LangChain callbacks are an event-driven system for monitoring, debugging and customizing the execution of your LLM applications, letting you "hook into" different stages like LLM calls, chain starts/ends or token generation to log data, stream responses, track costs or integrate with external tools.
langchain callbacks provide the primary mechanism for instrumenting, monitoring and understanding execution behavior.
Why Langchain Callbacks exist
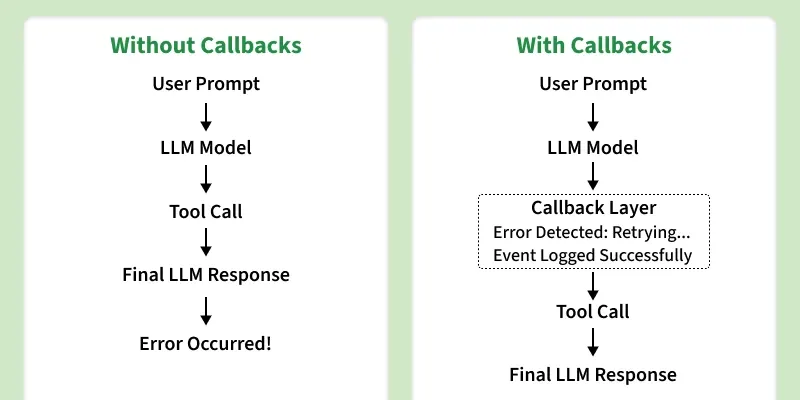
Without langchain callbacks, the system is opaque, when something fails, slows down or retries, we can't pinpoint its origin or observe the issue ourselves, langchain callbacks exists to solve this problem.
Callbacks provide structured observability into the runtime behavior of a LangChain application, without modifying core application logic.
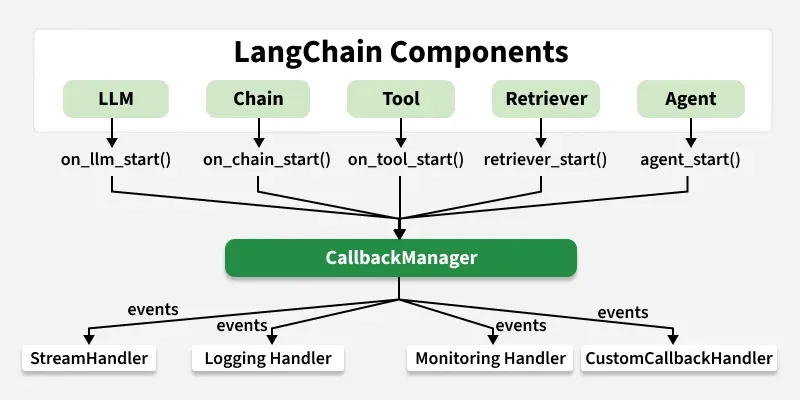
All callback handlers inherit from a single Baseclass named langchain.core.callbacks.BaseCallbackHandler, this baseclass defines a set of optional hook methods for every model.
LangChain uses a publish–subscribe (observer) model.
The runtime publishes events
Callback handlers subscribe to those events
Handlers receive structured metadata but cannot alter execution
Let's Implement a callback example to further our understanding
Step 1: Install required libraries
Step 2: Implementing Callback Class
The class inherits from langchain's callback base class, which allows it to overload its functions.
on_llm_start() is triggered right before the model starts.
on_llm_end() is triggered after the LLM execution cycle is completed.
on_llm_error() is triggered if any exception occurs during the execution of the program.
Step 3: Define the model's pipeline using Hugging face and transformers library
We load Qwen2.5 (1.5B parameter) model, this is a lightweight alternative and can run comfortably on a T4 GPU.
The tokenizer converts text into model-readable tokens and the model is loaded with device_map="auto" so it automatically uses available CPU/GPU resources.
The pipeline("text-generation") creates a simple interface for text generation, handling tokenization, inference and decoding.
HuggingFacePipeline() adapts the Hugging Face pipeline to LangChain’s LLM interface
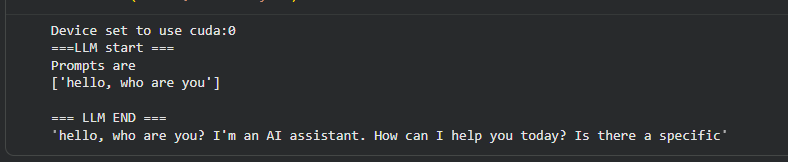
In the given output both texts LLM start and LLM end were a result of the callback function firing when llm started and ended.
Advantages
Reduces Blackbox execution : Callbacks let us see what's happening while the model is running, this visiblity makes debugging less frustrating.
No interference with model flow : Callbacks only observe. You can add or remove them without worrying about prompts breaking or system flow getting altered.
Modular in nature : Same callback can be used for LLM, a chain, agent, tool. this makes the code reusable and modular.
Limitation
Cannot control execution : Callbacks cannot stop a run, modify outputs or change prompts, this makes them good for logging and observing but not custom logic to handle situations.
Can clutter logs : Adding too many callbacks or logging too much information can make outputs noisy and harder to interpret, especially in large systems.
Complexity & Overhead : for small projects, callbacks are not necessary and may add extra overhead and complexity.

{kind=link}
{kind=link}
{kind=link}
{kind=link}