 |
VOOZH | about |
|
VOOZH | about |
Embeddings represent text as vectors in a high dimensional space, placing similar meanings closer together. In CrewAI, they enable memory, helping agents retain context and recall past interactions.
Embeddings play a key role in enabling intelligent memory and information handling in CrewAI systems.
This example shows how embeddings in CrewAI enable agents to store, retrieve and share context, with memory=True ensuring continuity across tasks.
OpenAI embeddings can be used for memory, offering strong semantic similarity performance. Models like text-embedding-3-small are efficient, while larger variants provide higher accuracy.
Output:
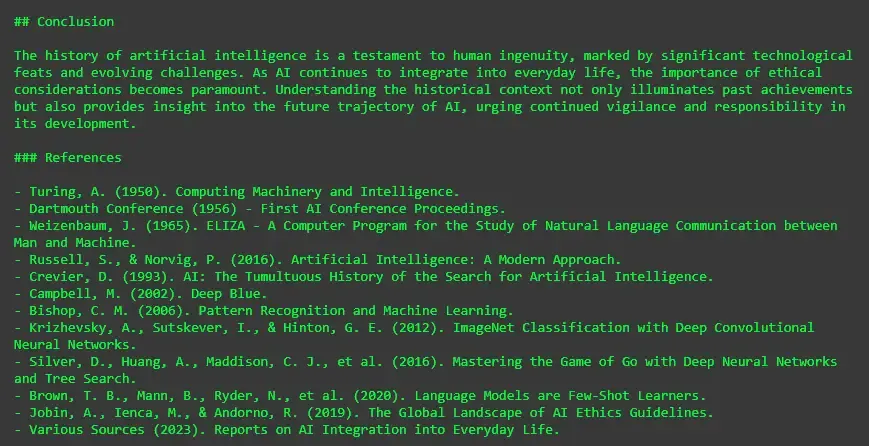
Google embeddings are suitable for multilingual tasks and large-scale data. Models such as models/embedding-001 provide strong cross-lingual support.
Output:
Hugging Face embeddings give access to a wide range of open-source models. Options like sentence-transformers/all-MiniLM-L6-v2 are lightweight and effective for semantic search and retrieval.
Output:
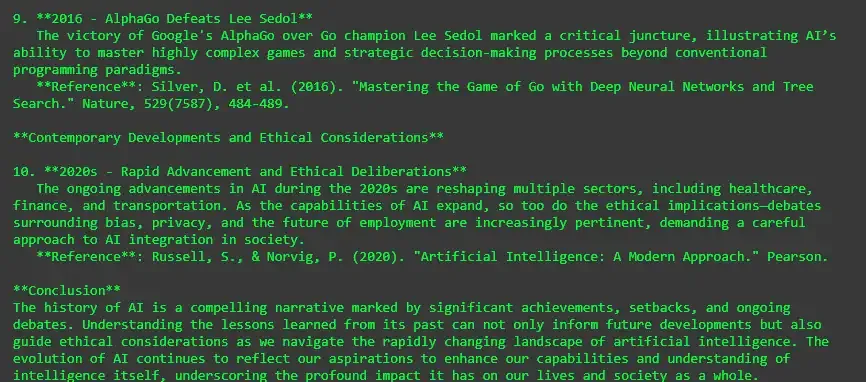
Cohere embeddings are designed for English text and high-performance retrieval tasks. Models like embed-english-v2.0 perform well in semantic similarity and large-scale search.
Output:
This table outlines the main embedding providers available in CrewAI, showing how they differ in models, strengths and use cases.
| Provider | Typical Models | Strengths | Best For |
|---|---|---|---|
| OpenAI | text-embedding-3-small, text-embedding-3-large | High-quality semantic similarity, reliable performance | General-purpose apps, balanced cost and quality |
models/embedding-001 | Strong multilingual support, trained on large datasets | Multilingual tasks, global content, Google ecosystem | |
| Hugging Face | sentence-transformers/all-MiniLM-L6-v2 (and others) | Open-source, flexible, customizable, cost-friendly | Research, experimentation, self-hosted setups |
| Cohere | embed-english-v2.0 | Optimized for English, high performance in semantic search | English focused applications, production retrieval |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}