Data preprocessing is the first step in any data analysis or machine learning pipeline. It involves cleaning, transforming and organizing raw data to ensure it is accurate, consistent and ready for modeling. It has a big impact on model building such as:
Clean and well-structured data allows models to learn meaningful patterns rather than noise. Properly processed data prevents misleading inputs, leading to more reliable predictions. Organized data makes it simpler to create useful inputs for the model, enhancing model performance. Organized data supports better Exploratory Data Analysis (EDA), making patterns and trends more interpretable. 👁 data_cleaning Data Preprocessing Steps-by-Step implementation Let's implement various preprocessing features,
Step 1: Import Libraries and Load Dataset We prepare the environment with libraries like pandas , numpy , scikit learn , matplotlib and seaborn for data manipulation, numerical operations, visualization and scaling. Load the dataset for preprocessing.
The sample dataset can be downloaded from here .
Output:
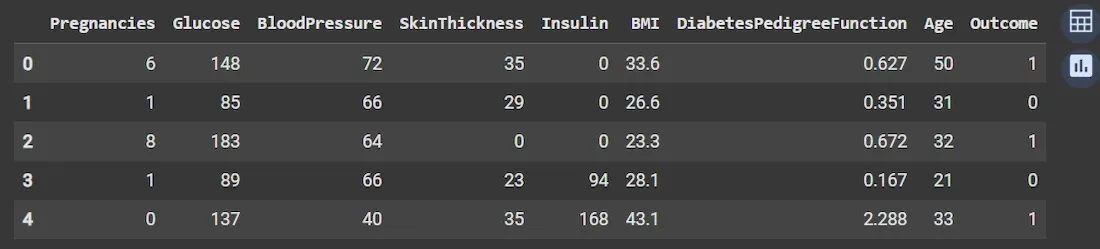
👁 Screenshot-2025-08-29-132400 Dataset Step 2: Inspect Data Structure and Check Missing Values We understand dataset size, data types and identify any incomplete (missing) data that needs handling.
df.info(): Prints concise summary including count of non-null entries and data type of each column. df.isnull().sum(): Returns the number of missing values per column. Output:
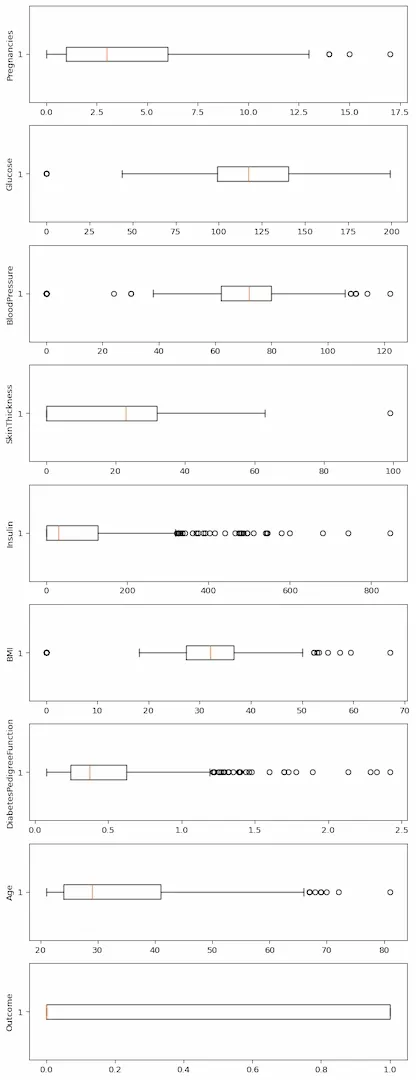
Step 3: Statistical Summary and Visualizing Outliers Get numeric summaries like mean, median, min/max and detect unusual points (outliers). Outliers can skew models if not handled.
df.describe(): Computes count, mean, std deviation, min/max and quartiles for numerical columns. Boxplots: Visualize spread and detect outliers using matplotlib’s boxplot(). Output:
👁 boxplot-data-preprocessing Boxplot Step 4: Remove Outliers Using the Interquartile Range (IQR) Method Remove extreme values beyond a reasonable range to improve model robustness.
