 |
VOOZH | about |
|
VOOZH | about |
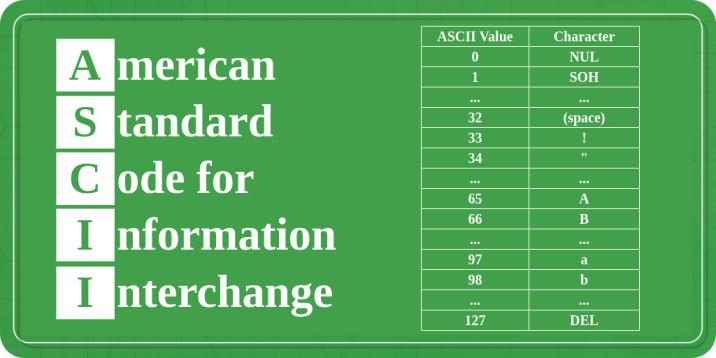
ASCII stands for American Standard Code for Information Interchange. It is a character encoding standard that has been a foundational element in computing for decades.
👁 ASCII-American-Standard-Code-for-Information-Interchange-1
ASCII has a rich history, dating back to its development in the early 1960s. Originating from telegraph code and Morse code, ASCII emerged as a standardized way to represent characters in computers, facilitating data interchange.
The ASCII character set includes standard characters such as letters, numbers, punctuation, and control characters. Each character is assigned a unique seven-bit binary code.
| Decimal | Character | Description |
|---|---|---|
| 0 | NUL | Null |
| 1 | SOH | Start of Header |
| 2 | STX | Start of Text |
| 3 | ETX | End of Text |
| 4 | EOT | End of Transmit |
| 5 | ENQ | Enquiry |
| 6 | ACK | Acknowledge |
| 7 | BEL | Bell |
| 8 | BS | Backspace |
| 9 | HT | Horizontal Tab |
| 10 | LF | Line Feed |
| 11 | VT | Vertical Tab |
| 12 | FF | Form Feed |
| 13 | CR | Carriage Return |
| 14 | SO | Shift Out |
| 15 | SI | Shift In |
| ... | ... | ... |
| 32 | (space) | Space |
| 33 | ! | Exclamation Mark |
| 34 | " | Quotation Mark |
| ... | ... | ... |
| 65 | A | Uppercase A |
| 66 | B | Uppercase B |
| ... | ... | ... |
| 97 | a | Lowercase a |
| 98 | b | Lowercase b |
| ... | ... | ... |
| 127 | DEL | Delete |
In addition to printable characters, ASCII includes control characters for formatting and controlling devices. These include characters like carriage return and line feed.
| Decimal | Character | Description |
|---|---|---|
| 0 | NUL | Null |
| 1 | SOH | Start of Header |
| 2 | STX | Start of Text |
| 3 | ETX | End of Text |
| 4 | EOT | End of Transmit |
| 5 | ENQ | Enquiry |
| 6 | ACK | Acknowledge |
| 7 | BEL | Bell |
| 8 | BS | Backspace |
| 9 | HT | Horizontal Tab |
| 10 | LF | Line Feed |
| 11 | VT | Vertical Tab |
| 12 | FF | Form Feed |
| 13 | CR | Carriage Return |
| 14 | SO | Shift Out |
| 15 | SI | Shift In |
While the original ASCII set comprises 128 characters, extended ASCII introduces an additional 128 characters, accommodating symbols and characters for different languages.
| Decimal | Character | Description |
|---|---|---|
| 128 | Ç | Latin Capital Letter C-cedilla |
| 129 | ü | Latin Small Letter U with Diaeresis |
| 130 | é | Latin Small Letter E with Acute |
| 131 | â | Latin Small Letter A with Circumflex |
| 132 | ä | Latin Small Letter A with Diaeresis |
| 133 | à | Latin Small Letter A with Grave |
| 134 | å | Latin Small Letter A with Ring Above |
| ... | ... | ... |
| 255 | ÿ | Latin Small Letter Y with Diaeresis |
A comprehensive ASCII table organizes characters and their corresponding binary, decimal, and hexadecimal representations.
