 |
VOOZH | about |
|
VOOZH | about |
GPT-5.4 is a frontier large language model released by OpenAI, designed for complex professional work such as coding, research, automation, document processing and agent-based workflows. It is optimized for real-world tasks that require working with spreadsheets, presentations, documents, software tools and long workflows.
Key characteristics of GPT-5.4 include:
The GPT model family has evolved gradually with each version improving reasoning, coding, and tool interaction capabilities.
| Model | Key Focus | Major Improvement |
|---|---|---|
| GPT-4 | Multimodal reasoning | Image + text understanding |
| GPT-5.1 | Faster general model | Improved latency |
| GPT-5.2 | Reasoning model | Better multi-step reasoning |
| GPT-5.3-Codex | Coding-focused model | Strong software engineering ability |
| GPT-5.4 | Unified frontier model | Combines reasoning, coding, and agents |
GPT-5.4 merges the best parts of GPT-5.2 reasoning and GPT-5.3-Codex coding capabilities.
Context window refers to the amount of text the model can process in a single request. GPT-5.4 introduces one of the largest context windows available in frontier AI models.
| Model | Context Window | Notes |
|---|---|---|
| GPT-5.2 | 272K tokens | Standard reasoning model |
| GPT-5.3-Codex | ~272K tokens | Coding optimized |
| GPT-5.4 | 1M tokens (experimental) | Enables long workflows and large documents |
Large context windows allow the model to process:
GPT-5.4 Thinking can present an initial plan before generating the final answer. Users can modify this plan mid-response.
GPT-5.4 shows major improvements in professional tasks such as:
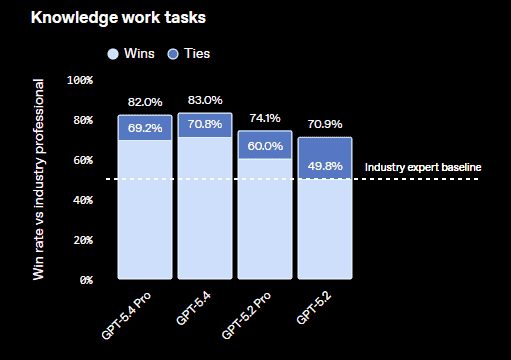
On the GDPval benchmark, which evaluates tasks across 44 occupations, GPT-5.4 achieved the highest performance.
This benchmark measures how well models perform professional knowledge tasks across industries.
GPT-5.4 significantly improves performance on real business tasks.
These improvements make GPT-5.4 suitable for professional workflows involving:
GPT-5.4 improves factual accuracy. Compared to GPT-5.2:
This improvement increases reliability for professional work.
