervene before a request becomes damage.
| Hook | When It Runs | Latency Profile | Primary Use Cases |
|---|---|---|---|
| LLM Input Validate | Before model, parallel | Adds ~0ms (parallel) | Injection detection, topic filtering, policy audit |
| LLM Input Mutate | Before model, sequential | Adds guardrail latency | PII redaction, prompt rewriting |
| LLM Output Validate | After response, async OK | ~0ms if async | Hallucination check, content policy |
| LLM Output Mutate | After response | Adds guardrail latency | Secrets redaction, output filtering |
| MCP Pre-Tool | Before tool invocation | Synchronous, blocking | SQL sanitation, Cedar/OPA permissions |
| MCP Post-Tool | After tool returns | Synchronous, blocking | PII scan of tool outputs, code safety lint |
# Per-request guardrails — passed via X-TFY-GUARDRAILS header.# For org-wide enforcement: AI Gateway → Controls → Guardrails.X-TFY-GUARDRAILS: {
"llm_input_guardrails": [
"global/pii-redaction",
"global/prompt-injection-detection" ],
"llm_output_guardrails": [
"global/secrets-detection",
"global/hallucination-check" ],
"mcp_tool_pre_invoke_guardrails": [
"global/sql-sanitizer",
"global/cedar-permissions" ],
"mcp_tool_post_invoke_guardrails": [
"global/secrets-detection",
"global/pii-redaction" ]
}
# Rollout strategy — never go straight to blocking in production:# Phase 1: mode=audit (log violations, let requests through)# Phase 2: mode=enforce (block on fail, fail-open on provider errors)# Phase 3: mode=strict (block on fail AND on provider errors)Roll guardrails out in three steps: Audit → Enforce-but-ignore-on-error → Strict. The middle setting is the one that will save you on the day a third-party safety provider has an outage.
Guardrails overview: truefoundry.com/docs/ai-gateway/guardrails-overview
PII/PHI detection: truefoundry.com/docs/ai-gateway/tfy-pii
Secrets detection: truefoundry.com/docs/ai-gateway/secrets-detection
Two questions dominate operations once governed AI usage is in production: 'why did this request behave this way?' and 'is the cost we are paying being matched by the work we are getting?' Neither is answerable from a token-count chart.
The minimum surface needed to answer them — and the surface TrueFoundry's gateway provides out of the box:
| Signal | Why It Matters | How to Access |
|---|---|---|
| Resolved model + config | What actually ran vs. what was requested | X-TFY-RESOLVED-MODEL response header |
| Server-timing phases | Gateway / guardrail / model / tool latency split | Server-Timing header on every response |
| Per-request logs (full I/O) | Reproduce incidents exactly; complete audit trail | Analytics API + configurable retention policy |
| OpenTelemetry traces/metrics | Export to Datadog / Grafana / Honeycomb / any OTEL stack | OTEL exporter config in gateway settings |
| Budget/rate-limit events | Alert before ceilings are hit; not after invoices arrive | Slack/email webhooks + analytics events API |
| Guardrail audit events | Which hook fired, what was blocked or mutated, why | Security audit log + OTEL span attributes |
| Metadata-keyed aggregates | Group costs by team, project, workflow, cost center | Analytics dashboard + raw metrics API |
Analytics documentation: truefoundry.com/docs/ai-gateway/analytics
OpenTelemetry export: truefoundry.com/docs/ai-gateway/export-opentelemetry-data
The four envelopes above were designed assuming chat-style requests: an application sends a prompt, the model returns text. Modern AI workloads have moved past that assumption. Agents call tools. Tools call other tools. A single user request can spawn a 50-step agent trajectory that touches half a dozen MCP servers. The cost surface, the safety surface, and the audit surface have all moved from the prompt to the tool call.
This is why the TrueFoundry gateway speaks both LLM API and Model Context Protocol (MCP) natively. The same identity envelope, the same circuit breakers, the same observability hooks apply to a tool call as to a chat completion. OAuth 2.0 identity is injected into MCP tool calls so an agent acts as a specific user, not a service account, when it queries a database or files a Jira ticket. Virtual MCP servers let you compose a logical 'finance-agent-server' from tools spread across three real MCP servers, with access control and rate limits applied to the composition.
The Model Context Protocol matters for cost, not just architecture. TrueFoundry reports up to 99% inference token savings when agents use active tool retrieval instead of stuffing context into prompts — and tool-call overhead measured at roughly 10ms.
It is tempting to push these controls into application code: a wrapper here, a Python decorator there, a helper class in the agent framework. That works until you have three application teams, two model providers, one acquisition, a PCI audit, and a rate-limit incident on a Tuesday.
At that point you discover that you have built four slightly different control planes that disagree, and that none of them can stop a request from a team that did not import the wrapper. The gateway exists for the same reason API gateways did a decade ago: it is the only place where every request, from every application, in every environment, can be observed and shaped uniformly.
The objection to a gateway is always 'one more hop in the request path.' The TrueFoundry AI Gateway adds approximately 5ms of p50 overhead and handles 350+ requests per second on a single vCPU. The objection does not survive contact with the numbers.
| Application-level wrappers | Gateway-level governance (TrueFoundry) |
|---|---|
| Only catches requests from teams that adopted the wrapper | Catches every request from every application unconditionally |
| Policy changes require code deploys across all services | Policy changes deploy once; enforce everywhere instantly |
| Each team re-implements retry, fallback, rate-limit logic | Platform owns retry, fallback, rate-limit — once, for all |
| No cross-team visibility into cost or safety events | Unified cost, safety, and routing view across all teams |
| PCI / SOC-2 audit requires reviewing every service | Single audit surface: the gateway config and its logs |
| Model migration requires touching every calling service | Update the virtual model target; zero application changes |
The gateway is also the only place that can speak the full surface area of modern AI infrastructure: 1000+ LLMs across 19+ providers, plus the MCP servers your agents call, plus the self-hosted models behind your VPC. TrueFoundry was named in the Gartner '10 Best Practices for Optimizing Generative & Agentic AI Costs 2026' report — because the only way enterprises actually optimize at this surface area is by running every request through one governed layer.
Tokenmaxxing is a symptom of unmanaged AI adoption. The architecture above is the cure. Identity defines who is asking. Policy defines what is allowed. Safety defines what is acceptable. Observability defines what actually happened. Together they convert raw token activity into a governed request lifecycle — accountable, useful, safe, tunable.
The goal is not to make AI usage smaller. The goal is to make every line of it explainable.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Product
Company
Resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}