| Decimal | Hex | Binary | Character | Description |
|---|---|---|---|---|
| 0 | 00 | 00000000 | NUL | Null |
| 1 | 01 | 00000001 | SOH | Start of Header |
| 2 | 02 | 00000010 | STX | Start of Text |
| 3 | 03 | 00000011 | ETX | End of Text |
| 4 | 04 | 00000100 | EOT | End of Transmit |
| 5 | 05 | 00000101 | ENQ | Enquiry |
| 6 | 06 | 00000110 | ACK | Acknowledge |
| 7 | 07 | 00000111 | BEL | Bell |
| 8 | 08 | 00001000 | BS | Backspace |
| 9 | 09 | 00001001 | HT | Horizontal Tab |
| 10 | 0A | 00001010 | LF | Line Feed |
| 11 | 0B | 00001011 | VT | Vertical Tab |
| 12 | 0C | 00001100 | FF | Form Feed |
| 13 | 0D | 00001101 | CR | Carriage Return |
| 14 | 0E | 00001110 | SO | Shift Out |
| 15 | 0F | 00001111 | SI | Shift In |
| 16 | 10 | 00010000 | DLE | Data Link Escape |
| 17 | 11 | 00010001 | DC1 | Device Control 1 (oft. XON) |
| 18 | 12 | 00010010 | DC2 | Device Control 2 |
| 19 | 13 | 00010011 | DC3 | Device Control 3 (oft. XOFF) |
| 20 | 14 | 00010100 | DC4 | Device Control 4 |
| 21 | 15 | 00010101 | NAK | Negative Acknowledge |
| 22 | 16 | 00010110 | SYN | Synchronous Idle |
| 23 | 17 | 00010111 | ETB | End of Transmission Block |
| 24 | 18 | 00011000 | CAN | Cancel |
| 25 | 19 | 00011001 | EM | End of Medium |
| 26 | 1A | 00011010 | SUB | Substitute |
| 27 | 1B | 00011011 | ESC | Escape |
| 28 | 1C | 00011100 | FS | File Separator |
| 29 | 1D | 00011101 | GS | Group Separator |
| 30 | 1E | 00011110 | RS | Record Separator |
| 31 | 1F | 00011111 | US | Unit Separator |
| 32 | 20 | 00100000 | (space) | Space |
| 33 | 21 | 00100001 | ! | Exclamation Mark |
| 34 | 22 | 00100010 | " | Quotation Mark |
| 35 | 23 | 00100011 | # | Number Sign |
| 36 | 24 | 00100100 | $ | Dollar Sign |
| 37 | 25 | 00100101 | % | Percent Sign |
| 38 | 26 | 00100110 | & | Ampersand |
| 39 | 27 | 00100111 | ' | Apostrophe (Single Quote) |
| 40 | 28 | 00101000 | ( | Left Parenthesis |
| 41 | 29 | 00101001 | ) | Right Parenthesis |
| 42 | 2A | 00101010 | * | Asterisk |
| 43 | 2B | 00101011 | + | Plus Sign |
| 44 | 2C | 00101100 | , | Comma |
| 45 | 2D | 00101101 | - | Hyphen (Minus Sign) |
| 46 | 2E | 00101110 | . | Period (Full Stop) |
| 47 | 2F | 00101111 | / | Solidus (Slash) |
| 48 | 30 | 00110000 | 0 | Digit Zero |
| 49 | 31 | 00110001 | 1 | Digit One |
| 50 | 32 | 00110010 | 2 | Digit Two |
| 51 | 33 | 00110011 | 3 | Digit Three |
| 52 | 34 | 00110100 | 4 | Digit Four |
| 53 | 35 | 00110101 | 5 | Digit Five |
| 54 | 36 | 00110110 | 6 | Digit Six |
| 55 | 37 | 00110111 | 7 | Digit Seven |
| 56 | 38 | 00111000 | 8 | Digit Eight |
| 57 | 39 | 00111001 | 9 | Digit Nine |
| 58 | 3A | 00111010 | : | Colon |
| 59 | 3B | 00111011 | ; | Semicolon |
| 60 | 3C | 00111100 | < | Less Than (Angle Bracket, Left Pointing) |
| 61 | 3D | 00111101 | = | Equals Sign |
| 62 | 3E | 00111110 | > | Greater Than (Angle Bracket, Right Pointing) |
