 |
VOOZH | about |
|
VOOZH | about |
Named Entity Recognition (NER) is an NLP task that identifies and classifies entities in text, such as people, organizations and locations. It helps systems automatically understand important information within sentences, even when language and context vary.
For example, in the sentence: Barack Obama was born in Hawaii and served as President of the United States.
NER identifies:
Run the following command in your command prompt to install required libraries
pip install transformers torch
Let's see the implementation of Named Entity Recognition using a BERT model without using the Hugging face transformer's pipeline API
Output:
This converts the sentence into tensors that the model can process, preparing it for entity prediction.
We use torch.no_grad() to disable gradient calculations because we are only performing inference, not training. This makes prediction faster and more memory efficient.
Output:
Import the pipeline from Transformers, as it provides a high level interface that automatically manages tokenization, model loading, inference and output formatting in a single streamlined workflow.
Output:
The pipeline processes the sentence, identifies named entities and returns them with their categories like Person, Organization, Location, etc. The loop simply prints each detected entity along with its label. The output shows the entities detected by the NER model:
Output:
We can see our model is working fine.
You can download the full code from here
{kind=link}
{kind=link}
{kind=link}
{kind=link}
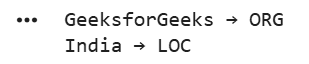{kind=link}