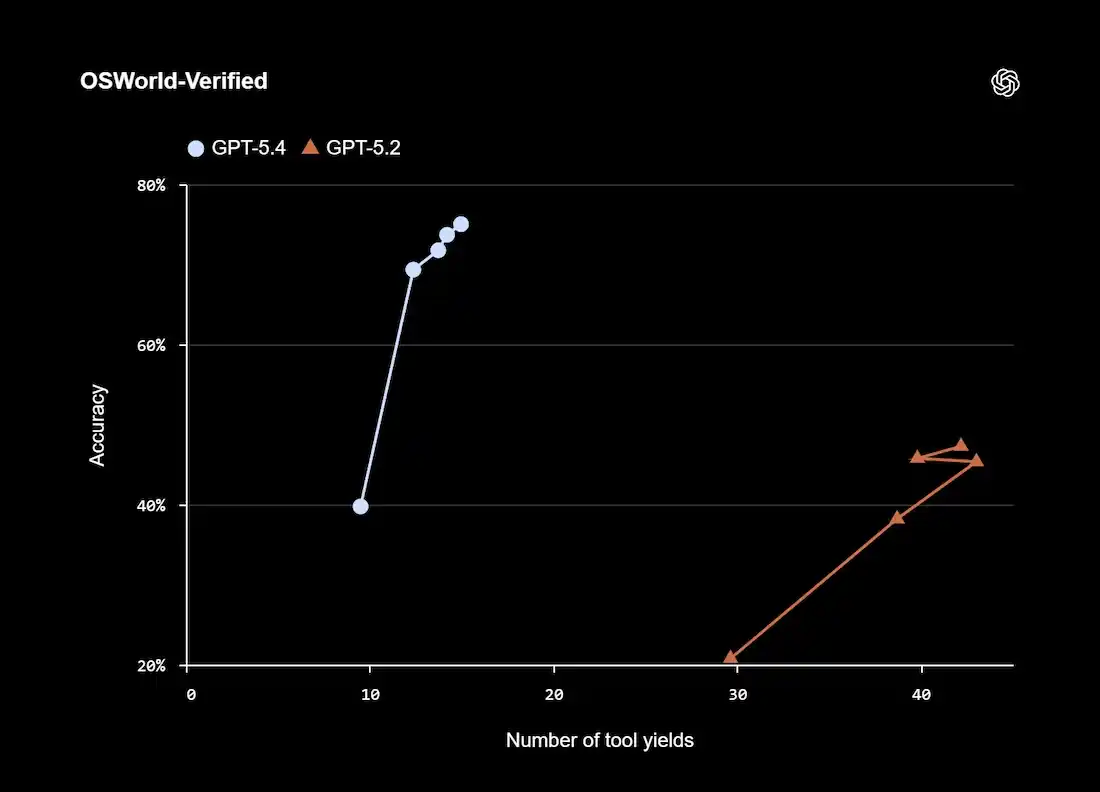
GPT-5.4 introduces native computer interaction capabilities, allowing agents to perform tasks directly on software interfaces. Capabilities include:
This enables automation of tasks such as:
Performance improvements are measured using the OSWorld-Verified benchmark, which evaluates the ability to operate computers.
GPT-5.4 surpasses human performance in this benchmark.
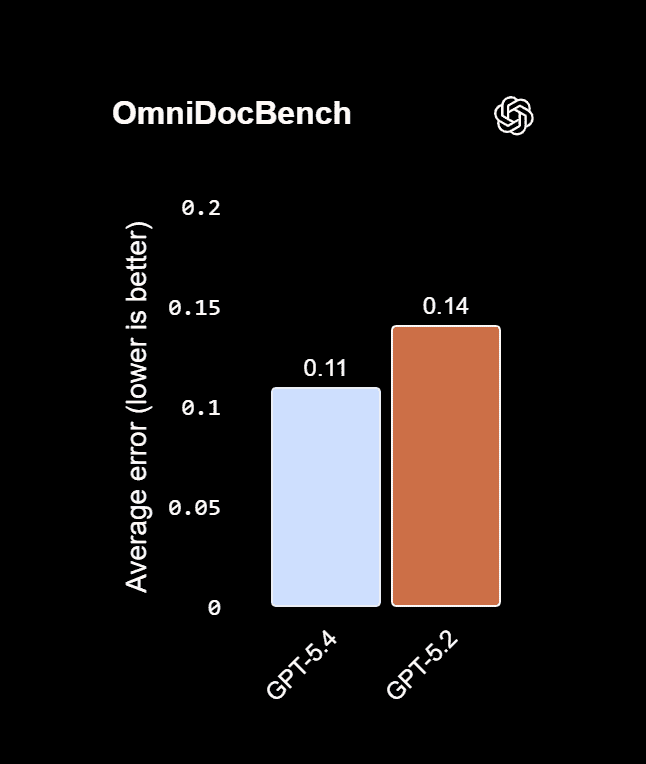
GPT-5.4 improves visual perception and document understanding. Example benchmarks:
The model also supports high-resolution image inputs. Image limits:
This improves tasks such as:
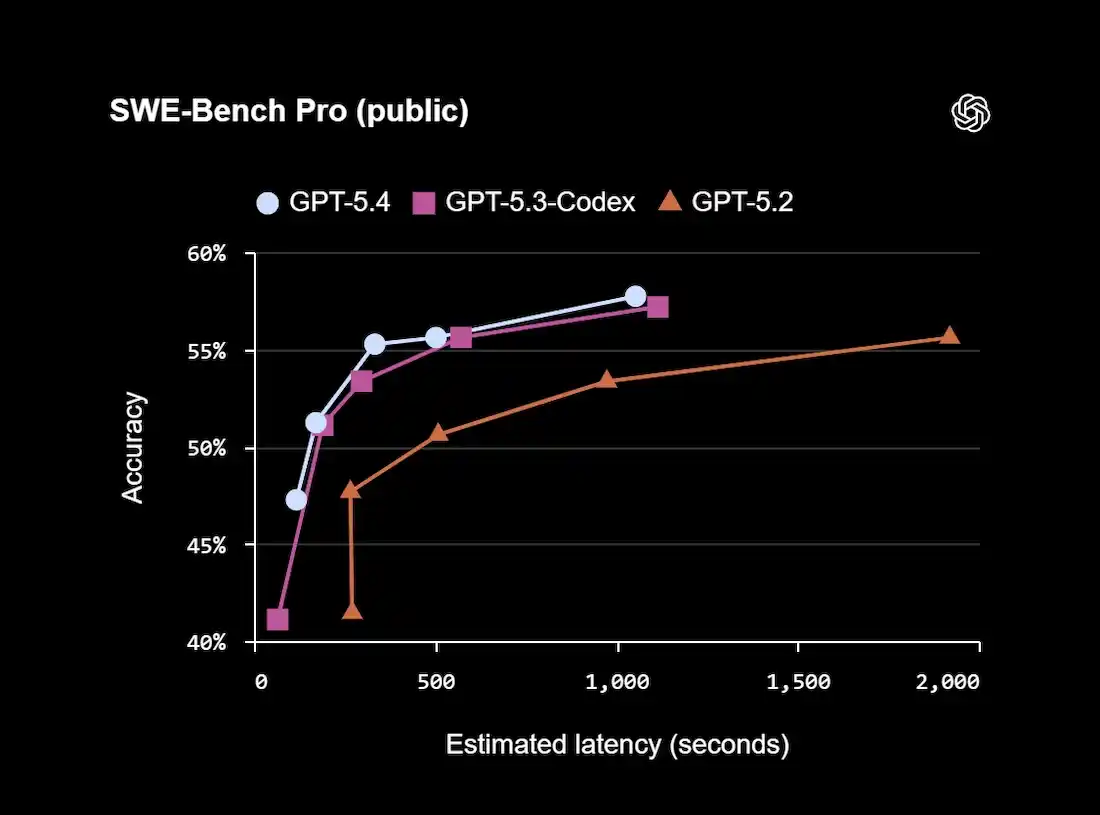
GPT-5.4 integrates the coding strengths of GPT-5.3-Codex. Key improvements include:
Benchmark comparison:
GPT-5.4 also performs well on Terminal-Bench 2.0, scoring 75.1%.
GPT-5.4 improves how models interact with external tools and APIs.
Previously, all tool definitions had to be included in the prompt. GPT-5.4 introduces tool search, which allows the model to fetch tool definitions only when needed.