| 63 | 3F | 00111111 | ? | Question Mark |
| 64 | 40 | 01000000 | @ | At Sign |
| 65 | 41 | 01000001 | A | Uppercase A |
| 66 | 42 | 01000010 | B | Uppercase B |
| 67 | 43 | 01000011 | C | Uppercase C |
| 68 | 44 | 01000100 | D | Uppercase D |
| 69 | 45 | 01000101 | E | Uppercase E |
| 70 | 46 | 01000110 | F | Uppercase F |
| 71 | 47 | 01000111 | G | Uppercase G |
| 72 | 48 | 01001000 | H | Uppercase H |
| 73 | 49 | 01001001 | I | Uppercase I |
| 74 | 4A | 01001010 | J | Uppercase J |
| 75 | 4B | 01001011 | K | Uppercase K |
| 76 | 4C | 01001100 | L | Uppercase L |
| 77 | 4D | 01001101 | M | Uppercase M |
| 78 | 4E | 01001110 | N | Uppercase N |
| 79 | 4F | 01001111 | O | Uppercase O |
| 80 | 50 | 01010000 | P | Uppercase P |
| 81 | 51 | 01010001 | Q | Uppercase Q |
| 82 | 52 | 01010010 | R | Uppercase R |
| 83 | 53 | 01010011 | S | Uppercase S |
| 84 | 54 | 01010100 | T | Uppercase T |
| 85 | 55 | 01010101 | U | Uppercase U |
| 86 | 56 | 01010110 | V | Uppercase V |
| 87 | 57 | 01010111 | W | Uppercase W |
| 88 | 58 | 01011000 | X | Uppercase X |
| 89 | 59 | 01011001 | Y | Uppercase Y |
| 90 | 5A | 01011010 | Z | Uppercase Z |
| 91 | 5B | 01011011 | [ | Left Square Bracket |
| 92 | 5C | 01011100 | \ | Backslash |
| 93 | 5D | 01011101 | ] | Right Square Bracket |
| 94 | 5E | 01011110 | ^ | Caret (Circumflex Accent) |
| 95 | 5F | 01011111 | _ | Underscore |
| 96 | 60 | 01100000 | ` | Grave Accent |
| 97 | 61 | 01100001 | a | Lowercase a |
| 98 | 62 | 01100010 | b | Lowercase b |
| 99 | 63 | 01100011 | c | Lowercase c |
| 100 | 64 | 01100100 | d | Lowercase d |
| 101 | 65 | 01100101 | e | Lowercase e |
| 102 | 66 | 01100110 | f | Lowercase f |
| 103 | 67 | 01100111 | g | Lowercase g |
| 104 | 68 | 01101000 | h | Lowercase h |
| 105 | 69 | 01101001 | i | Lowercase i |
| 106 | 6A | 01101010 | j | Lowercase j |
| 107 | 6B | 01101011 | k | Lowercase k |
| 108 | 6C | 01101100 | l | Lowercase l |
| 109 | 6D | 01101101 | m | Lowercase m |
| 110 | 6E | 01101110 | n | Lowercase n |
| 111 | 6F | 01101111 | o | Lowercase o |
| 112 | 70 | 01110000 | p | Lowercase p |
| 113 | 71 | 01110001 | q | Lowercase q |
| 114 | 72 | 01110010 | r | Lowercase r |
| 115 | 73 | 01110011 | s | Lowercase s |
| 116 | 74 | 01110100 | t | Lowercase t |
| 117 | 75 | 01110101 | u | Lowercase u |
| 118 | 76 | 01110110 | v | Lowercase v |
| 119 | 77 | 01110111 | w | Lowercase w |
| 120 | 78 | 01111000 | x | Lowercase x |
| 121 | 79 | 01111001 | y | Lowercase y |
| 122 | 7A | 01111010 | z | Lowercase z |
| 123 | 7B | 01111011 | { | Left Curly Brace |
| 124 | 7C | 01111100 | | | Vertical Bar |
| 125 | 7D | 01111101 | } | Right Curly Brace |
| 126 | 7E | 01111110 | ~ | Tilde |
| 127 | 7F | 01111111 | DEL | Delete |
ASCII characters are represented in binary, providing a machine-readable format that computers use for internal processing.
