
The 7 best Claude Opus 4.6 alternatives in 2026
{kind=link}
{kind=link}
Last edited June 17, 2026
{kind=link}
Table of Contents
Why look for a Claude Opus 4.6 alternative
Let's be fair to Claude first, because it earns the loyalty it has. Opus is the model that completes hard agentic coding tasks end-to-end where others stall, Claude Code leads on real-world software benchmarks, and its writing comes out more natural and less "AI-smelling" than most rivals. For long-document reasoning across a 200K-token window, it is still one of the safest picks you can make.
So why are so many people searching for a way out? A few concrete reasons:
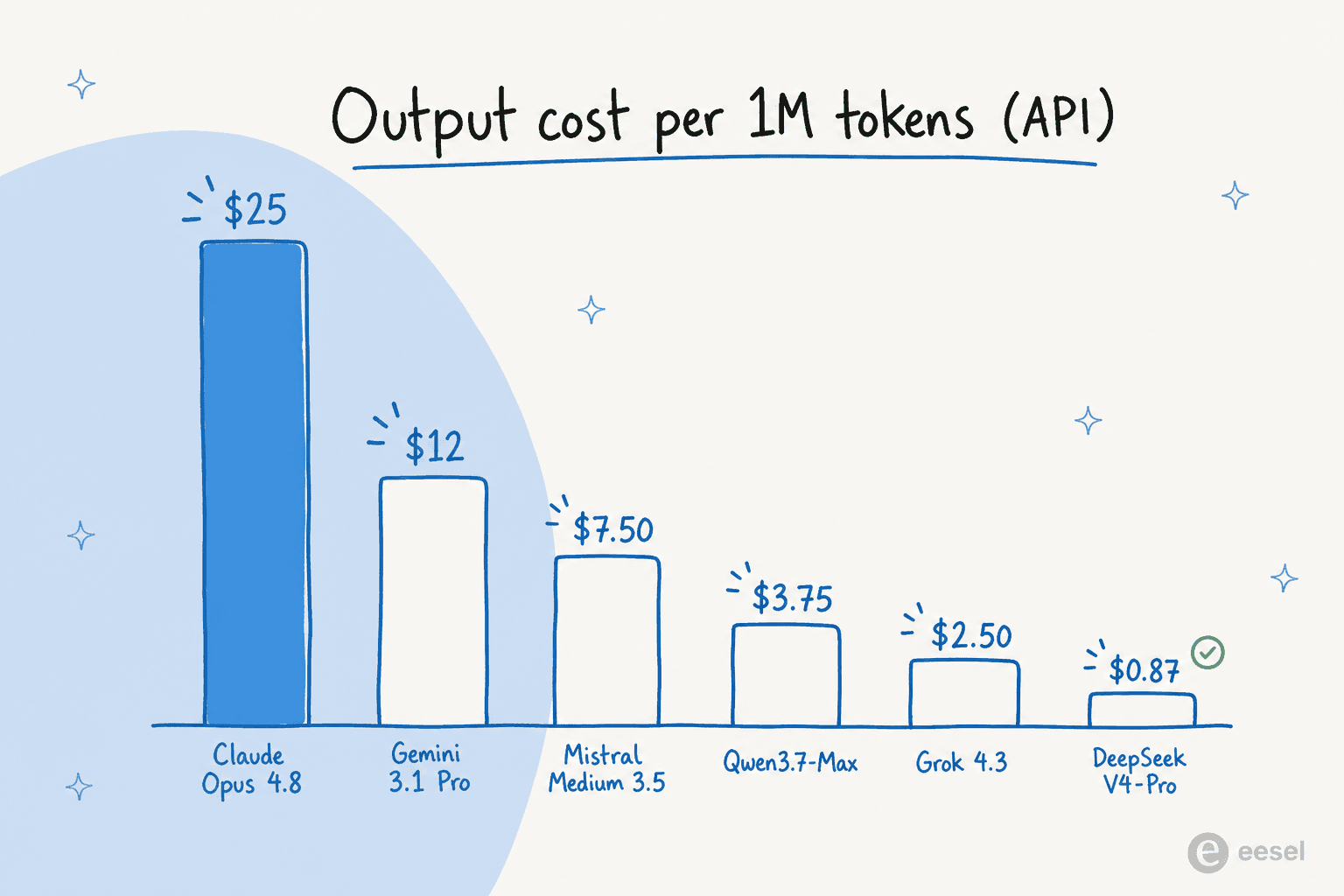
- The API cost. Opus is the premium tier, and the gap is not subtle. At 25 dollars per million output tokens, it is roughly 28 times the price of DeepSeek's flagship for the same unit of output. Anthropic held the sticker price flat across versions, but a tokenizer change in the 4.7 era quietly raised the effective cost by 20 to 35 percent anyway.
