 |
VOOZH | about |
|
VOOZH | about |
Chi-Square test helps us determine if there is a significant relationship between two categorical variables. It is a non-parametric statistical test meaning it doesn’t follow normal distribution.
The Chi-square test compares the observed frequencies (actual data) to the expected frequencies (what we would expect if there was no relationship). This helps identify which features are important for predicting the target variable in machine learning models.
Chi-square statistic is calculated as:
where,
Often used with non-normally distributed data. Before we jump into calculations. let's understand some important terms:
The two main types are the chi-square test for independence and the chi-square goodness-of-fit test.
1. Chi-Square Test for Independence: This test is used whether there is a significant relationship between two categorical variables.
2. Chi-Square Goodness-of-Fit Test:The Chi-Square Goodness-of-Fit test is used to check if a variable follows a specific expected pattern or distribution.
Step 1: Define Your Hypotheses
Step 2: Create a Contingency Table: This is simply a table that displays the frequency distribution of the two categorical variables.
Step 3: Calculate Expected Values: To find the expected value for each cell use this formula:
Step 4: Compute the Chi-Square Statistic: Now use the Chi-Square formula:
where:
If the observed and expected values are very different the Chi-Square value will be high which indicate a strong relationship.
Step 5: Compare with the Critical Value:
The Chi-Square Test helps us find relationships or differences between categories. Its main uses are:
Let us examine a dataset with features including "income level" (low, medium, high) and "subscription status" (subscribed, not subscribed) indicate whether a customer subscribed to a service. The goal is to determine if this feature is relevant for predicting subscription status.
Income Level | Subscribed | Not subscribed | Row Total |
|---|---|---|---|
Low | 20 | 30 | 50 |
Medium | 40 | 25 | 65 |
High | 10 | 15 | 25 |
Column Total | 70 | 70 | 140 |
For example the expected frequency for "Low Income" and "Subscribed" would be:
Similarly we can find expected frequencies for other aspects as well:
Subscribed | Not Subscribed | |
|---|---|---|
Low Income | 25 | 25 |
Medium Income | 32.5 | 32.5 |
High Income | 12.5 | 12.5 |
Let's summarize the observed and expected values into a table and calculate the Chi-Square value:
Subscribed (O) | Not Subscribed (O) | Subscribed (E) | Not Subscribed (E) | |
|---|---|---|---|---|
Low Income | 20 | 30 | 25 | 25 |
Medium Income | 40 | 25 | 32.5 | 32.5 |
High Income | 10 | 15 | 12.5 | 12.5 |
Now using the formula specified in equation 1 we can get our chi-square statistic values in the following manner:
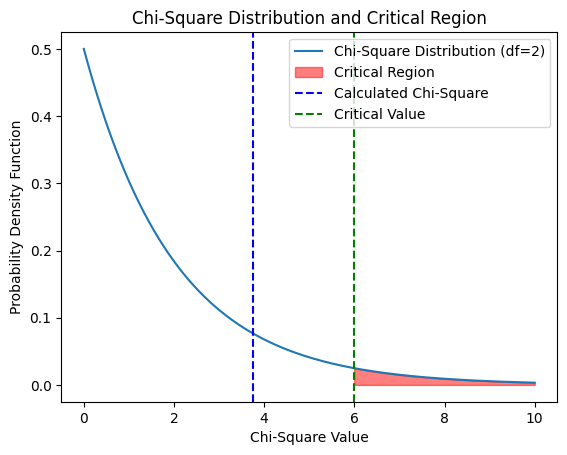
Now compare the calculated alue (6.462) with the critical value for 2 degrees of freedom. The critical value can be obtained either from a standard Chi-square distribution table or by using Python’s stats.chi2.ppf() function. If the calculated is greater than the critical value, then we reject the null hypothesis.
Before its implementation we should have some basic knowledge about numpy, matplotlib and scipy.
Output:
5.991464547107979For df = 2 and significance level , the critical value is 5.991.
Output:
In this example The green dashed line represents the critical value the threshold beyond which you would reject the null hypothesis.
If the calculated Chi-Square statistic falls within this shaded area then you would reject the null hypothesis.
{kind=link}
{kind=link}
{kind=link}
{kind=link}