| Binary | Character | Description |
|---|---|---|
| 00000000 | NUL | Null |
| 00000001 | SOH | Start of Header |
| 00000010 | STX | Start of Text |
| 00000011 | ETX | End of Text |
| 00000100 | EOT | End of Transmit |
| 00000101 | ENQ | Enquiry |
| 00000110 | ACK | Acknowledge |
| 00000111 | BEL | Bell |
| 00001000 | BS | Backspace |
| 00001001 | HT | Horizontal Tab |
| 00001010 | LF | Line Feed |
| 00001011 | VT | Vertical Tab |
| 00001100 | FF | Form Feed |
| 00001101 | CR | Carriage Return |
| 00001110 | SO | Shift Out |
| 00001111 | SI | Shift In |
| ... | ... | ... |
| 00100000 | (space) | Space |
| 00100001 | ! | Exclamation Mark |
| 00100010 | " | Quotation Mark |
| ... | ... | ... |
| 01000001 | A | Uppercase A |
| 01000010 | B | Uppercase B |
| ... | ... | ... |
| 01100001 | a | Lowercase a |
| 01100010 | b | Lowercase b |
| ... | ... | ... |
| 01111111 | DEL | Delete |
In decimal form, ASCII codes offer a human-readable representation, simplifying discussions and documentation.
| Decimal | Character | Description |
|---|---|---|
| 0 | NUL | Null |
| 1 | SOH | Start of Header |
| 2 | STX | Start of Text |
| 3 | ETX | End of Text |
| 4 | EOT | End of Transmit |
| 5 | ENQ | Enquiry |
| 6 | ACK | Acknowledge |
| 7 | BEL | Bell |
| 8 | BS | Backspace |
| 9 | HT | Horizontal Tab |
| 10 | LF | Line Feed |
| 11 | VT | Vertical Tab |
| 12 | FF | Form Feed |
| 13 | CR | Carriage Return |
| 14 | SO | Shift Out |
| 15 | SI | Shift In |
| ... | ... | ... |
| 32 | (space) | Space |
| 33 | ! | Exclamation Mark |
| 34 | " | Quotation Mark |
| ... | ... | ... |
| 65 | A | Uppercase A |
| 66 | B | Uppercase B |
| ... | ... | ... |
| 97 | a | Lowercase a |
| 98 | b | Lowercase b |
| ... | ... | ... |
| 127 | DEL | Delete |
The hexadecimal representation of ASCII codes is commonly used in programming and digital design.
| Hexadecimal | Character | Description |
|---|---|---|
| 00 | NUL | Null |
| 01 | SOH | Start of Header |
| 02 | STX | Start of Text |
| 03 | ETX | End of Text |
| 04 | EOT | End of Transmit |
| 05 | ENQ | Enquiry |
| 06 | ACK | Acknowledge |
| 07 | BEL | Bell |
| 08 | BS | Backspace |
| 09 | HT | Horizontal Tab |
| 0A | LF | Line Feed |
| 0B | VT | Vertical Tab |
| 0C | FF | Form Feed |
| 0D | CR | Carriage Return |
| 0E | SO | Shift Out |
| 0F | SI | Shift In |
| ... | ... | ... |
| 20 | (space) | Space |
| 21 | ! | Exclamation Mark |
| 22 | " | Quotation Mark |
| ... | ... | ... |
| 41 | A | Uppercase A |
| 42 | B | Uppercase B |
| ... | ... | ... |
| 61 | a | Lowercase a |
| 62 | b | Lowercase b |
| ... | ... | ... |
| 7F | DEL | Delete |
Programming languages extensively use ASCII for representing characters and symbols in source code.
ASCII is fundamental in data transmission protocols, ensuring compatibility and readability when exchanging information between systems.
