Weaviate is an open-source, cloud-native vector database that stores both objects and vectors allowing for the combination of vector search with traditional structured filling. Weaviate can run in the following ways:
Cloud : Weaviate can run over weaviate cloud abstracting all hardware and deployment from the user.
Local(Docker): Weaviate can also run locally as a Docker container.
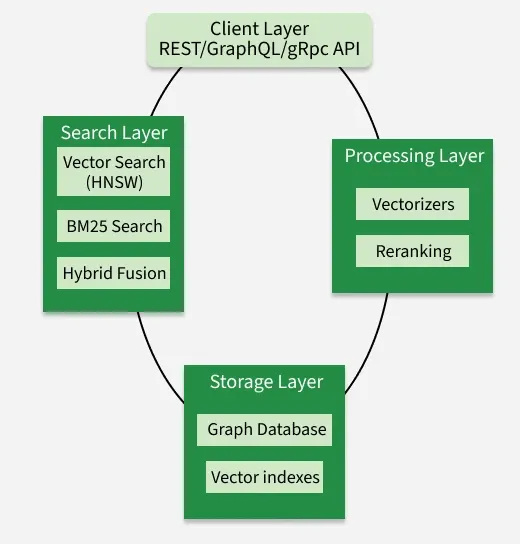
The client layer which handles the frontend and is closest to the user, handing all external communications
REST API : Standard HTTP endpoint handling all CRUD operations
GraphQL : Smarter alternative to REST API, trades payload length for query complexity.
Grpc: High performance binary protocol by google for low latency applications.
2. Search Layer(Middle)
The primary engine of weaviate responsible for executing queries.
Vector search(HNSW) : Hierarchical navigable small world is an algorithm that finds a data point in a dataset that’s very close to the given query point but not necessarily the absolute closest one.
BM25 : Best Matching 25 algorithm is used for keyword searches , it uses an optimized version of traditional TF-IDF method.
Hybrid Fusion : Uses Reciprocal rank fusion(RRF) algorithm, both HNSW and BM25 gives their own ranks to each documents , RRF is used to aggregate these rankings into one unified ranking system.
d = A document or item
N = The number of rankings , usually equal to number of independent retrievers.
k = smoothing parameter(usually 60) prevents one rank from dominating.
rank = Rank / Position of how relevant the document is .
3. Storage Layer(Bottom)
Persistence layer with three specialized storage systems.
Object Store : Stores the actual documents and their metadata , it is the main persistence layer.
Inverted Index : Enables property filtering and keyword search.
Vector Index : Organizes points in latent space , used by HNSW for vector similarity search.
Implementation
Let's try to run weaviate on docker and run a similarity search on some sample embedding objects.
Step 1: Install required libraries & check if all dependencies are installed:
docker --version : Shows the installed Docker version
docker info : Displays Docker system and runtime details
pip install -U weaviate-client[agents] : Installs or updates the Weaviate Python client with agent support
touch docker-compose.yaml : Creates an empty docker-compose configuration file
Step 2: Starting weaviate and ollama with docker compose , paste the below config in a docker-compose.yaml file.
Step 3: Start the docker containers of weaviate and ollama
Step 4: Create a weaviate collection and generate embeddings using Ollama nomic embed text model:
Weaviate for RAG (Retrieval-Augmented Generation) means using Weaviate as the vector database / retriever in a RAG pipeline so an LLM can ground its answers in your data.
In a standard RAG setup:
Ingest data = chunk documents -> create embeddings
Store embeddings = this is where Weaviate is used
Retrieve relevant chunks for a user query.
Generate an answer using an LLM + retrieved context
Weaviate handles steps 2 & 3, using native vector search and embedding store built into it, Weaviate integrates well with frameworks like langchain, llamaindex e.t.c.
Use Cases
Semantic Search: Enables similarity search over text embeddings from models like OpenAI, Cohere or SentenceTransformers.
Recommendation Systems: Matches user embeddings to item embeddings for personalized recommendations.
Image & Video Retrieval: Finds visually similar content using feature embeddings from CNNs or CLIP models.
Anomaly Detection: Identifies unusual data points in high-dimensional feature space.
Generative AI & RAG Systems: Integrates with LangChain, LlamaIndex and LLMs for embedding-based retrieval augmentation.
Weaviate v/s Traditional Databases
Database
Best For
Key strength
Weaviate
Hybrid Search & RAG
Native Hybrid search
Pinecone
Production apps
Ease of use & reliablity
Milvus
Large-scale performance
Horizontal scaling
Qdrant
Advanced filtering
Rust performance
Chroma
Prototyping & LLMs
Developer experience
Advantages
Native Hybrid Search: combines both semantic as well as keyword based search, which most providers don't.
Open-source flexibility: Due to its open-source nature ,people avoid vendor lock-in.
Multi-modal support: Supports images, videos, texts out of the box.
Limitations
Operational complexity(Self-Hosted): running weaviate locally raises complexity and requires specialized people or team to handle, adding to deployment complexity.
Smaller ecosystem: Relatively newer so lacks adoption by big players, less battle-tested software.
Limited free-trial (cloud): Only provides a 14-day free tier which may not be enough for most use cases.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}