LangChain Document Loaders convert data from various formats such as CSV, PDF, HTML and JSON into standardized Document objects. These objects contain the raw content, metadata and optional identifiers, allowing LLMs to process and analyze the data efficiently.
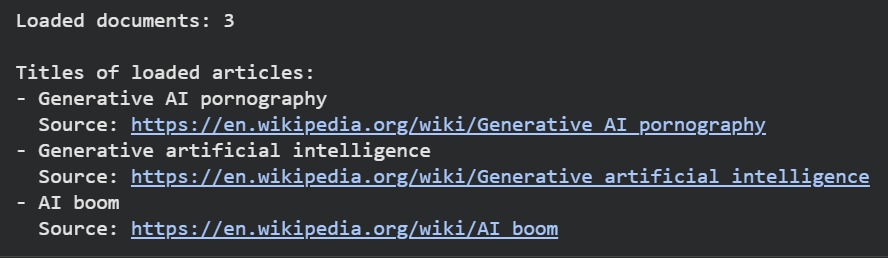
Document loaders also enable developers to manage and standardise content across multiple workflows, supporting a wide range of file types and sources including YouTube, Wikipedia and GitHub.
Document Object in LangChain
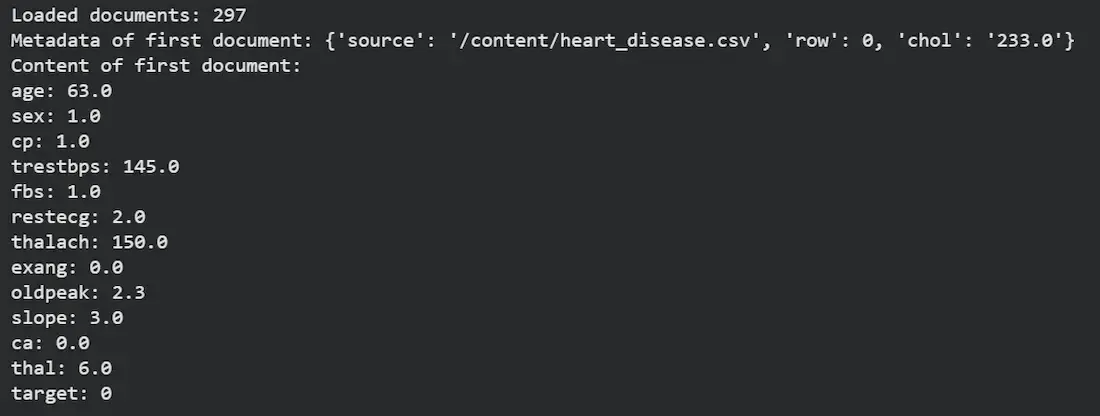
Before exploring loaders, we must understand the Document object which stores the content and metadata.
page_content: Stores the textual content of the document.
metadata: Provides additional information about the document like source or category.
With these methods we can easily load and process different types of documents in LangChain which can then be used for tasks like text analysis, question answering, summarization and building intelligent retrieval-based applications.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}