Artistic expressions, known as ASCII art, leverage ASCII characters to create visual designs and graphics.
ASCII and Unicode are both character encoding standards, but they have key differences in terms of scope and functionality. Let's compare ASCII and Unicode in a tabular format:
| Feature | ASCII | Unicode |
|---|---|---|
| Definition | ASCII (American Standard Code for Information Interchange) is a character encoding standard that uses 7 or 8 bits to represent characters, mainly limited to the English alphabet, numerals, and a few special characters. | Unicode is a character encoding standard that aims to provide a unique code point for every character, regardless of platform, program, or language. It uses a variable number of bits (8, 16, or 32) to represent characters. |
| Scope | Originally designed for English and a few other Western languages. | Designed to be a universal character encoding standard that supports a vast range of languages, symbols, and characters from various writing systems. |
| Bit Usage | Typically uses 7 bits (extended ASCII uses 8 bits). | Can use 8, 16, or 32 bits per character, allowing it to represent a much larger number of characters. |
| Number of Characters | Limited to 128 (with 7 bits) or 256 (with 8 bits). | Can represent over a million unique characters. |
| Multilingual Support | Primarily supports English and a few Western languages. | Comprehensive support for almost all languages, including scripts like Cyrillic, Arabic, Chinese, Japanese, and many others. |
| Backward Compatibility | Limited, as it was primarily designed for English and does not have built-in support for characters from various languages. | Maintains backward compatibility with ASCII. The first 128 Unicode code points correspond to ASCII, ensuring compatibility with existing ASCII data. |
| Representation | Uses one byte (8 bits) per character. | Variable-length encoding, using 8, 16, or 32 bits per character. |
| Standard Organization | Developed by ANSI (American National Standards Institute). | Developed by the Unicode Consortium, a non-profit organization that maintains and develops the Unicode standard. |
ASCII and Unicode differ in scope, with ASCII representing 128 characters and Unicode accommodating a vast array of characters from various scripts.
While ASCII is suitable for English and basic character encoding, Unicode is preferred for multilingual and diverse character requirements.
Demonstrations on converting characters to their ASCII equivalents for practical applications.
ASCII, as a character encoding standard, plays a significant role in file handling. When working with text files, understanding how ASCII characters are encoded and decoded is essential. Here's how ASCII is involved in file handling:
# Example in Python using UTF-8 encoding
with open('example.txt', 'r', encoding='utf-8') as file:
content = file.read()
LF or \n) and carriage return (CR or \r). The choice of line endings (Unix/Linux using LF, Windows using CRLF) affects how text files are handled on different operating systems.URL encoding, also known as percent-encoding, is a method used to represent certain characters in a URL by replacing them with a percent sign (%) followed by two hexadecimal digits. While URL encoding can encompass a broader range of characters, ASCII characters play a significant role in this process. Here's how ASCII is involved in URL encoding:
%20, and the exclamation mark (!) is represented as %21. This prevents misinterpretation of these characters by the URL parser.Original: Hello World!
URL Encoded: Hello%20World%21
Original: /path/to/file with spaces.txt
URL Encoded: /path/to/file%20with%20spaces.txt
Original: Line1\nLine2
URL Encoded: Line1%0ALine2
# Example in Python
import urllib.parse
url = "https://example.com/path with spaces"
encoded_url = urllib.parse.quote(url)
print(encoded_url)
Original: ?name=John Doe&age=30
URL Encoded: ?name=John%20Doe&age=30
ASCII, while widely used and simple, has some limitations, especially in the context of modern computing needs. Here are some of the key limitations of ASCII:
Handling non-ASCII characters is crucial when dealing with text data that goes beyond the basic Latin alphabet covered by ASCII. Here are some common approaches and considerations for handling non-ASCII characters:
string or char data types that support Unicode is essential.<meta> tag of HTML documents to ensure that web browsers interpret and display non-ASCII characters correctly.By embracing Unicode and adopting best practices for handling non-ASCII characters, you can ensure that your applications are capable of supporting a wide range of languages and writing systems. This is particularly important in today's globalized and interconnected world.
{kind=link}
{kind=link}