 |
VOOZH | about |
|
VOOZH | about |
Fraud is an act of intentional deception or dishonesty perpetrated by one or more individuals, generally for financial gain. In most cases, the company will seek to mitigate the risks by implementing controls. These could be preventative, monitoring, or detection controls. Being able to assess fraud risk provides us with priorities as to where to invest time and resources to have the largest impact in detecting and reducing incidents of fraud.
The fraud analysts are interested in are unexpected or strange items, such as outliers or too many inliers. They target suspicious transactions or transactions that are too typical to be natural. They look at the unusual in relation to the usual.
Z‐Score: The term Z‐score, Z‐values, Z‐ratio, or Z is a statistical measurement of a number in relation to the mean of the group of numbers. It refers to points along the base of the standardized normal curve. The center point of the curve has a Z‐value of 0. Z‐values to the right of 0 are positive and Z‐values to the left are negative values
Relative size factor (RSF) test: The purpose of the RSF test is to identify anomalies where the largest amount for subsets in a given key is outside the norm for those subsets. This test compares the top two amounts for each subset and calculates the RSF for each: RSF = Largest Record in a Subset /
Second Largest Record in a Subset
Same‐same‐same test: The purpose of the same‐same‐same (SSS) test is to identify abnormal duplications as potential indicators of errors or fraud.
Same‐same‐different test: The same-same-different (SSD) test is used to identify records with near-duplicates for fields selected by the auditor. The auditor may select up to eight fields to match and one field that is excluded from the matching. The same‐same‐different test is a powerful test for errors and fraud. This test should be considered for every forensic analytics project. This test always detects errors in accounts payable data and the longer the time period, the higher the chances of SSD detecting errors.
Even amounts: Even or rounded‐dollar amounts do not normally occur at high‐frequency rates. Therefore numbers that are rounded to tens, hundreds, and thousands may be considered anomalies and some attention should be given to them.
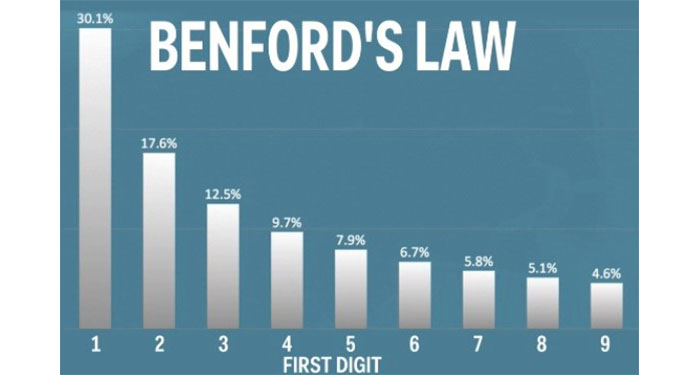
Benford’s Law: Benford’s Law tests are the first digit, first two digits, first three digits, and second digit tests. Advanced Benford’s Law tests are summation and second order. Benford’s analysis, when used correctly, is a powerful tool for identifying suspect accounts or amounts for further analysis. Benford’s analysis is a tool to complement additional tests/tools.
Number duplication test: The NDT can output specific numbers that caused the spikes in the first-order tests (the first two digits test is one example) and the summation test, which is an advanced Benford’s Law test.
GEL‐1 AND GEL‐2: GEL is short for the gestalt element link. GEL is a structure, configuration, or pattern of physical, biological, or psychological phenomena so integrated as to constitute a functional unit with properties not derivable by summation of its parts. The purpose of the GEL tests (GEL‐1 and GEL‐2) is to detect the relationship or link within the data file as potential indicators of fraud.
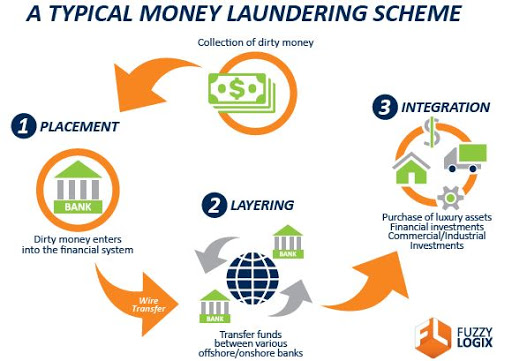
When money is obtained from various illegal activities such as corruption, bribery, tax evasion, drugs, where the criminal does not want the authorities to know the source of the income, they engage in money laundering. Money laundering disguises the illegal origin and legitimizes the funds so they can be openly used.
The Placement Stage: The objective is to place the cash into foreign or domestic bank accounts without raising red flags. To make the dirty money appear to be clean, deposits are made into domestic banks by splitting the large amount into smaller amounts and making multiple deposits below reporting limits to avoid detection.
The Layering Stage: The layering stage is the most complex of all the stages; this is where the origin of the money is being made difficult to trace. A number of transactions or layers need to be put between the original sources of the funds before they are brought back into the legal economy.
The Integration Stage: In the integration stage, the money enters back into the legitimate economy where it appears to have come from legal and normal transactions. Depending on the layering stage, the return may appear to come from a sale of assets such as real estate.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
GPT-4 vs. Llama 3.1 – Which Model is Better?
Llama-3.1-Storm-8B: The 8B LLM Powerhouse Surpa...
A Comprehensive Guide to Building Agentic RAG S...
Top 10 Machine Learning Algorithms in 2026
45 Questions to Test a Data Scientist on Basics...
90+ Python Interview Questions and Answers (202...
8 Easy Ways to Access ChatGPT for Free
Prompt Engineering: Definition, Examples, Tips ...
What is LangChain?
What is Retrieval-Augmented Generation (RAG)?
Edit
Resend OTP
Resend OTP in 45s
{kind=link}
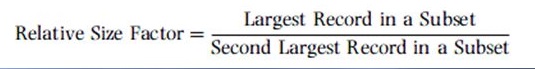{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}