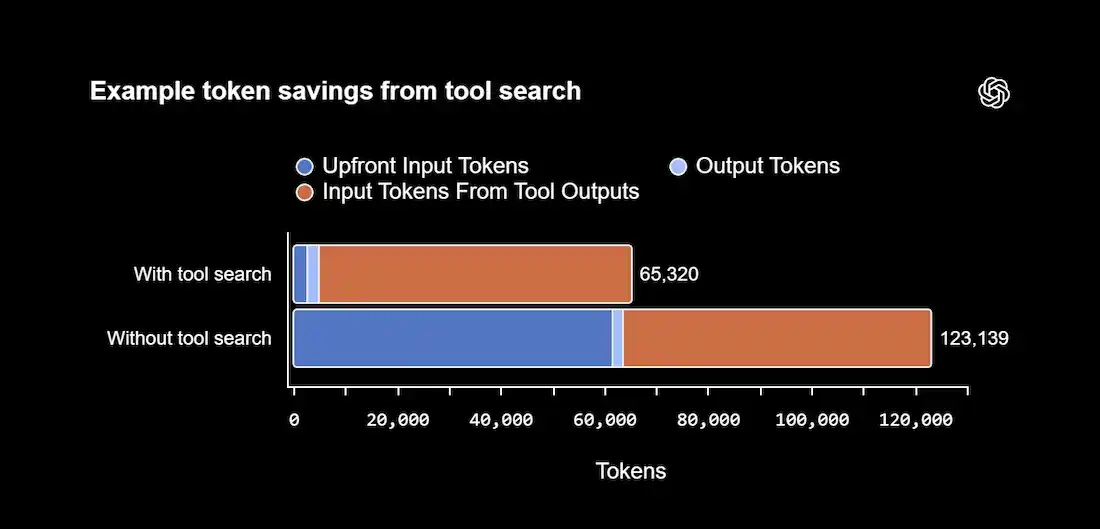
Example evaluation results:
This results in 47% token savings.
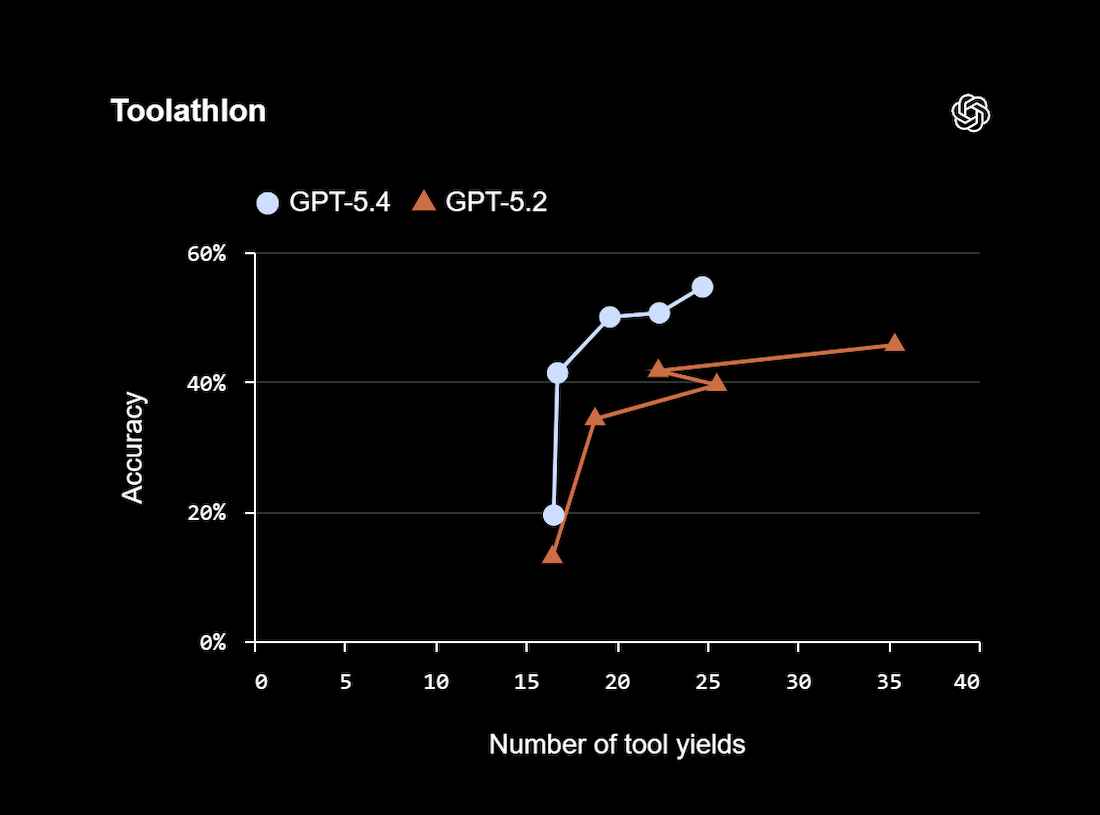
GPT-5.4 also improves decision making when choosing tools. Example benchmark:
Toolathlon measures how well AI agents use tools to complete multi-step tasks.
