 |
VOOZH | about |
|
VOOZH | about |
TrueFoundry recognized in Gartner Hype Cycle for Platform Engineering 2026. Read the full report →
Join our VAR & VAD ecosystem — deliver enterprise AI governance across LLMs, MCPs & Agents. Become a Partner →
Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Blazingly fast way to build, track and deploy your models!
An LLM Gateway provides a unified interface to manage your organisation's LLM usage:
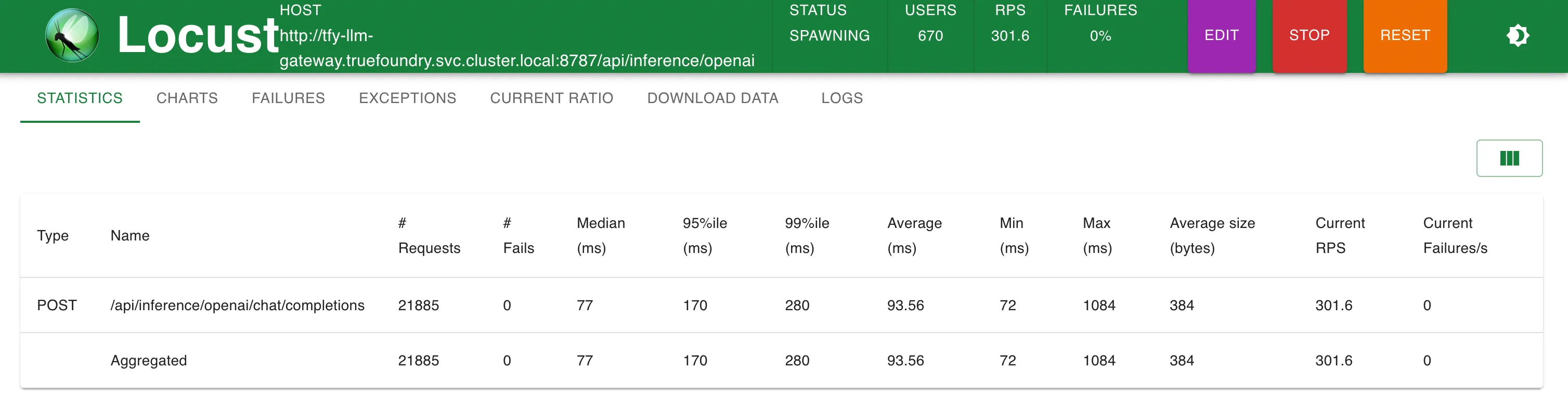