- Usage limits. This is the single loudest complaint. Even people on the 100 dollar Max plan report burning through their window astonishingly fast.
- Missing capabilities. No native image generation, and live web access still lags competitors that were built around real-time search.
That last cluster is what tips people over. Here is the kind of thing you see all over r/ClaudeAI:
"After my usage limits reset, I sent one prompt. Within 12 minutes, it ate 21% of my 5-hour limit. I am on the 5x ($100) plan."
The cost picture is the clearest way to see why the alternatives are tempting. When you line up the flagship models on output-token price, Opus is alone at the top:
{kind=link}
One thing worth saying out loud: "alternative to Opus 4.6" does not always mean "leave Claude." Sometimes it just means getting Claude on better terms, or pairing it with a model that fills its gaps. We'll flag both kinds below. For the consumer-plan side of the cost story, our Claude pricing guide has the full tier-by-tier breakdown.
How we picked
We weighted four things a real buyer cares about: raw capability (does it actually match Opus on reasoning and coding), total cost (sticker and effective), context window and live-data access, and how easy it is to put into a real workflow rather than a chat window. Every price and model name below was verified against the vendor's own pages in June 2026.
The 7 best Claude Opus 4.6 alternatives at a glance
| Tool | Best for | Latest model | Free tier | Paid from | Context window | Open weights | Live web |
|---|---|---|---|---|---|---|---|
| ChatGPT | All-round capability | GPT-5.5 | Yes | $8/mo (Go) | Up to 400K (Pro) | No | Yes |
| Google Gemini | Long context + Google apps | Gemini 3.1 Pro | Yes | $7.99/mo | Up to 1M | No | Yes |
| xAI Grok | Real-time X data | Grok 4.3 | Yes | ~$30/mo | 1M | No | Yes (incl. X) |
| Mistral (Vibe) | EU data residency | Mistral Medium 3.5 | Yes | $14.99/mo | 256K | Yes | Yes |
| DeepSeek | Lowest cost | DeepSeek V4 | Yes (web) | API pay-as-you-go | 1M | Yes | No (native) |