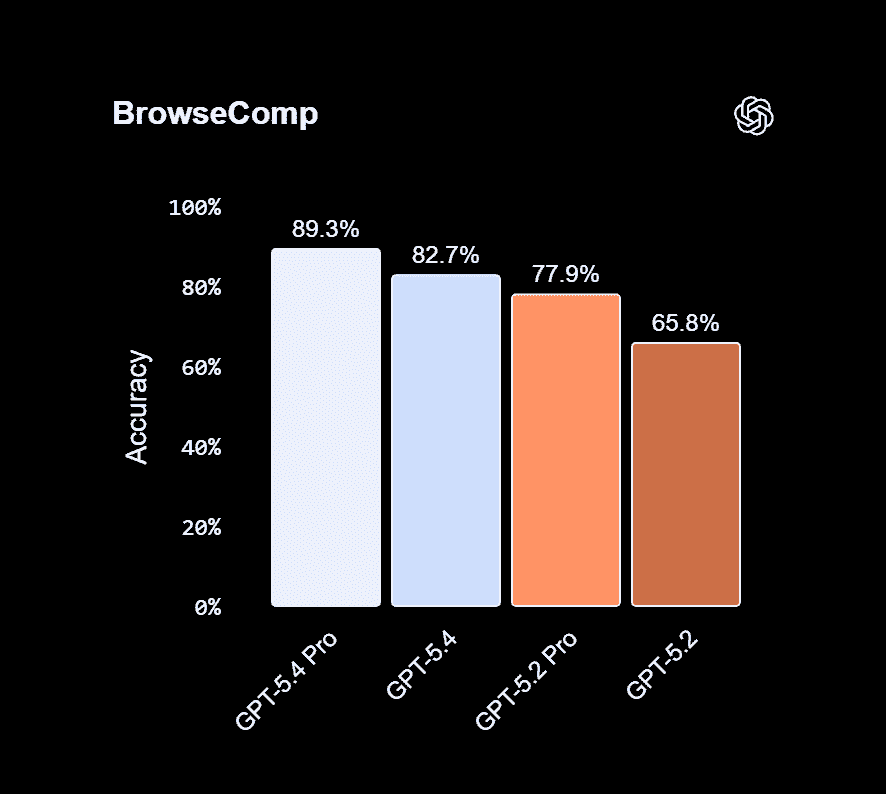
GPT-5.4 improves persistent web search capabilities. Benchmark:
This benchmark evaluates the ability to find difficult information across multiple web pages.
GPT-5.4 shows strong improvements on reasoning benchmarks.
| Benchmark | GPT-5.4 | GPT-5.2 |
|---|---|---|
| Frontier Science Research | 33.0% | 25.2% |
| FrontierMath Tier 1-3 | 47.6% | 40.7% |
| ARC-AGI-1 | 93.7% | 86.2% |
| ARC-AGI-2 | 73.3% | 52.9% |
These benchmarks measure advanced reasoning ability.
GPT-5.4 supports extremely long input contexts.
| Benchmark | GPT-5.4 |
|---|---|
| Graphwalks BFS (0-128K) | 93.0% |
| Graphwalks BFS (256K-1M) | 21.4% |
GPT-5.4 is classified under OpenAI’s High Cyber Capability category. Security measures include:
OpenAI also continues research on Chain-of-Thought monitoring to detect potential misuse.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}