Adversarial attacks target small weaknesses in generative models by crafting misleading inputs that alter responses, generate unauthorized content or bypass safety layers. Understanding these attack patterns helps improve robustness and safety across applications.
Adversarial defense methods are important for protecting model outputs from manipulation and preventing misuse in production environments.
Some of the reasons adversarial defenses are required in Generative AI are:
Safety Assurance: Attackers may force the model to produce harmful or restricted information.
Protecting Sensitive Data: Without protection, models can unintentionally reveal internal prompts or private knowledge.
Model Reliability: Adversarial inputs can degrade output quality and trustworthiness.
Regulatory Compliance: Strong defenses help organizations meet safety and privacy standards.
Preventing Misuse: Defense prevents malicious users from misusing generative capabilities.
Attack Vectors
Attack vectors refer to the different ways or entry points an attacker can use to exploit weaknesses in a system. Common adversarial attack vectors are:
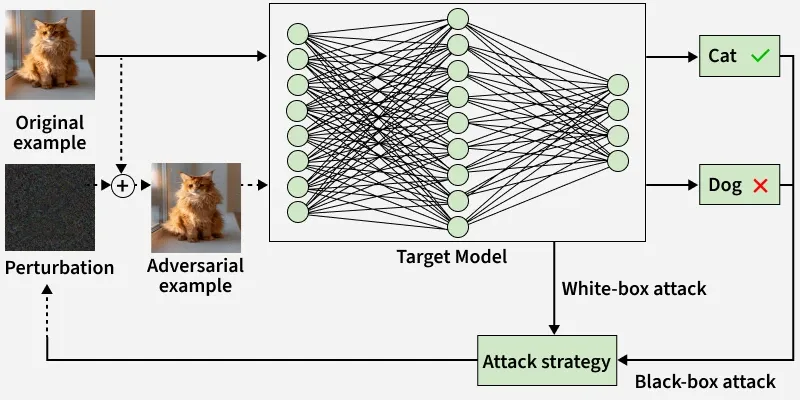
White-Box Attacks: The attacker knows the model internals like architecture, weights, training data and crafts precise adversarial inputs using that full access.
Black-Box Attacks: The attacker has only input–output access and probes the system repeatedly to discover inputs that cause failures, without seeing internal parameters.
Transfer Attacks: Adversarial examples generated against one model are reused to fool another similar model, exploiting shared vulnerabilities across architectures.
Physical Attacks: Manipulations occur in the real world like stickers on signs, printed perturbations to cause sensors or perception models to misinterpret physical scenes.
Attack Strategies
Adversarial attack strategies describing what attackers does are:
Prompt Injection: Embeds hidden instructions in user queries to override built-in safety rules. This approach is simple but effective at manipulating text responses.
Gradient-Based Perturbations: Uses subtle modifications in input embeddings to force incorrect outputs. It exploits weaknesses in model optimization layers.
Poisoned Training Data: Introduces corrupted samples into the dataset to shift model behavior. This can target classifications or response tone.
Prompt Obfuscation: Rearranges characters or uses unusual formatting to bypass keyword filters. This method often slips past basic rule-based checks.
Role Confusion Attacks: Tricks the model into revealing system instructions by pretending to be a higher-priority persona.
Defense Mechanisms
Defense mechanisms are the techniques used to identify, filter and block adversarial inputs before they can manipulate a generative model. Some of the defense mechanisms are:
Input Sanitization: Normalizes user queries to remove strange patterns and hidden instructions.
Multi-Layer Moderation: Uses several filters before and after generation for extra safety.
Behavioral Guardrails: Adds explicit constraints that reinforce safety policies.
Adversarial Training: Teaches the model how to identify manipulated or malicious input patterns.
Dynamic Rule Updating: Continually refreshes safety rules based on newly discovered exploits.
Selecting Defense Approaches
Defensive configurations for Generative AI are:
Static Filters: Useful for quick checks against harmful keywords.
Embedding Comparison: Ideal for detecting semantic manipulation at deeper levels.
Policy-Driven Models: Prioritize ethical and compliant behavior in sensitive domains.
User Behavior Tracking: Flags suspicious repetition or poking activity.
Fine-Grained Logging: Helps trace attack vectors during audits.
Larger defense stacks improve safety but may increase latency. Smaller minimal stacks are faster but risk weaker robustness.
Applications
Some of the applications of adversarial defenses in Generative AI are:
Secure Chatbots: Shields conversational agents from manipulation attempts, preventing unauthorized instructions from being injected into the conversation flow.
Content Filtering Systems: Blocks highly targeted prompts designed to produce unsafe content by screening contextual intent and keyword patterns.
Data Privacy Tools: Protects internal training prompts and sensitive embeddings from extraction attacks that attempt to reveal internal model knowledge.
Regulatory Platforms: Assists compliance with AI safety and governance frameworks by enforcing standardized moderation policies across deployments.
Enterprise Assistants: Prevents accidental exposure of confidential documents in corporate environments where users frequently interact with internal resources.
Benefits
Some of the benefits of adversarial defense methods are:
Higher Trustworthiness: Helps the system provide safer and more reliable responses, increasing user confidence during interactions.
Robust Risk Reduction: Blocks unauthorized access to sensitive instructions, reducing malicious use in real-time applications.
Improved Stability: Minimizes unexpected response deviation by filtering adversarial perturbations or misleading prompts.
Domain Flexibility: Adaptable across text, image and audio pipelines, making defenses useful in multimodal generative systems.
Ongoing Adaptation: Defense rules evolve with new threat patterns, enabling continuous improvement against emerging exploit techniques.
Limitations
Some of the limitations of adversarial defenses are:
Evolving Threats: Attackers innovate faster than static defenses can update, requiring continuous monitoring and patching.
False Positives: Strict filters may block legitimate queries, frustrating users and reducing system usability in sensitive tasks.
Resource Overhead: Multi-layer filtering increases latency and cost, especially in large-scale deployments handling constant traffic.
Model Complexity: Configuring effective defenses requires domain expertise, making it challenging for smaller teams without specialized knowledge.

{kind=link}
{kind=link}