| Qwen | Open-weight + multilingual | Qwen3.7-Max | Yes | API pay-as-you-go | Up to 1M | Yes (Apache 2.0) | No (native) |
| Perplexity | Research with citations | Model-agnostic | Yes | $20/mo | Inherits model | No | Yes |
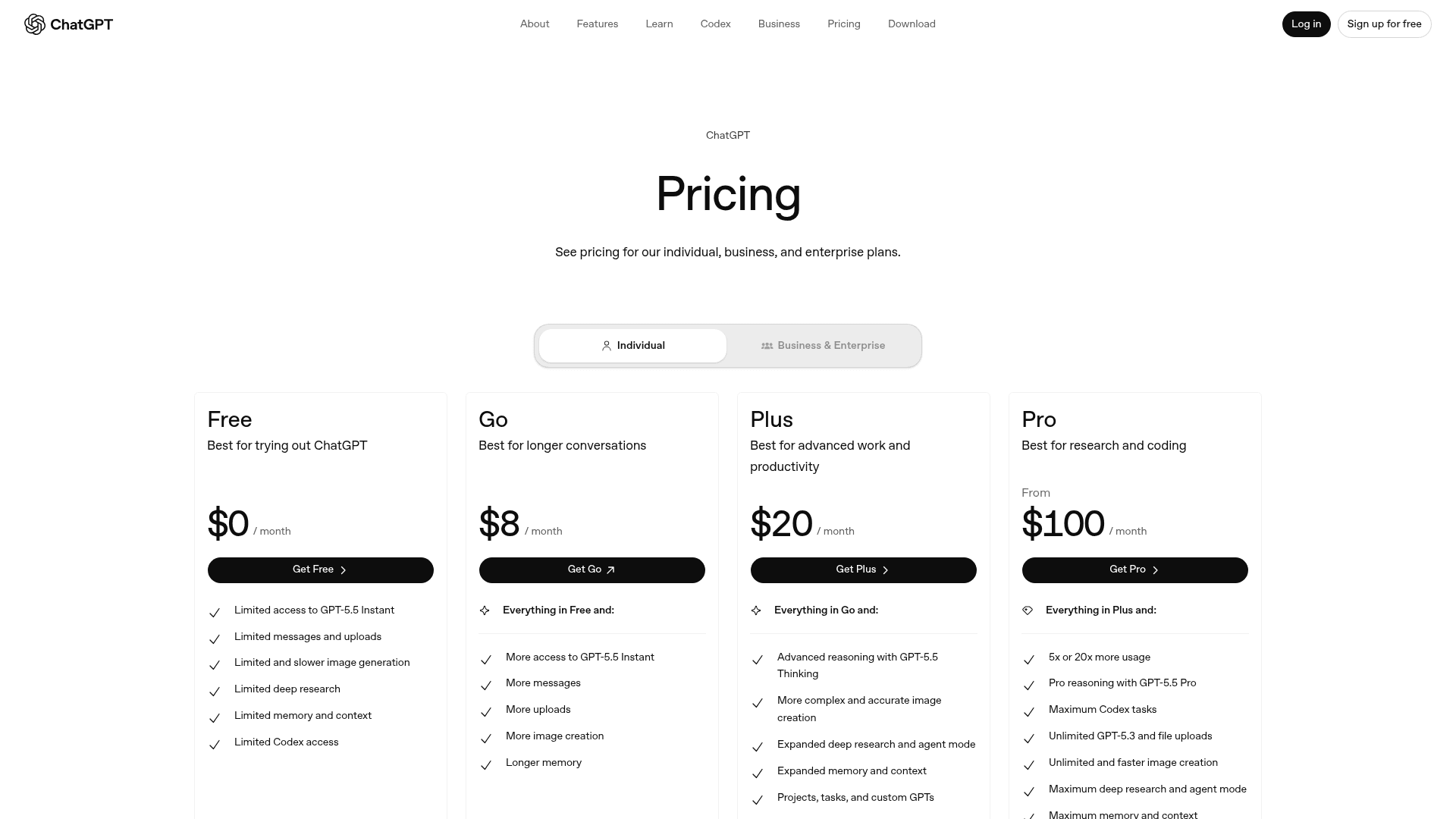
1. ChatGPT (GPT-5.5)
Best for: the broadest all-rounder, and the most natural one-to-one replacement for a daily Claude habit.
{kind=link}
If you're leaving Opus and want the least friction, ChatGPT is the obvious move. The current model, GPT-5.5, shipped in April 2026 and ships in Instant, Thinking, and Pro variants, so you can dial reasoning depth to the task. Where Claude is a specialist that happens to be great at many things, ChatGPT is built as the everything-app: writing, coding, data analysis, image generation, and voice in one place. It is also the most-reviewed assistant out there, sitting at 4.7 out of 5 across more than 2,500 G2 reviews.
Pros
- The widest capability surface of any tool here, with Deep Research standing out for cited, multi-source reports.
- Genuinely useful free tier, plus an $8 Go plan that undercuts most paid rivals.
- Huge ecosystem of integrations and custom GPTs.
Cons
- Costs stack fast for power users: the Pro tier runs $100 to $200 a month, and there is no consumer pay-as-you-go.
- Full 400K context and GPT-5.5 Pro are gated behind that Pro tier; free and Go users get a much smaller window.
- Ads arrived on the free and Go tiers in 2026, and data training is opt-in by default, which some users flag as a privacy friction.
| Plan | Price | Notes |
|---|---|---|
| Free | $0 | Limited GPT-5.5 Instant access |
| Go | $8/mo | More messages, uploads, memory |
| Plus | $20/mo | GPT-5.5 Thinking, ~256K reasoning context |
| Pro | from $100/mo (up to $200) | GPT-5.5 Pro, up to 400K context |
| Business / Enterprise | ~$25/seat/mo / custom | Admin, security, data controls |
Here is a real user on what it actually replaces, from G2:
"I use ChatGPT for a lot of things like research, emails, rephrasing content, generating files, coding, and integrating with tools. I find it incredibly helpful for generating C# and JS code as per my requirements."
