 |
VOOZH | about |
|
VOOZH | about |
In this article, we are going to see the concept of Data Preprocessing, Analysis, and Visualization for building a Machine learning model. Business owners and organizations use Machine Learning models to predict their Business growth. But before applying machine learning models, the dataset needs to be preprocessed.
So, let's import the data and start exploring it.
We will be using these libraries :
Now let us observe the dataset.
Output :
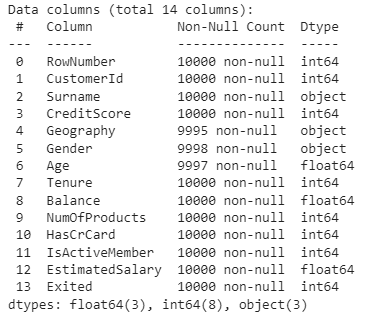
Info() function retrieves the information about the dataset such as data type, number of rows and columns, etc.
Output :
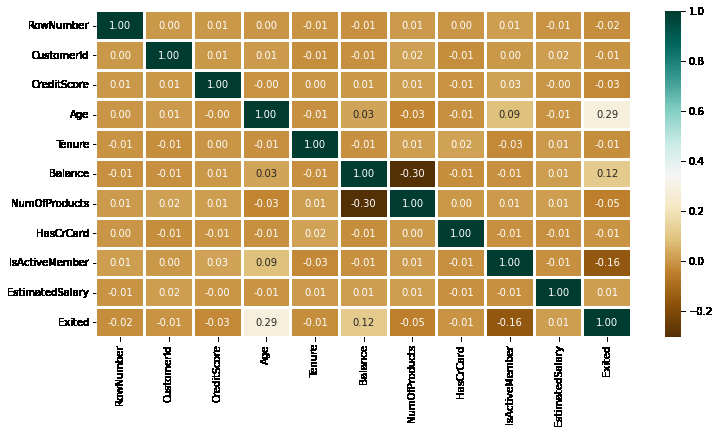
To find out the correlation between the features, Let's make the heatmap.
Output :
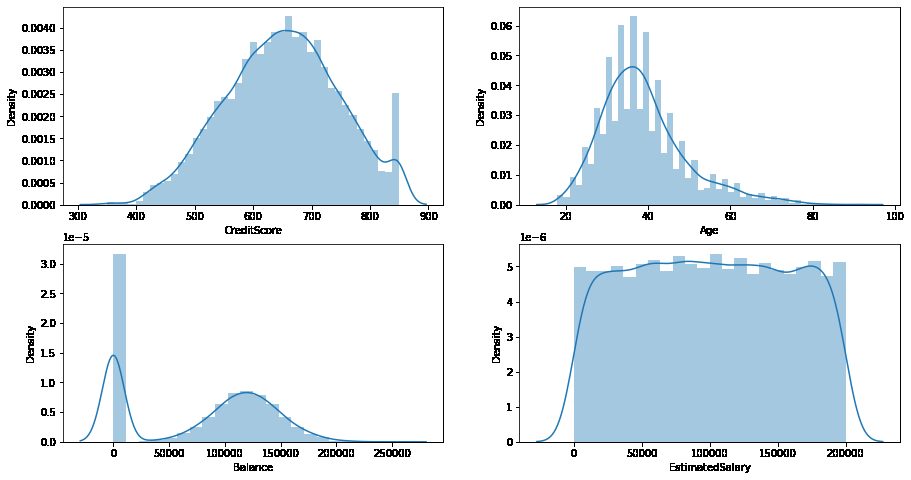
Now we can also explore the distribution of CreditScore, Age, Balance, ExtimatedSalary using displot.
Output :
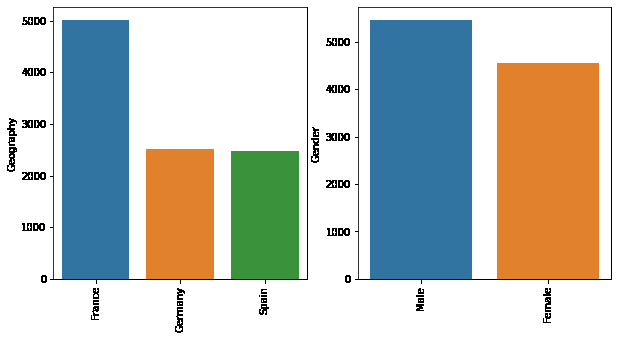
We can also check the categorical count of each category in Geography and Gender.
Output :
Data preprocessing is used to convert raw data into a clear format. Raw data consist of missing values, noisy data, and raw data may be text, image, numeric values, etc.
By the above definition, we understood that transforming unstructured data into a structured form is called data preprocessing. If the unstructured data is used in machine learning models to analyze or to predict, the prediction will be false because unstructured data contains missing values and unwanted data. So for good prediction, the data need to be preprocessed.
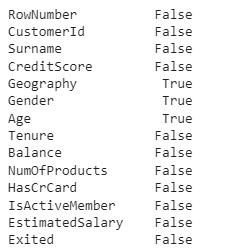
Let's observe whether null values are present.
Output :
Here, True indicates a null value and False indicates there is no null value. We can observe that there are 3 columns containing null values. The 3 columns are Geography, Gender, and Age. Now we need to remove the null values, to do this there are 3 ways they are:
In this scenario, we replace null values with Mean and Mode.
As we know Geography and Gender is a Categorical columns we used mode and Age is an integer type so we used mean.
Note: By using “Inplace = True”, the original data set is modified.
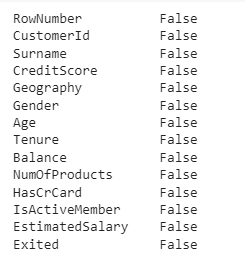
Now once again let us check if any null values still exist.
Label Encoding is used to convert textual data to integer data. As we know there are two textual data type columns which are “Geography” and “Gender”.
First we initialized LabelEncoder() function, then transformed textual data to integer data with fit_transform() function.
So now, the “Geography” and “Gender” columns are converted to integer data types.
Dataset is split into x and y variables and converted to an array.
Here x is the independent variable and y is the dependent variable.
Here we split data into train and test sets.
Feature Scaling is a technique done to normalize the independent variables.
We have successfully preprocessed the dataset. And now we are ready to apply Machine Learning models.
As this is a Classification problem then we will be using the below models for training the data.
And for evaluation, we will be using Accuracy Score.
Output :
Accuracy score of RandomForestClassifier = 84.5 Accuracy score of KNeighborsClassifier = 82.5 Accuracy score of SVC = 86.15 Accuracy score of LogisticRegression = 80.75
Random Forest classifier and SVC are showing the best results with an accuracy of around 85%
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}