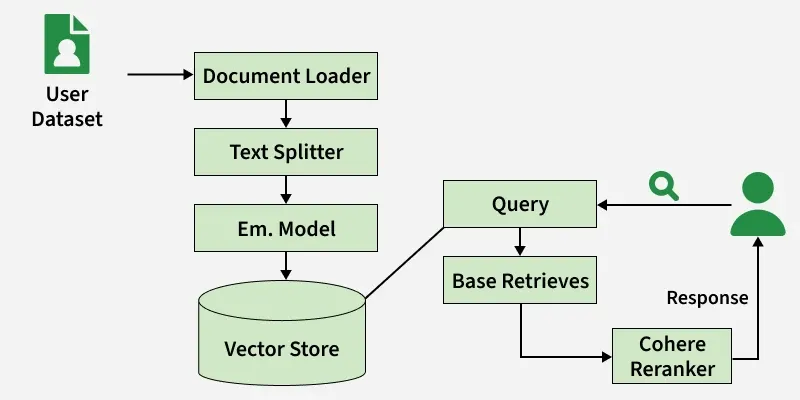
Cohere Rerank is a transformer-based model that reorders retrieved documents based on their true contextual relevance to a query, going beyond simple similarity matching. In a typical Retrieval-Augmented Generation (RAG) pipeline it acts as a re-ranking layer. After the initial search, it evaluates each query–document pair and assigns a relevance score that reflects how good a document answers the user’s intent.
By combining semantic embeddings (for retrieval) and contextual re-ranking (for precision), it ensures the most relevant and insightful results are prioritized before generation.
Purpose: It helps our system understand which results truly matter, not just which ones “sound similar.”
Why It Matters: It captures subtle meanings, intent shifts and nuanced language where traditional embedding searches can struggle.
How It Fits In: Works as a refinement layer in RAG, after FAISS retrieves top-K documents, Cohere Rerank reshuffles them based on contextual understanding.
End Result: Produces more focused, accurate and context-aware responses from our AI system.
Real-World Value: Essential for applications like academic research assistants, intelligent chatbots and semantic search tools where precision and depth are key.
We will import the required libraries for our system such as CohereEmbeddings, CohereRerank, FAISS and numpy.
Step 2: Load Dataset
The system loads 300 AI research paper entries and each document combines the title and abstract to form meaningful content chunks. Here it will load dataset from datasets library which we imported in above step.
Output:
Loaded 300 AI research papers.
Step 3: Generate Cohere Embeddings
Here:
Embeds each document using Cohere’s embed-english-v3.0 model.
Builds a FAISS index for fast similarity-based retrieval.
Output:
FAISS vectorstore built successfully!
Step 4: Retrieve Top Documents
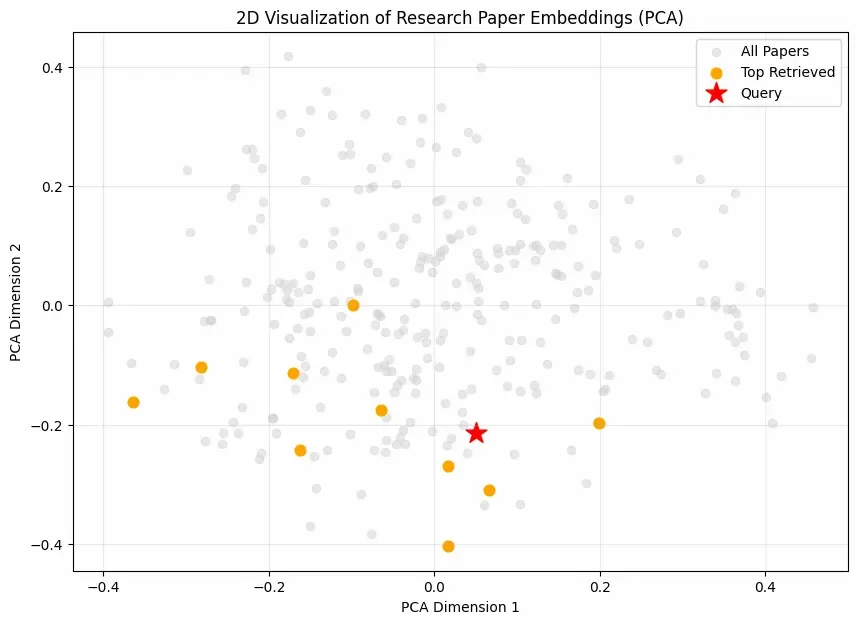
Searches the FAISS index to fetch the top 10 documents similar to the query.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}