Our take: if you just want Opus-level quality without thinking too hard about it, ChatGPT is the safe default. It matches Claude on most tasks and beats it on breadth. Power users who live in the Pro tier will not save money versus Claude, though. For the head-to-head, we wrote up Claude vs ChatGPT separately.
2. Google Gemini (3.1 Pro)
Best for: enormous context windows and anyone already living in Google Workspace.
Gemini is the other model that genuinely competes at the top. Gemini 3.1 Pro ships a 1-million-token context window, native multimodality across text, image, video, and audio, and Search grounding baked in. If your work involves dumping huge documents or codebases into the model, this is the headline feature Claude cannot match on paper. It is also deeply wired into Gmail, Docs, and Android, which is a real productivity multiplier if that is where you work.
Pros
- The largest context window here by a mile, with strong reasoning and coding benchmarks.
- Tight Google Workspace integration and live Search grounding.
- Aggressive consumer pricing, with an AI Plus tier at just $7.99 a month.
Cons
- That 1M window degrades in practice. Developers report errors past around 200K tokens, and some Pro users say context feels capped far lower.
- Paid-tier bugs crop up, including subscribers losing features free users kept.
- It can lose the thread on very long conversations.
| Plan | Price | Notes |
|---|---|---|
| Free | $0 | Baseline Gemini access |
| Google AI Plus | $7.99/mo | More usage, higher limits |
| Google AI Pro | $19.99/mo | Gemini 3.1 Pro, Deep Think |
| Google AI Ultra | from $99.99/mo (up to $199.99) | Highest limits, top models |
A nice illustration of where it pulls ahead, from r/GeminiAI:
"As an applied math student, I've noticed Gemini is way better with math expressions. GPT makes dumb mistakes with operators and coefficients all the time."
Our take: Gemini is the alternative to reach for when context size or Google integration is the deciding factor. Just treat the 1M number as a ceiling, not a promise. We compared the two directly in Claude vs Gemini, and the Gemini pricing guide has the full plan detail.
3. xAI Grok (4.3)
Best for: real-time information and X-native builders who want frontier reasoning at an aggressive price.
{kind=link}
Grok has quietly become a serious option. Grok 4.3 launched at the end of April 2026 with a 1M-token context, agentic tool-calling, and a genuinely unique feature: native x_search, which gives it live access to what is happening on X right now. No other major model offers that. And xAI has priced it to win, at 1.25 dollars per million input and 2.50 per million output, a fraction of Opus.
Pros
- Live X/Twitter real-time search that no competitor matches.
- Very low frontier pricing with a full 1M context window.
- Fast release cadence and strong leaderboard results, including a number-one voice-agent ranking in early 2026.
Cons
- Production reliability is inconsistent; developers report unpredictable token spikes and tool-calling failures.
- Aggressive model retirements have broken integrations mid-flight.
- The $300 SuperGrok Heavy tier draws vocal "rip-off" pushback.
| Plan | Price | Notes |
|---|---|---|
| Free | $0 | Limited daily use on grok.com / X |
| SuperGrok | ~$30/mo | Higher limits, multi-agent mode |
| SuperGrok Heavy | $300/mo | Up to 8 parallel agents, max compute |
| API (grok-4.3) | $1.25 / $2.50 per 1M | Input / output, 1M context |
A candid developer note on the trade-off, from r/singularity:
"Have you tried integrating it into a product? My experience has been very mixed... The goods are really good. The bads are REALLY bad... Randomly uses so many tokens even with reasoning_effort set to 'low'."
Our take: Grok is the pick when you need live, real-time context or you are building on X, and the API price is hard to argue with. We would not yet bet a fragile production pipeline on it without guardrails, given the reliability reports.
4. Mistral (Le Chat, now Vibe)
Best for: European data residency, open-weight self-hosting, and the lowest flagship API price among Western labs.
Mistral is the leading European option, and the one to look at first if GDPR or data sovereignty is a hard requirement. Its chat product, Le Chat, was renamed Vibe in late May 2026 as it leaned into agentic work. The flagship Mistral Medium 3.5 carries a 256K context, and crucially the models ship with open weights you can self-host on your own infrastructure. On price, it is the cheapest flagship-class API in this list.
