 |
VOOZH | about |
|
VOOZH | about |
Retrieval-Augmented Generation (RAG) is a framework that combines the strengths of information retrieval and generative models:
It allows a model to retrieve relevant documents from a knowledge base and use those documents to augment the generation process, resulting in more accurate, context-aware and insightful responses. This approach has shown promising results in various applications such as question answering, dialogue systems and content generation. In this article we will build a RAG Application.
Before building the model lets see how RAG Works in customer-support Help Bot:
Lets build a Amazon Help Bot which can answer to the queries of customers.
Install required libraries for generating embeddings, similarity search, text generation and deep learning by running the following command.
sentence-transformers: Used for generating sentence embeddings which are vector representations of text for similarity comparison.faiss-cpu: A library for efficient similarity search, used to index and search document embeddings based on cosine similarity.transformers: A library for accessing pre-trained models such as FLAN-T5, for text generation and other NLP tasks.torch: A deep learning framework used to run models and perform tensor computations necessary for NLP tasks.A list of documents i.e knowledge base will be used to retrieve relevant context for answering customer queries. The documents might include return policies, troubleshooting guides and FAQs.
We will use SentenceTransformer to generate vector embeddings for the documents which represent each document numerically for similarity comparison.
Create a FAISS index for performing efficient similarity searches using the document embeddings and normalizes the embeddings for cosine similarity.
Loads the FLAN-T5 model and tokenizer from Hugging Face for generating text-based responses based on input prompts.
Output:
Retrieves the top-k most relevant documents for the query, generates a prompt and uses FLAN-T5 to generate a response based on the retrieved context.
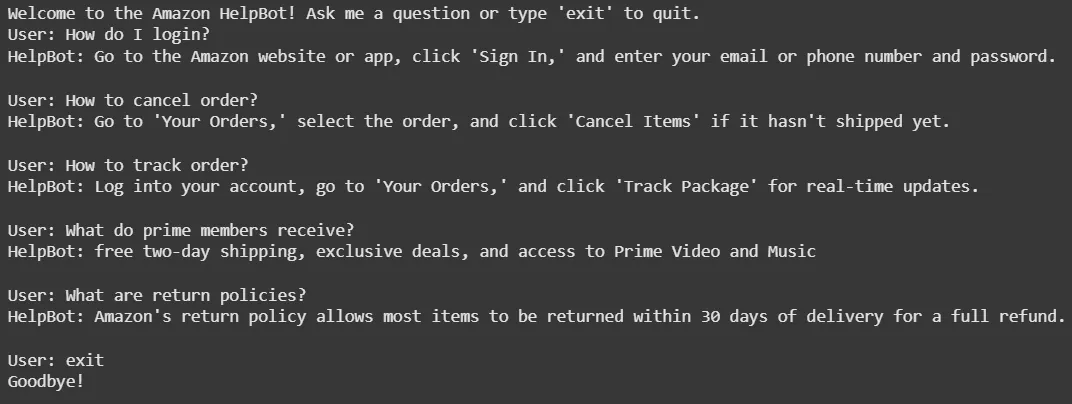
Continuously takes user input, processes the query using the rag_answer function and displays the relevant context and generated response. Ends when the user types 'exit'.
Output:
{kind=link}
{kind=link}
{kind=link}