Conversation Buffer Window Memory in LangChain stores only the most recent exchanges in a conversation instead of the full dialogue history. It functions like a sliding window that holds a fixed number of turns ensuring the language model has the most relevant context for generating responses.
This approach helps chatbots and assistants stay focused, prevents token overload and keeps interactions efficient. It is especially useful for short to medium conversations where only the latest context is important while older messages can be safely discarded.
Architecture
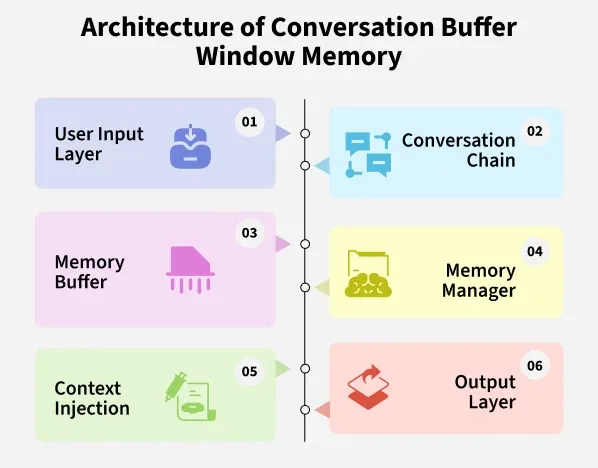
Architecture Overview of Conversation Buffer Window Memory in LangChain:
User Input Layer: The system captures the user’s query or message.
Conversation Chain: The user input is passed to the conversational chain or language model.
Memory Buffer: Stores the last k user LLM exchanges as a rolling window. Older messages are discarded once the limit is reached.
Memory Manager: Handles saving new interactions with save_context() and retrieving recent context with load_memory_variables().
Context Injection: The preserved messages are added to the LLM prompt so it can generate responses with awareness of recent history.
Output Layer: The LLM generates a reply which is both returned to the user and saved back into the memory buffer for the next turn.
How Does it Work
Here’s the workflow of Conversation Buffer Window Memory in LangChain:
Initialization: The memory is initialized with a window size k which defines how many past exchanges to retain.
Saving Context: After each user input and AI response, the save_context() method stores the new exchange in the buffer.
Sliding Window Mechanism: The new exchange is added to the buffer. If the buffer exceeds k exchanges, the oldest ones are automatically discarded.
Loading History: Before generating the next response, the load_memory_variables() method retrieves the current buffer and provides it as conversation history to the LLM.
Continuous Update: This cycle repeats at every turn ensuring only the latest k exchanges are kept for efficient and context aware responses.
Implementation
Steps to implement Conversation Buffer Window Memory in Langchain are:
Step 1: Install Dependencies
Installing LangChain core, OpenAI integration, FAISS for vector storage, dotenv for env vars and community modules.
Step 2: Import Libraries
Importing LangChain modules and Operating System.
Step 3: Environment Setup
Setting up environment using OpenAI API Key, we can also use Gemini's API Key.

{kind=link}
{kind=link}
{kind=link}
{kind=link}