Pros
- Fast, low-latency responses, the most consistent praise from its users.
- EU hosting plus open weights for true data sovereignty and on-prem deployment.
- The cheapest flagship-class API rates here, with a generous free tier.
Cons
- The capability ceiling sits below the frontier labs; users are blunt that it trails Claude and GPT on the hardest reasoning.
- Platform-level bugs (hallucinations, context bleeding) get reported separately from model quality.
- Consumer review sentiment on Trustpilot is weak, and the Vibe rebrand is too new for much verdict data.
| Plan | Price | Notes |
|---|---|---|
| Free | $0 | Vibe chat |
| Pro | $14.99/mo | Higher limits, more features |
| Team | $24.99/user/mo | $50/mo minimum |
| API (Medium 3.5) | $1.5 / $7.5 per 1M | Input / output, 256K context |
One Mistral user being refreshingly honest about the trade-off, from r/MistralAI:
"The Mistral models, including the largest, are among the worst performers I have tried so far. So at the moment I am using Claude Opus 4.5 which obviously is a lot more expensive, but it's incredibly good."
Our take: pick Mistral when data residency or self-hosting is non-negotiable, or when you want a cheap, fast model for high-volume, lower-complexity work. Do not expect it to match Opus on the hardest reasoning. The Mistral pricing guide and our Claude vs Mistral comparison go deeper.
5. DeepSeek (V4)
Best for: the lowest cost, full stop, and open-weight reasoning for research and self-hosting.
If the bill is your only problem, DeepSeek is the answer. The current DeepSeek V4 line runs near-frontier reasoning at prices that look like typos next to Opus: V4-Flash is $0.14 per million input and $0.28 output, with V4-Pro still under a dollar per million output. The web chat is free and unlimited, the models are open-weight on Hugging Face, and the context window is a full 1M tokens. Independent guides peg V4-Flash at up to 99% cheaper than GPT-5.5.
Pros
- An extreme cost advantage that nothing else here comes close to.
- Open weights for self-hosting and research, plus a free web chat.
- Strong reasoning and coding; the V3.2-Speciale line took gold-medal results at IMO, ICPC, and IOI 2025.
Cons
- Data hosting is the big one: all user data sits on servers in China, and security probes plus the resulting bans (Italy, US Navy, NASA) make it a non-starter for regulated data.
- Built-in censorship on sensitive topics is baked in at the training and response layers.
- "Open" is impractical for most teams; self-hosting needs serious GPU, so the easy path routes back through China-hosted infrastructure.
| Plan | Price | Notes |
|---|---|---|
| Web chat | $0 | Free, unlimited |
| API V4-Flash | $0.14 / $0.28 per 1M | Input / output (cache-miss) |
| API V4-Pro | $0.435 / $0.87 per 1M | Input / output |
Our take: for cost-sensitive, non-regulated workloads, or for researchers who want open weights, DeepSeek is unbeatable on price. For anything touching customer or regulated data, the China-hosting question rules it out for most Western teams, and no discount is worth that risk.
6. Qwen (3.7-Max)
Best for: open-weight flexibility, multilingual work, and cheap coding without a vendor lock-in.
{kind=link}
Alibaba's Qwen has become the default of the open-weight world. The flagship Qwen3.7-Max is a 1M-context, agent-era model, but the real story is the open ecosystem underneath it: most Qwen checkpoints are Apache 2.0 licensed and freely self-hostable, and Qwen models dominate Hugging Face download rankings. The web chat is free, and its mixture-of-experts design keeps inference structurally cheap.
Pros
- Genuinely open and self-hostable under Apache 2.0, with broad multilingual coverage (119 languages in pretraining).
- The most-downloaded open-model family, with a 1M coding context that beats Claude's 200K.
- Structurally cheap MoE inference and a free consumer chat.
Cons
- The managed Alibaba Cloud API is China-hosted, a recurring enterprise compliance blocker.
- Token-verbose output and weak prompt caching can erode the per-token savings.