For our load testing experiment, we setup a deployed this fake OpenAI endpoint service using TrueFoundry. The service would simulate OpenAI request and response format without actually producing tokens.
We also deployed the TrueFoundry LLM Gateway and LiteLLM Proxy Server, both running of a single replica with 1 unit CPU and 1 GB memory.
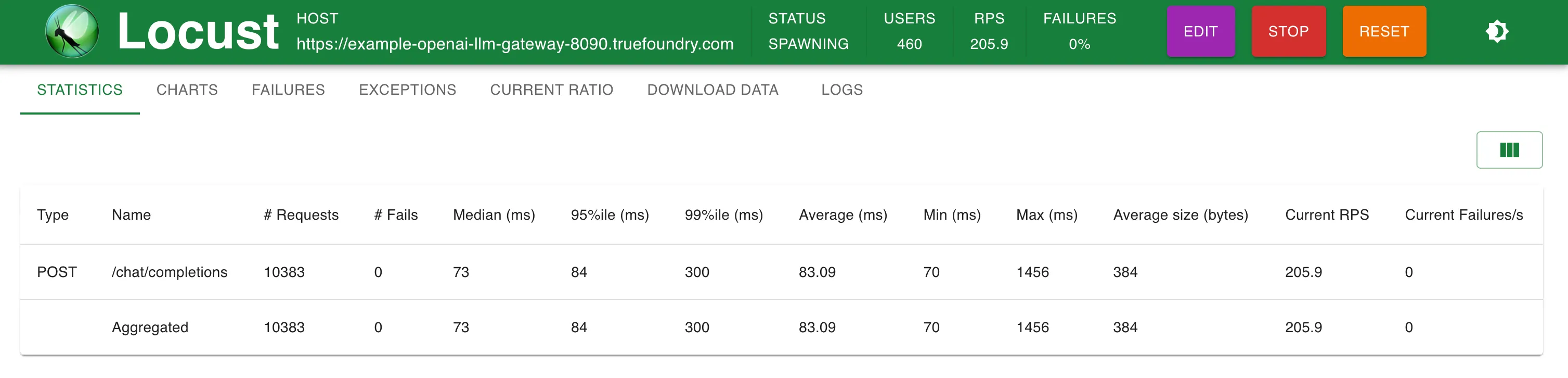
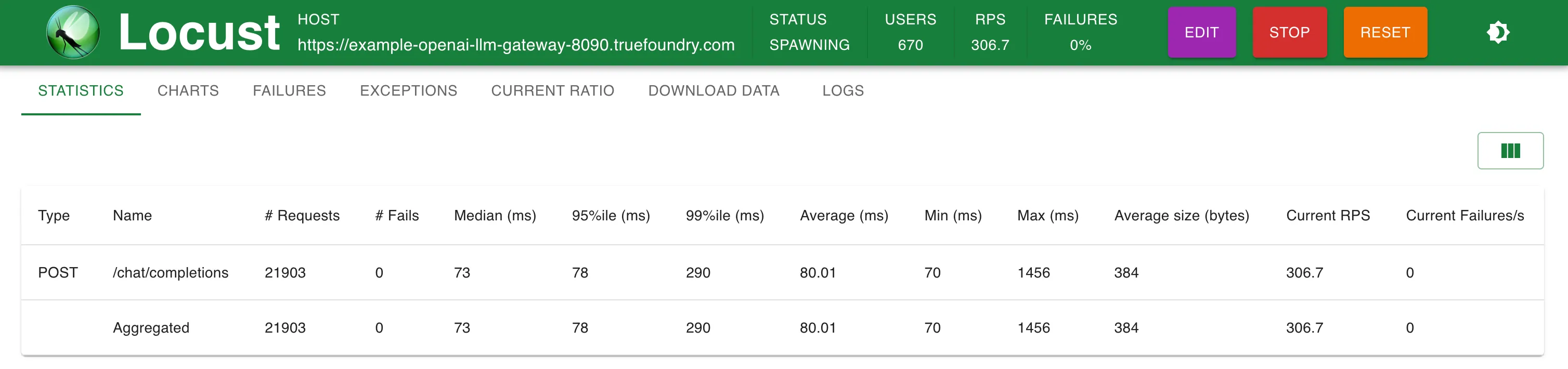
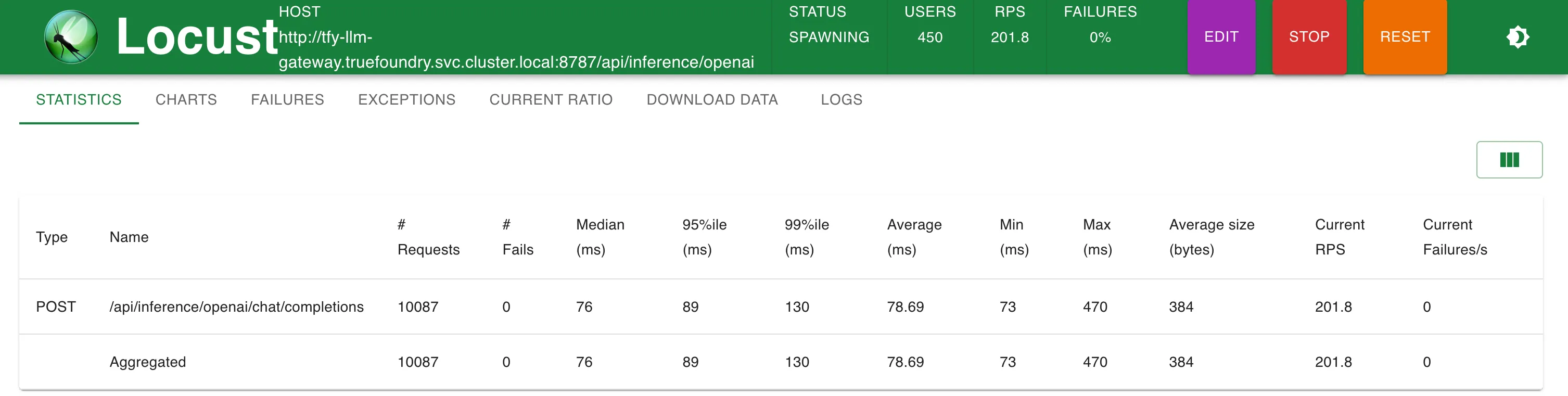
