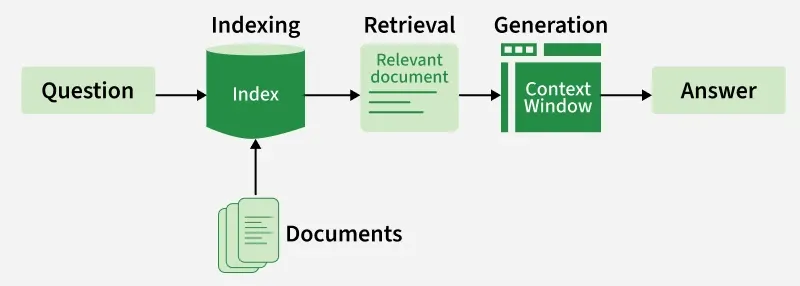
Indexing in LangChain is the process of organizing documents in a vector database such that a language model can quickly find and use them. It works by turning documents into embeddings and keeping them synchronized in the store.
The Indexing API makes this easier by managing updates, avoiding duplicates and skipping re-computation for unchanged content.
Here’s why indexing matters when building retrieval based systems in LangChain:
Efficiency and Cost Savings: Vector stores skip redundant computations, prevent duplication and support incremental updates to save storage and compute.
Data Accuracy and Freshness: They keep the vector store synchronized with source documents, remove outdated content and maintain correct chunk mappings.
Operational Benefits: Vector stores simplify workflows, improve RAG performance and support multiple indexing strategies.
Core Functional Role: They organize documents for efficient semantic search and provide accurate, context aware information for LLMs in RAG applications.
Types of Indexes in LangChain
Different types of indexing are used in LangChain to organize and search data depending on the needs of the application.
Vector Index: Stores document embeddings in a vector database for semantic search in RAG pipelines.
Keyword Index: Uses inverted indexes for fast keyword based exact matches.
Hybrid Index: Combines vector and keyword indexes to support both semantic and exact search.
Metadata Index: Organizes documents by metadata like author, date or tags for filtering.
Document Index: Stores raw documents or chunks with metadata as the base for further processing.
Working
Here is the working of Indexing in LangChain.
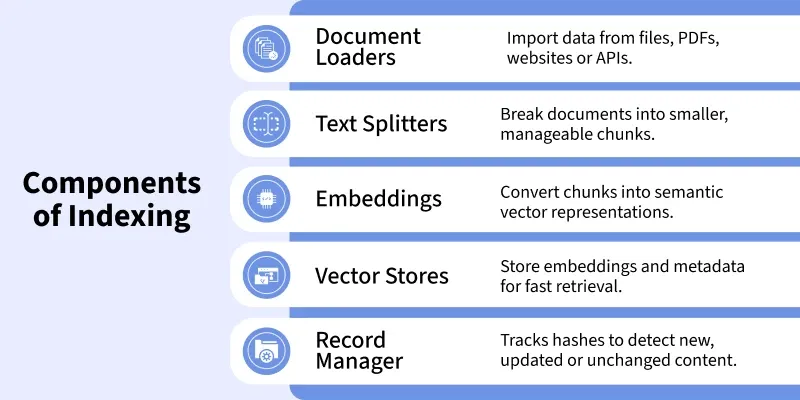
Document Loading: Load data from sources like text files, PDFs, websites or APIs using a DocumentLoader.
Text Splitting: Break large documents into smaller chunks with a TextSplitter so they fit within LLM limits.
Hash Generation: Create a unique hash for each chunk to check if it is new, updated or unchanged.
Record Manager Check: First run then if no match is found, chunks are embedded and stored. For later runs, skip unchanged chunks and only process new or updated ones.
Embedding Generation: Convert chunks into vector embeddings using models like text-embedding-ada-002.
Vector Store Insertion: Store embeddings with metadata in a vector database like FAISS, Pinecone, Weaviate, etc.
Managing Outdated Documents: Remove old or deleted documents to keep the index up to date.
Retrieval Ready: The indexed data can now be searched semantically to fetch relevant chunks for the LLM.
Implementation
Steps to implement Indexing in LangChain are:
Step 1: Install Dependencies
Installing LangChain core, OpenAI integration, FAISS for vector storage, dotenv for env vars and community modules.
Step 2: Import Libraries
Importing different LangChain's modules and Operating System.
Step 3: Environment Setup
Setting up environment using OpenAI API Key, we can also use Gemini's API Key.

{kind=link}
{kind=link}
{kind=link}
{kind=link}