IQR = Q3 (75th percentile) – Q1 (25th percentile). Values below Q1 - 1.5IQR or above Q3 + 1.5IQR are outliers. Calculate lower and upper bounds for each column separately. Filter data points to keep only those within bounds. Note: In practice, outlier removal should be applied across all relevant numerical columns to ensure consistent preprocessing.
Step 5: Correlation Analysis Understand relationships between features and the target variable (Outcome). Correlation helps gauge feature importance.
df.corr(): Computes pairwise correlation coefficients between columns. Heatmap via seaborn visualizes correlation matrix clearly. Sorting correlations with corr['Outcome'].sort_values() highlights features most correlated with the target. Output:
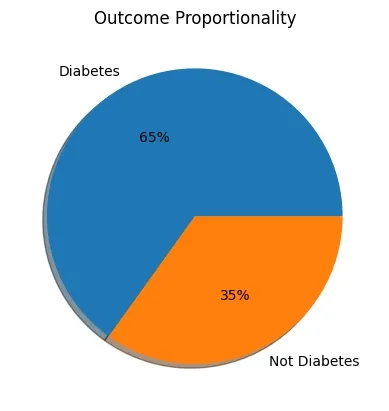
Step 6: Visualize Target Variable Distribution Check if target classes (Diabetes vs Not Diabetes) are balanced, affecting model training and evaluation.
plt.pie(): Pie chart to display proportion of each class in the target variable 'Outcome'. Output:
👁 pie Result Step 7: Separate Features and Target Variable Prepare independent variables (features) and dependent variable (target) separately for modeling.
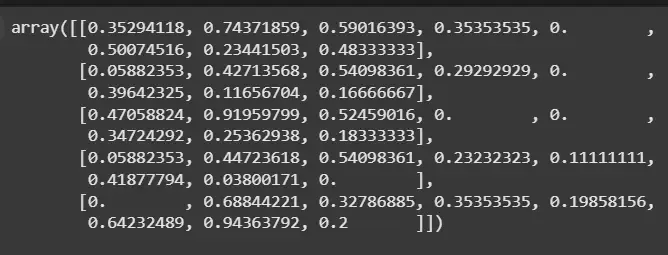
df.drop(columns=[...]): Drops the target column from features. Direct column selection df['Outcome'] selects target column. Step 8: Feature Scaling: Normalization and Standardization Scale features to a common range or distribution, important for many ML algorithms sensitive to feature magnitudes.
1. Normalization (Min-Max Scaling): Rescales features between 0 and 1. Good for algorithms like k-NN and neural networks.
Class: MinMaxScaler from sklearn. .fit_transform(): Learns min/max from data and applies scaling. Output:
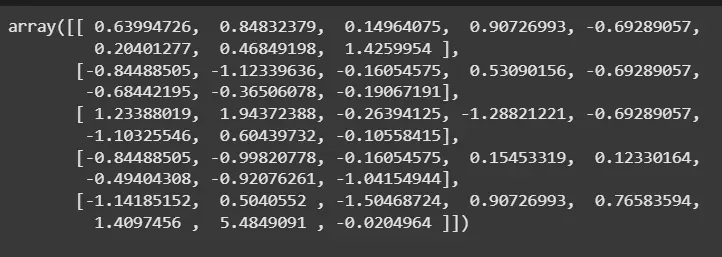
👁 Screenshot-2025-08-29-132258 Normalization 2. Standardization: Transforms features to have mean = 0 and standard deviation = 1, useful for normally distributed features.
Class: StandardScaler from sklearn. Output:
👁 Screenshot-2025-08-29-132251 Standardization Advantages Cleans and organizes raw data for better analysis. Removes noise and irrelevant data, leading to more precise predictions. Handles outliers and redundant features, which reduces overfitting. Scaling data helps models train faster by reducing computation time. Converts data into formats suitable for machine learning models. 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}