- The free developer API tier was killed in April 2026, causing churn.
| Plan | Price | Notes |
|---|---|---|
| Qwen Chat | $0 | Free web chat |
| Open weights | $0 | Self-host, Apache 2.0 |
| API (Qwen3.7-Max) | ~$1.25 / $3.75 per 1M | Input / output (promo rates) |
| API (Qwen-Turbo) | ~$0.05 / $0.20 per 1M | Cheapest tier |
Our take: Qwen is the best choice if you want to own your stack with open weights, or you need strong multilingual and coding output on a budget. Like DeepSeek, the hosted API's China origin is the catch for regulated data; self-hosting sidesteps it if you have the hardware. Our Qwen review and Qwen pricing guide cover it in depth.
7. Perplexity
Best for: research and fact-finding with live citations, and quietly keeping Claude in the mix.
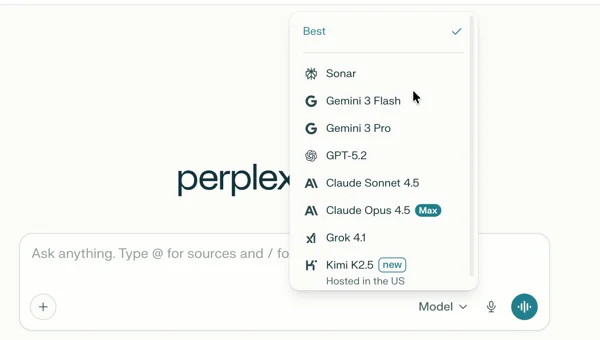{kind=link}
Perplexity is the odd one out here, in a useful way. It is not a model; it is an answer engine that researches the live web and returns cited answers, and it lets you choose which frontier model runs underneath. Open the model picker and you'll see GPT-5.2, Gemini 3 Pro, Grok, and Claude all sitting there. That makes it the one "alternative" that can actually keep you on Claude, for 20 dollars a month, without a separate Claude Max subscription. Every answer comes with clickable inline citations, so there is no knowledge cutoff to worry about.
Pros
- Live web grounding with verifiable citations and no knowledge cutoff.
- One subscription switches between frontier models, including Claude, plus Spaces and file analysis.
- Comet, its agentic browser, automates research and tab-heavy workflows.
Cons
- Pro users report undisclosed throttling on deep research and model routing that does not always honour the selected model.
- Built-in image generation is weak versus dedicated tools.
- It is a research layer, not a coding or long-form workspace, so power users pair it with ChatGPT or Claude.
| Plan | Price | Notes |
|---|---|---|
| Free | $0 | ~5 Pro searches/day |
| Pro | $20/mo ($17 annual) | Frontier model picker, Spaces |
| Max | $200/mo | Higher limits, priority access |
| Enterprise | from $40/seat/mo | Admin and security controls |
The value framing that keeps coming up, from r/perplexity_ai:
"Perplexity Max is the best deal in $200-$300/month range among all AI plans."
Our take: Perplexity is the best research tool here, and the smart move if you mostly liked Opus for fact-finding and want to keep using Claude without the Max bill. It is not where you go to write a 5,000-word document or refactor a repo. The Perplexity alternatives post covers the rest of the field.
