Sampling techniques control how language models choose the next word during text generation. The model assigns probabilities to possible words and sampling determines which one is picked. By adjusting these methods, you can balance creativity and accuracy in generated responses.
Temperature controls randomness in predictions
Top-K limits choices to the most probable tokens
Top-P selects tokens based on cumulative probability
Used to tune output diversity and coherence
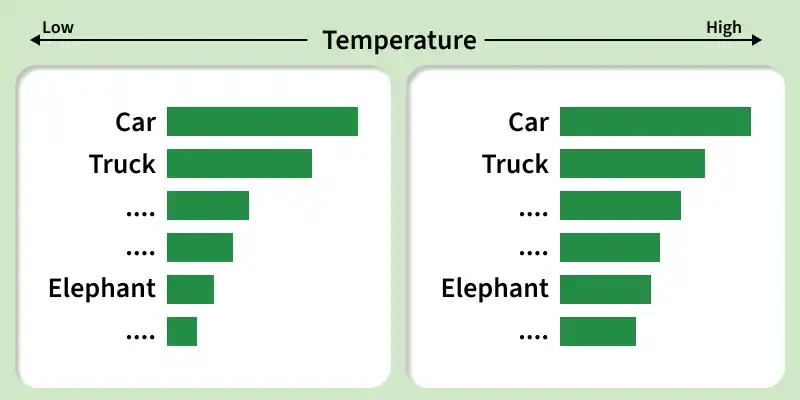
Temperature Sampling in LLMs
Temperature controls how random the model’s output is and typically ranges from 0 to 2
Low temperature one clear choice (car) and High temperature many possible choices
How it works
Before choosing the next word, the model adjusts word probabilities using the temperature setting
Low temperature:
Strongly favours high-probability words
Produces stable and predictable text
High temperature:
Flattens the probability distribution
Allows less likely words to appear more often
Increases creativity but may reduce accuracy
Example
Temperature = 0.2: factual, low creativity
Temperature = 1.0: balanced output
Temperature = 1.5: creative but less reliable
Implementation
Loads a pre-trained GPT-2 tokenizer and language model
Takes a text prompt and converts it into tokens
Generates text by predicting the next words step by step
Applies temperature (0.7) to control creativity and limits output length
Converts the output back to readable text and prints it
Output:
Explain AI in simple terms It's not too hard to learn to use artificial intelligence. The problem is that what you see here is not a single AI system. You'll see that the AI systems are different from the ones we've seen
Advantages
Allows control over the balance between accuracy and creativity
Produces reliable outputs when accuracy is needed
Encourages diverse ideas when creativity is preferred
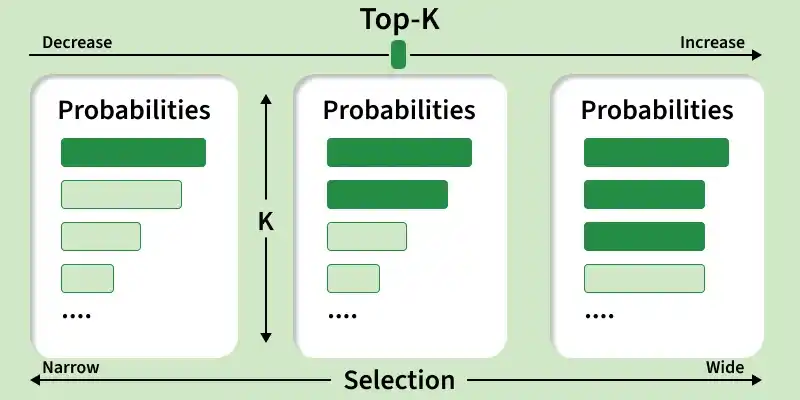
Top-K Sampling in LLMs
Top-K limits the model to choosing the next word from only the K most likely options, ignoring all other possibilities. This helps control randomness by keeping the selection focused on higher-probability words.
Only the top K tokens are considered; one is sampled from them.
How it works
The model ranks all possible next words by probability
Keeps only the top K most likely words
Randomly selects one word from this limited set
Example
Top K = 50: selects from the 50 most likely words
Smaller K: safer output
Larger K: more variety
Implementation:
Loads a pre-trained GPT-2 tokenizer and model
Converts the input text into tokens
Generates text by predicting the next words
Uses Top-K sampling (K = 50) to limit word choices and reduce unlikely outputs
Decodes and prints the generated text
Output:
Explain AI in simple terms. You may find yourself with the following problems. You have a basic understanding of your current behaviour. If you've tried it out, you'll find that when you go through the troubleshooting, every problem is
Advantages
Removes very unlikely words from consideration
Reduces strange or incorrect outputs
Helps produce cleaner and more reliable text
Top-P (Nucleus) Sampling in LLMs
Top P selects the next word based on cumulative probability instead of a fixed number of options, allowing the set of possible choices to grow or shrink depending on how confident the model is.

{kind=link}
{kind=link}
{kind=link}
{kind=link}