JEPA stands for Joint Embedding Predictive Architecture. It is a self-supervised learning framework designed to learn useful representations from data without relying on labeled examples. JEPA is particularly notable for its focus on learning abstract, high level representations that are robust and generalize well across tasks.
Core Principles
Predictive Learning : Instead of predicting missing or future parts of the data directly (like guessing missing pixels), JEPA learns to predict useful patterns or features in a more abstract, hidden representation called the embedding (latent) space. This makes learning more efficient and less focused on irrelevant details.
Joint Embedding : JEPA uses neural networks to convert both the visible part of the data (context) and the part it needs to predict (target) into the same shared space. This allows the model to "compare" the two in a meaningful way, helping it learn relationships and structure.
Abstraction : By operating in the embedding space, JEPA encourages the model to focus on abstract, semantic features rather than low level details, which is beneficial for understanding and performing tasks across different domains or datasets (transfer learning) and downstream tasks.
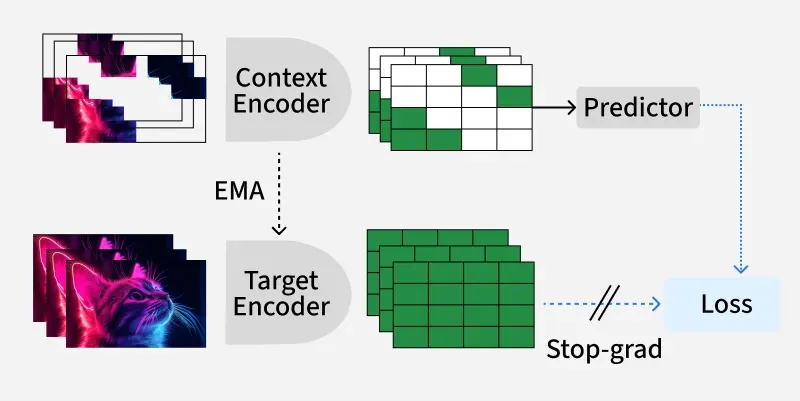
Context Encoder : Processes the observed part of the data (context) and produces a context embedding.
Target Encoder : Processes the part of the data to be predicted (target) and produces a target embedding.
Predictor (or Head) : Takes the context embedding and predicts the target embedding.
Loss Function : The model is trained to minimize the distance between the predicted target embedding and the actual target embedding (often using contrastive or regression losses).
Workflow / Steps
1. Input Preparation:
The input data (such as an image, video or text) is split into context and target parts.
For example, in images, some regions may be masked (targets) and the rest are used as context.
2. Encoding:
The context encoder processes the context to produce a context embedding.
The target encoder processes the target to produce a target embedding.
3. Prediction:
The predictor takes the context embedding and predicts what the target embedding should be.
4. Training Objective:
The loss function compares the predicted target embedding to the actual target embedding.
The model is optimized to minimize this loss, encouraging it to learn representations that capture the underlying structure of the data.
Mathematical Formulation
Let:
: Raw input data sample
: Context input (localized or partial view of data)
: Target input (another view or region of same data)
Step 1 : Encoders
Context Encoder : Maps context input to feature space
Target Encoder: Maps target input to feature space
are neural networks (transformers, convnets, etc.)
and are vector embeddings or feature representations, typically in
Step 2 : Predictor
JEPA includes a predictor function (often just a linear or MLP head):
where is the predicted embedding of the target and where learns to model the mapping from context-representation to target-representation
Step 3 : Loss Function
The goal of JEPA is to make close to A standard loss used is L2 loss (mean squared error):
Alternatively, contrastive losses (e.g., InfoNCE) can also be used:
Learns image representations by predicting masked patch embeddings from context patches.
S-JEPA
Skeleton / Action
Specialized for skeleton-based action recognition by predicting embeddings for skeleton data.
Point-JEPA
Point Cloud (3D Vision)
Designed for 3D point cloud data, predicts masked region embeddings for point-based tasks.
V-JEPA
Video
Learns representations across video frames by predicting abstract features of masked parts.
D-JEPA
Denoising / Multimodal
Focuses on denoising and generative tasks, operates across images, audio and video.
C-JEPA
Semantic Segmentation
Enhances performance on segmentation by predicting context aware representations.
SAR-JEPA
SAR Imaging
Joint-embedding predictive architecture for Synthetic Aperture Radar (SAR) ATR tasks.
Limitations of LLMs
Token-by-token generation: LLMs produce output sequentially with fixed computation per token, making them reactive and lacking true reasoning or planning capabilities.
Shallow world understanding: LLMs process only language, without capturing real-world context or forming genuine models of the physical world.
Limited reasoning: LLMs operate without deep reasoning or structured planning, essentially "speaking without thinking" and struggling with multi-step problem solving.
Inefficient scaling: Progress by merely making models larger and feeding more data is not sustainable or sufficient to achieve human-like intelligence.
How JEPA Addresses These Limitations
Representation space prediction (not token-level): JEPA predicts in abstract representation (embedding) space rather than generating literal outputs, allowing focus on essential information and supporting richer, less brittle world modeling.
World modeling: JEPA learns internal, abstract models of the environment, enabling understanding and simulation of physical or semantic context beyond language.
Integration of planning: Through explicit actor modules and latent variable modeling, JEPA supports both reactive and deliberate, planned reasoning addressing the lack of structured multi-step thinking in LLMs.
Energy-based framework: JEPA uses energy based models that capture deep dependencies between inputs and outputs, rather than simple sequence prediction, enhancing its ability to represent ambiguous or uncertain futures.
Handling uncertainty and multiple possibilities: Incorporating latent variables, JEPA naturally represents multiple plausible futures and manages prediction uncertainty, overcoming LLM 's limitations in dealing with ambiguous or multi-modal outcomes
Applications
1. Computer Vision
I-JEPA learns image representations for classification, detection and segmentation by predicting abstract features from masked regions using context blocks.
DMT-JEPA and S-JEA enhance visual representation learning for tasks like object detection and hierarchical semantic analysis.
2. Natural Language Processing
JEPA principles can be used to create sentence or document embeddings by learning to predict masked or missing parts of text in embedding space.
Such embeddings provide higher-level semantic understanding suited for classification, retrieval and transfer to downstream NLP tasks.
3. Multimodal Learning
V-JEPA models video by predicting abstract representations for masked spatial temporal regions, aiding robust activity recognition and event understanding.
A-JEPA applies similar masking and prediction to audio for improved speech and general audio classification.
Combining vision, language and audio data.
MC-JEPA jointly captures motion and content in video, supporting applications like autonomous driving, video surveillance and activity recognition
Cross modal JEPA variants (e.g., JEP-KD) align speech and visual features, advancing fields like audiovisual speech recognition and multimodal retrieval.
JEPA inspired models process point cloud data (Point-JEPA), graphs (Graph-JEPA) and time series for specialized tasks like 3D scene understanding, trajectory analysis and remote sensing
Advantages of JEPA
Abstraction: Learns high-level, semantic representations, not just pixel-level details.
Generalization: Representations are robust and can be used for many downstream tasks.
Data Efficiency: Works well with unlabeled data, reducing reliance on expensive annotations.
Flexibility: Can be applied to images, video, audio and more.

{kind=link}
{kind=link}