Factor Analysis is a statistical technique used in data analysis to identify hidden patterns or underlying relationships among a large set of variables. It helps reduce data complexity by grouping correlated variables into smaller sets called factors which represent shared characteristics or dimensions within the data.
Factor analysis serves several purposes and objectives in statistical analysis:
Dimensionality Reduction: Simplifies datasets by grouping correlated variables into fewer factors making data easier to interpret.
Identifying Latent Constructs: Reveals hidden variables like traits, attitudes that explain observed patterns.
Data Summarization: Summarizes many variables into a concise set of factors while retaining key information.
Hypothesis Testing: Evaluates whether the data support expected relationships among variables.
Variable Selection: Highlights the most relevant variables for analysis or modelling.
Improving Models: Reduces multicollinearity and enhances predictive model performance.
Commonly Used Terms in Factor Analysis
Most commonly used terms in factor analysis are:
Factors: Hidden variable that explains patterns among observed variables.
Factor Loading: Strength of the relationship between a variable and a factor.
Eigenvalue: Amount of variance explained by each factor.
Communalities: Explains how much of a variable’s variance is explained by the extracted factors.
Rotation: Technique to make factors more interpretable like Varimax.
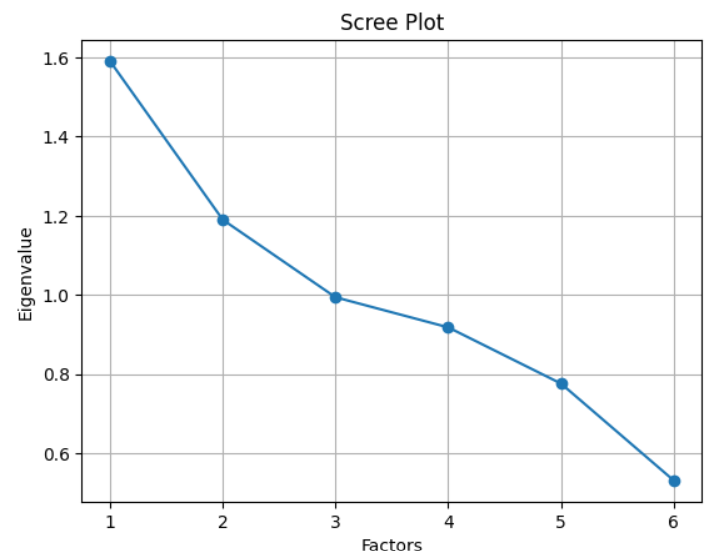
Scree Plot: A plot used to determine the number of factors to retain based on the magnitude of eigenvalues.
Kaiser-Meyer-Olkin (KMO) Measure: It checks if your data is suitable for factor analysis, values closer to 1 mean the data is a good fit.
Types of Factor Analysis
There are two main types of Factor Analysis used during Data Analysis:
1. Exploratory Factor Analysis (EFA)
Identifies underlying structure without prior assumptions.
Groups correlated variables into factors organically.
Helps determine the number of factors needed.
Used when relationships among variables are unknown.
2. Confirmatory Factor Analysis (CFA)
Tests specific, theory driven hypotheses about variable factor relationships.
Uses structural equation modeling to check model fit.
Accounts for measurement error.
Used when factor structure is already hypothesized.
Types of Factor Extraction Methods
Some of the types of Factor Extraction methods are:
1. Principal Component Analysis (PCA)
Principal Component Analysis aims to extract factors that account for the maximum possible variance in the observed variables.
Factor weights are computed to extract successive factors until no further meaningful variance can be extracted.
After extraction, the factor model is often rotated for further analysis to enhance interpretability.
2. Canonical Factor Analysis
Also known as Rao's canonical factoring, this method computes a similar model to PCA but uses the principal axis method.
Seeks factors that have the highest canonical correlation with the observed variables.
Canonical factor analysis is not affected by arbitrary rescaling of the data making it robust to certain data transformations.
3. Common Factor Analysis
It's also referred to as Principal Factor Analysis (PFA) or Principal Axis Factoring (PAF).
This method aims to identify the fewest factors necessary to account for the variance among a set of variables.
Unlike PCA, common factor analysis focuses on capturing shared variance rather than overall variance.
Assumptions of Factor Analysis
Some of the assumptions of factorial analysis are as follows:
Linearity: The relationships between variables and factors are assumed to be linear.
Multivariate Normality: The variables in the dataset should follow a multivariate normal distribution.
No Multicollinearity: Variables should not be highly correlated with each other as high multicollinearity can affect the stability and reliability of the factor analysis results.
Homoscedasticity: The variance of the variables should be roughly equal across different levels of the factors.
Independent Observations: The observations in the dataset should be independent of each other.
Linearity of Factor Scores: The relationship between the observed variables and the latent factors is assumed to be linear even though the observed variables may not be linearly related to each other.
Working of Factor Analysis
Here are the general steps involved in conducting a factor analysis:
1. Determine the Suitability of Data for Factor Analysis
Bartlett's Test: Check the significance level to determine if the correlation matrix is suitable for factor analysis.
Kaiser Meyer Olkin (KMO) Measure: Verify the sampling adequacy. A value greater than 0.6 is generally considered acceptable.
2. Choose the Extraction Method
Principal Component Analysis (PCA): Used when the main goal is data reduction.
Principal Axis Factoring (PAF): Used when the main goal is to identify underlying factors.
3. Factor Extraction
Use the chosen extraction method to identify the initial factors.
Extract eigenvalues to determine the number of factors to retain. Factors with eigenvalues greater than 1 are typically retained in the analysis.
Compute the initial factor loadings.
4. Determine the Number of Factors to Retain
Scree Plot: Plot the eigenvalues in descending order to visualize the point where the plot levels off the "elbow" to determine the number of factors to retain.
Eigenvalues: Retain factors with eigenvalues greater than 1.
5. Factor Rotation
Orthogonal Rotation (Varimax, Quartimax): Assumes that the factors are uncorrelated.
Oblique Rotation (Promax, Oblimin): Allows the factors to be correlated.
Rotate the factors to achieve a simpler and more interpretable factor structure.
Examine the rotated factor loadings.
6. Interpret and Label the Factors
Analyze the rotated factor loadings to interpret the underlying meaning of each factor.
Assign meaningful labels to each factor based on the variables with high loadings on that factor.
7. Compute Factor Scores (if needed)
Calculate the factor scores for each individual to represent their value on each factor.
8. Report and Validate the Results
Report the final factor structure including factor loadings and communalities.
Validate the results using additional data or by conducting a confirmatory factor analysis if necessary.
Implementation of Factor Analysis
Here's step by step implementation of factor analysis in Python using the factor_analyzer library:

{kind=link}
{kind=link}
{kind=link}