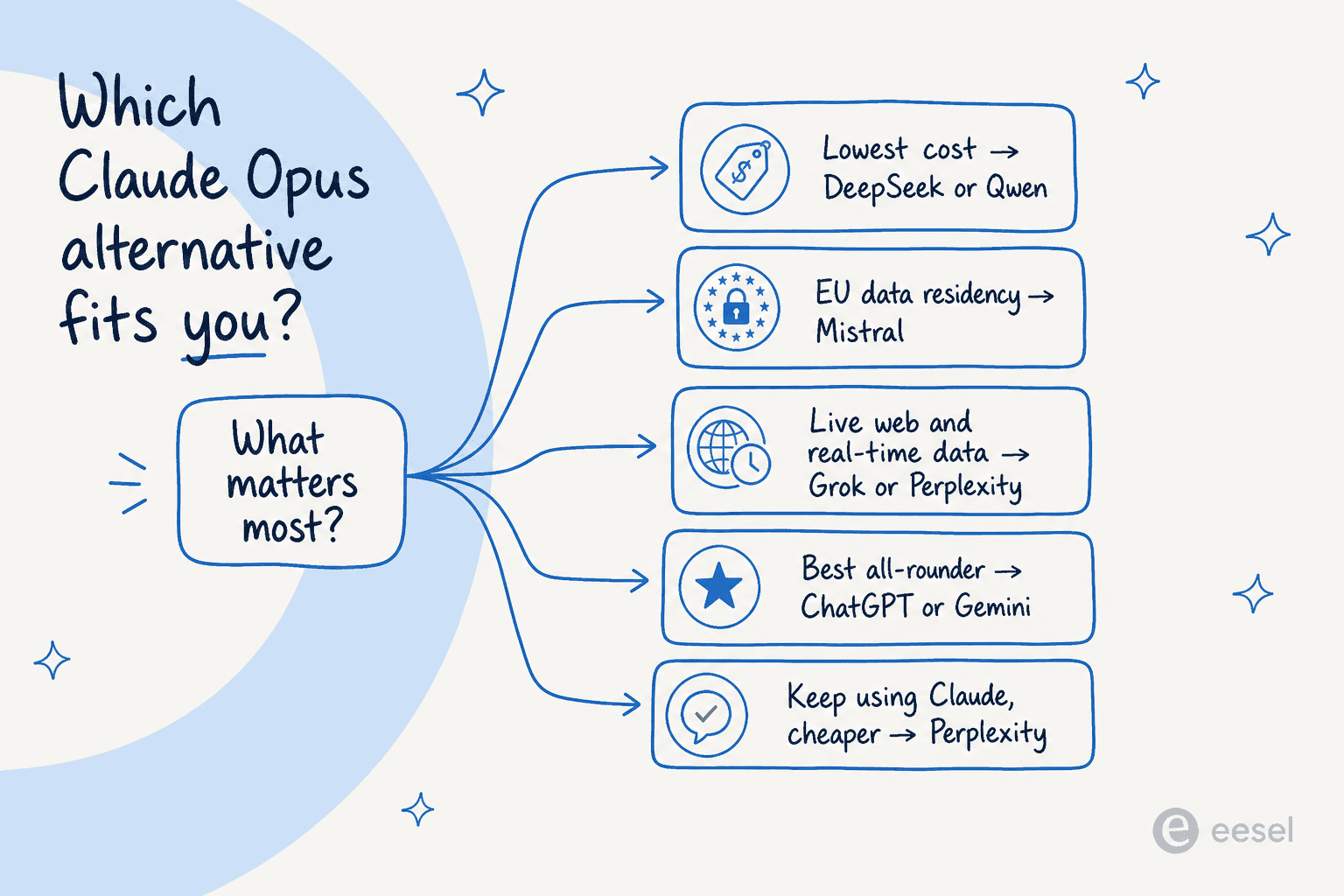
Which alternative should you choose?
The honest answer is that there is no single winner, because "alternative to Opus 4.6" means different things depending on what was bugging you about Opus. Here is how we'd decide:
{kind=link}
- Want the closest match without overthinking it? ChatGPT or Gemini.
- Cost is the whole problem? DeepSeek or Qwen, as long as your data isn't regulated.
- GDPR or data residency matters? Mistral.
- You need live, real-time information? Grok or Perplexity.
- You actually still want Claude, just cheaper? Perplexity Pro.
But there's a category of buyer this whole list quietly misleads: if you're picking a model to power customer support or internal Q&A, you're shopping for the wrong thing. The model is a commodity that will be leapfrogged again next quarter. What matters is the layer that connects a model to your tickets, your docs, and your helpdesk, with the guardrails to run safely. That's the next section.
