Working with large documents or unstructured text often creates challenges for language models, as they can only process limited text within their context window. To address this, LangChain provides Text Splitters which are components that segment long documents into manageable chunks while preserving semantic meaning and contextual continuity.
Purpose: Manage long-form text efficiently by splitting it into meaningful parts.
Integration: Works seamlessly with document loaders, vector stores and retrieval pipelines in LangChain.
Flexibility: Supports various splitting strategies depending on data type — plain text, markdown or token-based text.
Types of Text Splitters
Let's see the various types of text splitters:
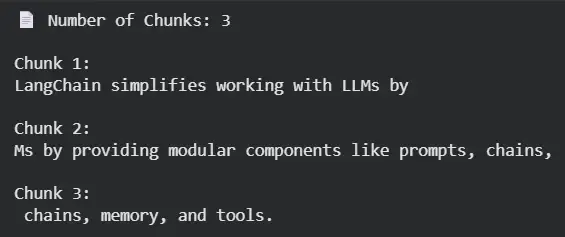
1. CharacterTextSplitter
The CharacterTextSplitter divides text into chunks of a fixed character length using a specified separator like spaces or newlines. It’s simple, fast and suitable for unstructured text where consistent chunk size is important.
Use Case: Ideal for short, unstructured text like FAQs or chatbot prompts.
Advantage: Very fast and lightweight. It provides strict control over chunk length.
Limitation: May split sentences mid-way, causing partial loss of meaning.
Example: Let's see an example to understand how CharacterTextSplitter works.
chunk_size defines the max characters per chunk.
chunk_overlap ensures continuity between splits.
separator=" " prevents breaking words abruptly.
Output produces evenly sized chunks for basic use cases.
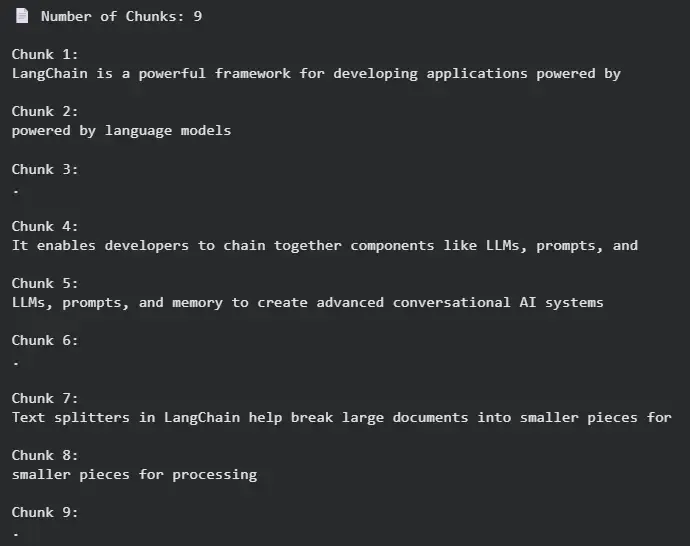
RecursiveCharacterTextSplitter intelligently divides text by prioritizing larger boundaries like paragraphs or sentences before resorting to smaller ones like spaces. It recursively ensures chunks are as meaningful as possible without exceeding size limits.
Use Case: Best for articles, reports or long documents where maintaining readability and context is crucial.
Advantage: Produces semantically coherent chunks that preserve flow and structure.
Limitation: Slightly slower due to recursive boundary checks.
Example: Let's see an example to understand how RecursiveCharacterTextSplitter works.
The TokenTextSplitter divides text based on token count instead of characters. It aligns chunking with how LLMs interpret text, ensuring the model doesn’t exceed token limits during processing.
Use Case: Suitable for LLM applications where token limits (e.g 4096 tokens) must be respected.
Advantage: Token-aware splitting ensures model compatibility and prevents truncation errors.
Limitation: Depends on tokenizers hence slightly slower than character-based methods.
Example: Let's see an example to understand how TokenTextSplitter works,
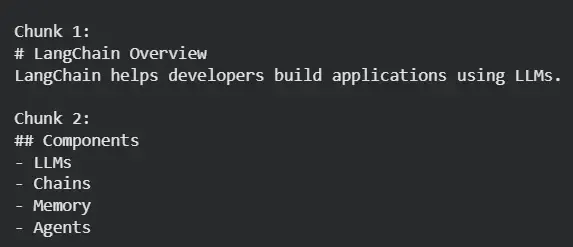
The MarkdownTextSplitter is designed to handle Markdown documents by splitting them along structural elements like headings, subheadings and lists—preserving the original hierarchy and readability.
Use Case: Ideal for blogs, documentation or technical reports in Markdown format.
Advantage: Retains Markdown formatting and hierarchy for better retrieval.
Limitation: Applicable only to .md-formatted text.
Example: Let's see an example to understand hoe MarkdownTextSplitter works.
Preserves Markdown hierarchy and structure.
Each chunk aligns with a logical section.
Ideal for Q&A systems on structured documentation.
Selecting the right Text Splitter depends on your document type, processing goal and the language model’s context limits. Each splitter serves a specific use case, balancing performance, context preservation and readability.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}