We added our fake OpenAI provider into both TrueFoundry and LiteLLM gateways. While load testing, we made requests to the fake OpenAI server in 3 different ways:
| RPS | 10 RPS | 50 RPS | 200 RPS | 300 RPS |
|---|---|---|---|---|
| OpenAI direct (Setup 1) | 73 ms | 73 ms | 73 ms | 73 ms |
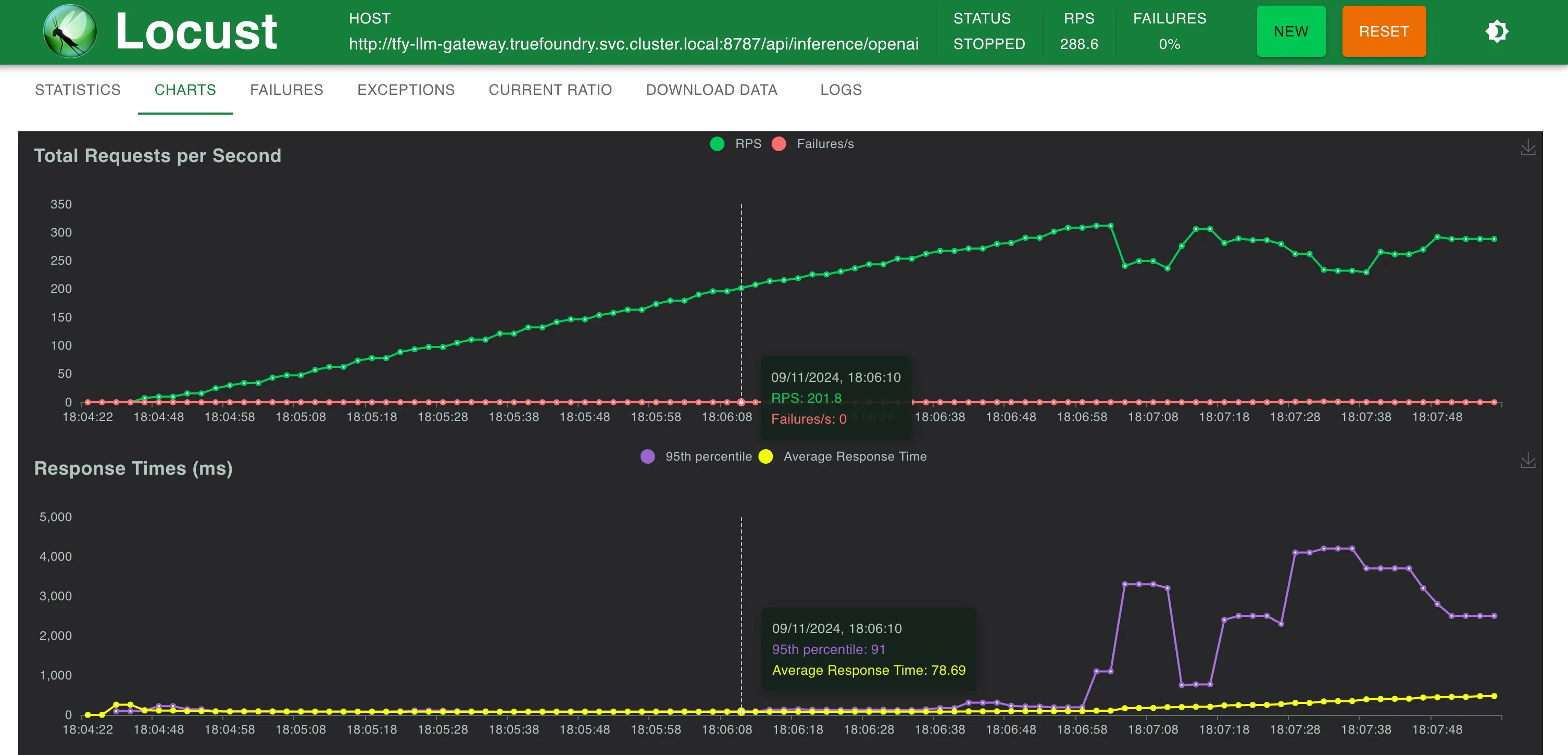
| TrueFoundry LLM Gateway (Setup 2) | 76 ms (+3 ms) | 76 ms (+3 ms) | 76 ms (+3 ms) | 77 ms (+4 ms) |
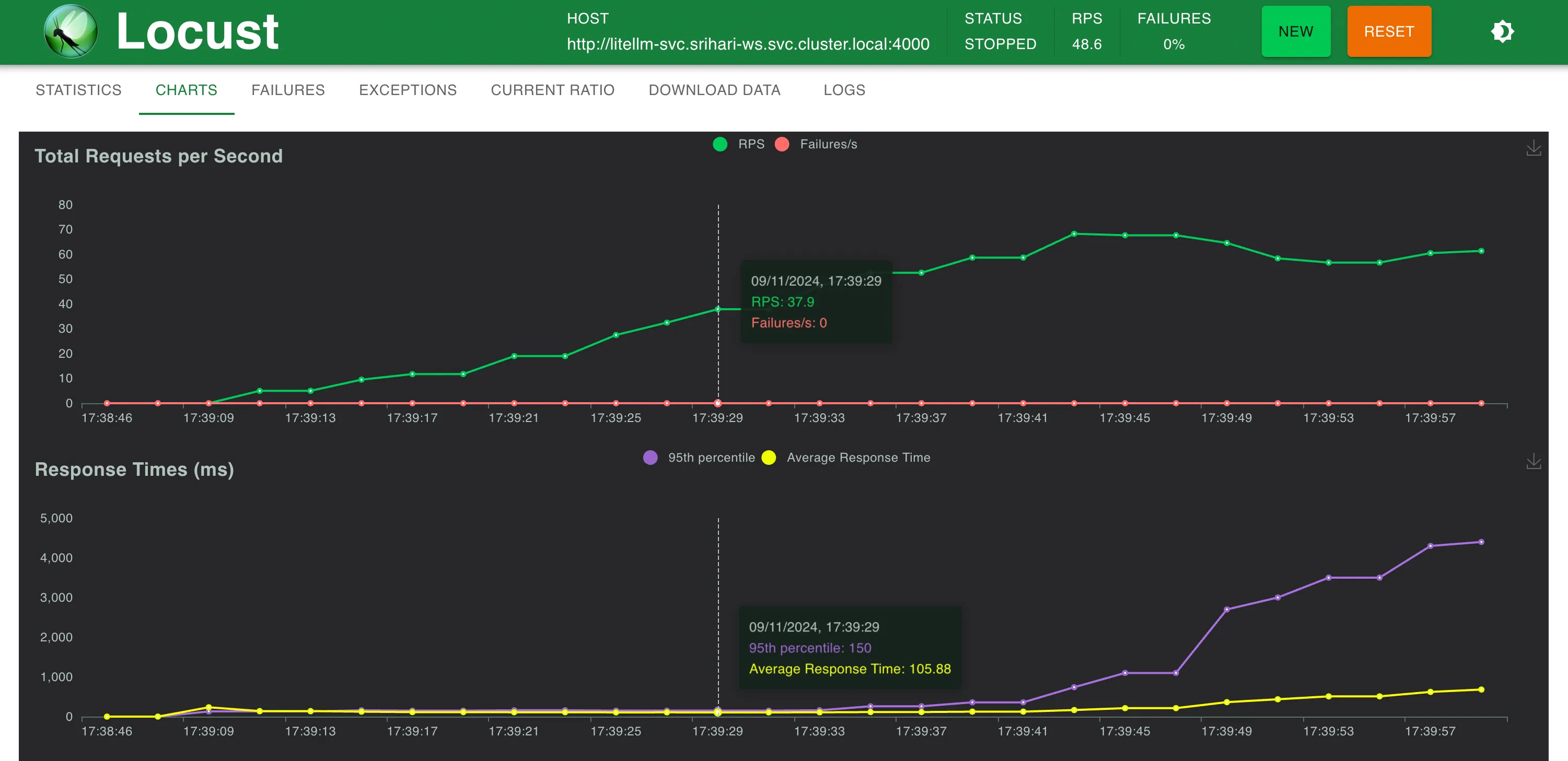