Try eesel AI
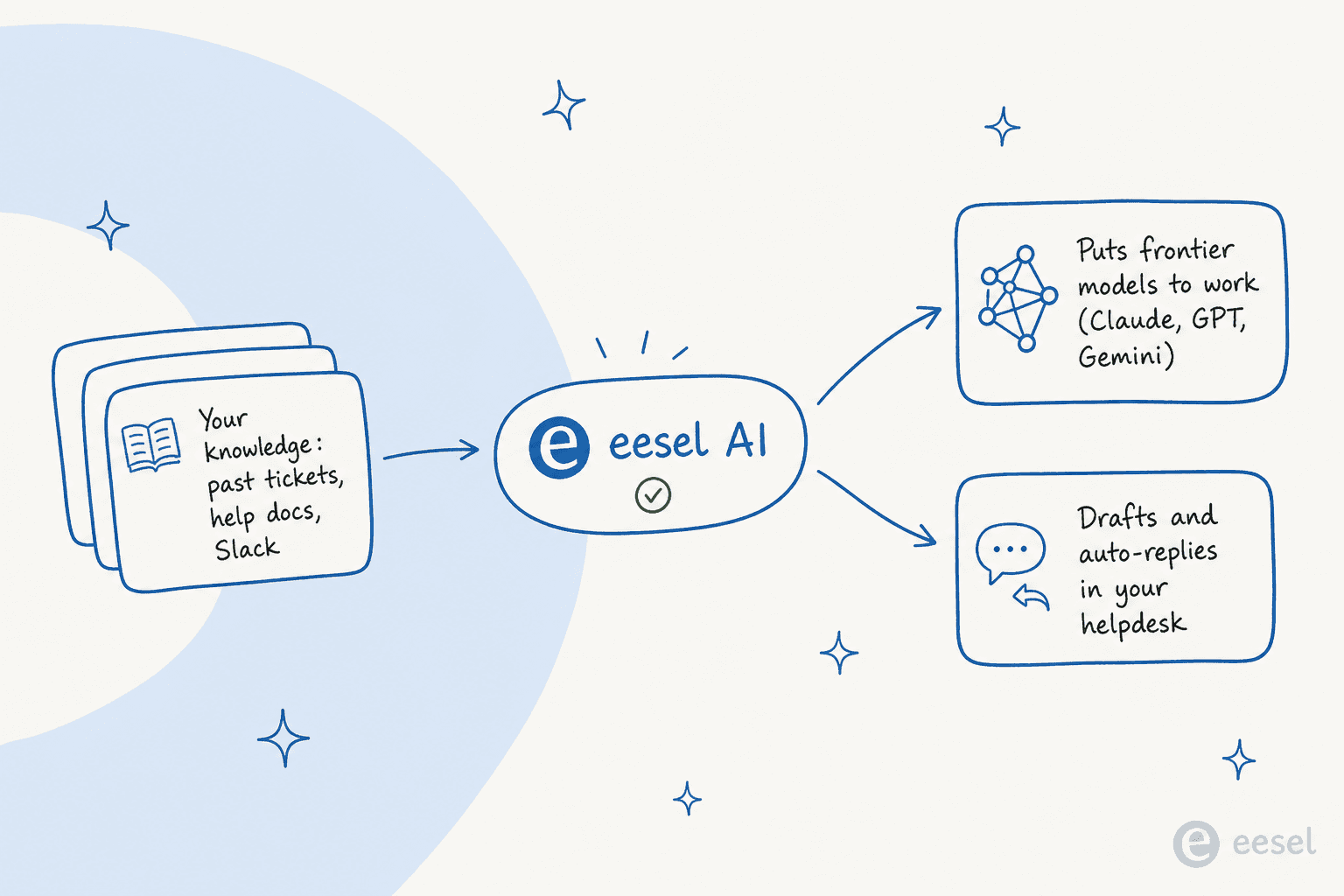
If the reason you were comparing Opus alternatives is that you want AI to handle real support or internal questions, eesel AI is built for exactly that, and it sidesteps the whole "which model" debate. eesel is a model-agnostic layer that sits on top of the frontier LLMs and puts them to work over your own knowledge, so you never have to bet your stack on a single model that might fall behind.
{kind=link}
It connects to your existing helpdesk and integrations (Zendesk, Freshdesk, HubSpot, Gorgias, Slack, Confluence, and more), learns from your past resolved tickets and help content on day one, and drafts or auto-resolves replies with confidence-based routing so low-confidence answers draft rather than send. The differentiator we'd point to: a simulation mode that replays thousands of your historical tickets to show your real coverage and resolution rate before you ever go live. In practice that has meant 73% tier-one resolution in month one for one customer and over 100,000 tickets a month handled for another.
{kind=link}
If that's closer to what you actually need than a raw model swap, you can try eesel and run the simulation on your own tickets. And if you do want to keep comparing models, our best AI helpdesk software and Claude alternatives guides are good next reads.
Frequently Asked Questions
{kind=link}
Share this article
{kind=link}
Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}