Retrievals enable Large Language Model to use external data sources. LLMs only generate responses on their own based on training data which can be outdated or incomplete. Retrieval chains solve this limitation by linking LLMs to live, curated or private knowledge.
This makes them important for building production-level AI systems such as enterprise chatbots, knowledge assistants and decision support tools where accuracy and transparency are non-negotiable.
Components of Retrieval Chains
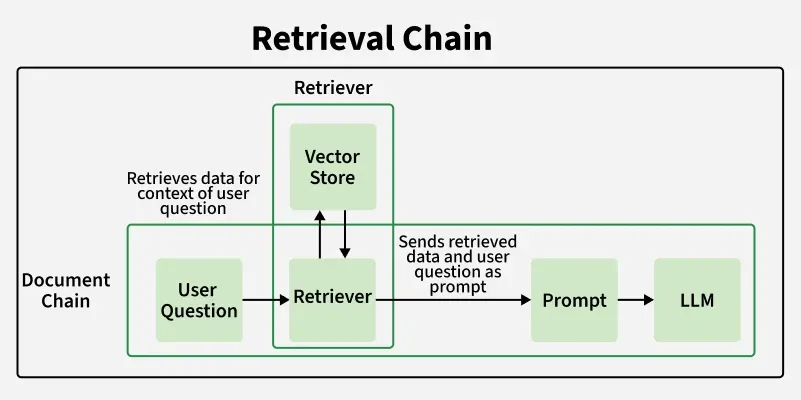
It is a structured workflow in LangChain that connects information retrieval with answer generation. Instead of relying only on the LLM’s internal knowledge, the chain first retrieves the most relevant information from an external source such as a vector database or document store then passes that context to the LLM to create a grounded response.
Retriever: Searches for the most relevant documents or text chunks related to the user’s query.
Chain: LLM Chains organizes this data, cleans or formats it if needed and prepares it for the LLM.
LLM: Combines the user’s query with the retrieved context to produce an answer that is both fluent and supported by real information.
It reduces hallucination, makes the reasoning process more transparent and ensures the model’s output is tied to actual data sources rather than just probabilities from training.
Stuff Chain: All retrieved documents are combined into a single prompt with the query. It is simple and fast, best for small context sizes.
Map Reduce Chain: Each document is processed individually then the results are summarized into a final answer. It is useful for handling large numbers of documents.
Refine Chain: Starts with one document to draft an answer then iteratively improves it by adding context from the remaining documents. It produces more detailed answers when context is spread across many sources.
The step by step working of Retrieval Chains is mentioned below :
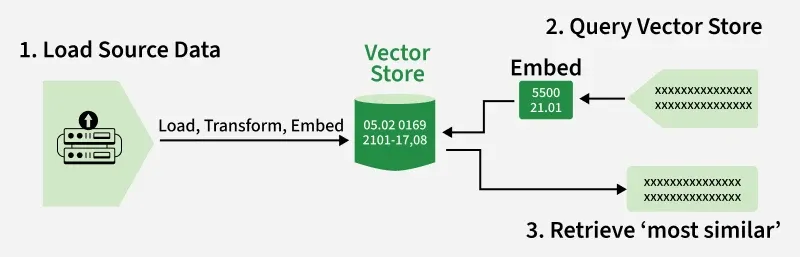
1. Indexing Phase (done offline)
Load documents: Gather content from sources such as PDFs, websites or databases.
Split documents: Break large documents into smaller chunks so they are easier to process.
Create embeddings: Use an embedding model to turn each text chunk into a numerical vector.
Store vectors: Vector Store save both the text chunks and their vectors in a vector database like FAISS, Pinecone and Chroma.
2. Retrieval and Generation Phase (at runtime)
User query: A user asks a question in natural language.
Query embedding: The query is converted into a vector for comparison.
Retrieve documents: The retriever searches the vector database to find the most relevant chunks. Retrieval can use similarity search, MMR (Maximal Marginal Relevance) and hybrid search
Chain assembly: The retrieved documents and query are combined into a structured prompt. Chain types include Stuff, Map Reduce and Refine.
LLM processing: The LLM receives the enriched prompt and generates a response which relies on the retrieved evidence.
Post processing: The final answer may be formatted, shortened or include citations before being shown to the user.
Implementation of Retrieval Chains
Let's implement a model using LangChain.
Step 1: Install Dependencies
Installing dependencies like LangChain core and its integrations.
Installing supporting libraries for storage, API calls, token handling and env variables.
Step 2: Import Libraries
Here we're importing libraries like:
ChatOpenAI: Running the LLM
OpenAIEmbeddings: Turning text into vectors which is in numerical form.
Chroma: Storing and searching those vectors in memory.
create_retrieval_chain: Connecting retriever and LLM into a working RAG pipeline.
Step 3: Environment Setup
Setting up environment using API Key, we can use Gemini's API also.
Use cases of Retrieval Chains are mentioned below:
Enterprise Knowledge Assistants: Employees can quickly find answers in HR manuals, policies or training guides without reading long documents.
Customer Support Bots: Virtual assistants can return accurate answers from FAQs or troubleshooting guides, making customer service faster and more consistent.
Research Assistants: Users can summarize or compare insights from multiple papers or case studies saving time on manual reading.
Healthcare Applications: Clinicians can access medical guidelines or drug references quickly to support better decision making.
E-learning Platforms: Students can ask questions and receive grounded answers from textbooks or lecture notes, improving learning.
Advantages
Some advantages of Retrieval Chains are as follows:
Accuracy: Retrieval chains ground answers in real documents which reduces hallucination and makes responses more reliable.
Transparency: They can return the source documents so users can verify how an answer was generated.
Flexibility: Work with many retrievers and databases like FAISS, Pinecone and Chroma without changing the chain logic.
Customizable Chains: Support different chain types such as Stuff, Map Reduce and Refine to handle both short and long documents.
Scalable Knowledge: Vector databases allow retrieval from millions of documents in real time.
Disadvantages
Some disadvantages of Retrieval Chains are as follows:
Latency: The system takes more time to respond because it must first look for documents then create an answer.
Index Maintenance: The document store needs to be updated when new information comes in or old data changes or else the answers can become outdated.
Cost Overhead: Since retrieval adds more text to the prompt, it uses more tokens which can make the system more expensive to run.
Retriever Quality Dependency: If the retriever is not set up well or the embeddings are weak, it may bring back poor documents which lowers answer quality.
Complexity: Retrieval chains have several parts like retrievers and databases so they are harder to set up and manage compared to a simple LLM prompt.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}