| LiteLLM Proxy (Setup 3) | 88 ms (+15 ms) | 99 ms (+26 ms) | Could not scale to 200 RPS | Could not scale to 300 RPS |
Setup 1: Direct OpenAI endpoint calling
Setup 2: TrueFoundry LLM Gateway
Setup 3: LiteLLM
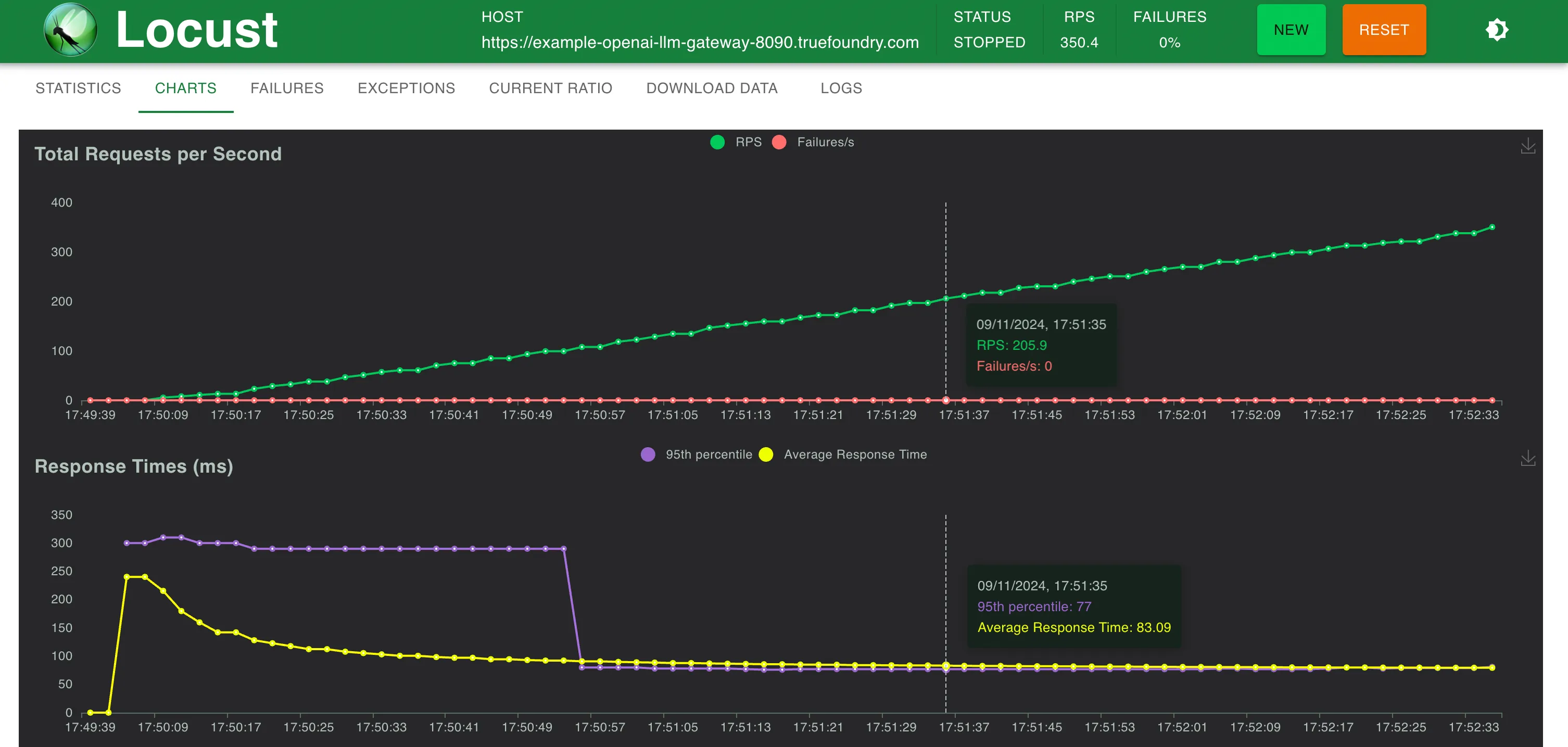
t2.2xlarge AWS instance (43$ per month on spot) machine can scale upto ~3000 RPS with no issues.Below is a comprehensive list of popular LLM providers that is supported by TrueFoundry LLM Gateway:
| Provider | Streaming Supported |
|---|---|
| GCP | ✅ |
| AWS | ✅ |
| Azure OpenAI | ✅ |
| Self Hosted Models on TrueFoundry | ✅ |
| OpenAI | ✅ |
| Cohere | ✅ |
| AI21 | ✅ |
| Anthropic | ✅ |
| Anyscale | ✅ |
| Together AI | ✅ |
| DeepInfra | ✅ |
| Ollama | ✅ |
| Palm | ✅ |
| Perplexity AI | ✅ |
| Mistral AI | ✅ |
| Groq | ✅ |
| Nomic | ✅ |
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Product
Company
Resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
.webp){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}