Multimodal Retrieval-Augmented Generation combines text, images, audio and video with retrieval to enhance generative models, enabling more accurate, context aware and informative responses beyond single modality systems.
Uses multiple data types for richer understanding and context.
Combines retrieval mechanisms with generative models.
Improves accuracy and relevance of responses.
Supports complex tasks where single data type is insufficient.
Multimodal RAG improves performance by using diverse data sources, enabling better understanding and more accurate responses.
Enhances contextual understanding by combining textual and non textual data.
Improves content generation with richer, more relevant and engaging outputs.
Increases accuracy by retrieving and using information from multiple sources.
Architecture
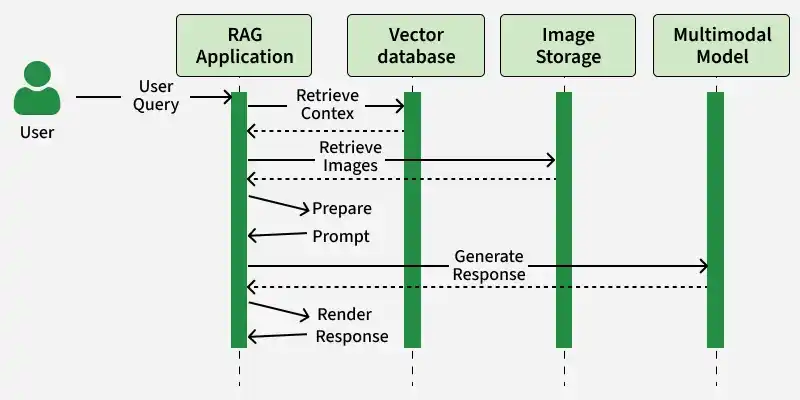
Multimodal RAG follows a structured pipeline that processes multiple data types and converts them into embeddings for efficient retrieval and generation.
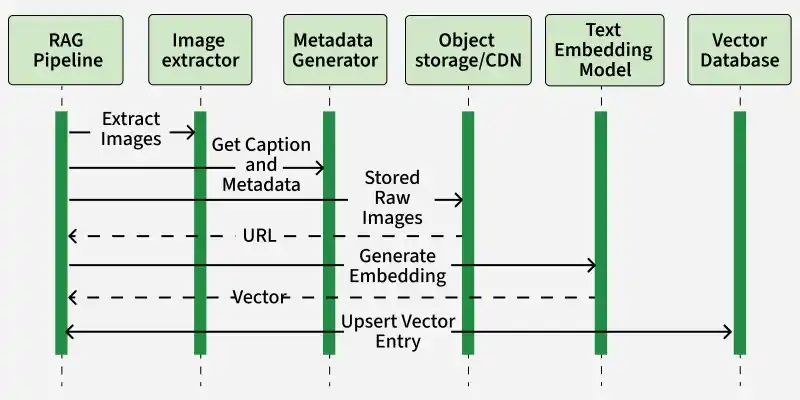
RAG Pipeline: controls the workflow. It pulls source documents (or user uploads) and hands off any embedded images to the next component.
Image Extractor: receives raw inputs, isolates each image and forwards them to the Metadata Generator.
Metadata Generator: creates a natural‑language caption and any other metadata for each image. It pushes the raw image files into an Object Storage or CDN then retrieves their public URLs.
Object Storage / CDN : stores the original images and returns stable URLs which the pipeline uses for downstream embedding.
Text Embedding Model: takes the captions or image URLs plus prompts and converts them into fixed‑size vectors.
Vector Database: inserts the embeddings with associated metadata and URLs into FAISS, ChromaDB, etc making them instantly searchable for later retrieval.
Define a dataset with text descriptions and corresponding image paths.
Generate text embeddings directly from descriptions.
Convert images into captions using the BLIP model.
Encode these captions into embeddings for further processing.
5. Build FAISS Index for Efficient Retrieval
Use FAISS to store embeddings for efficient similarity search.
Enables fast retrieval of both text and image embeddings.
6. Perform Query Search
Provide a text query to the system.
Retrieve the most relevant multimodal results (text and images) based on similarity.
Output:
Top 3 nearest MultiModal results: [[0 4 2]]
Indices [0, 4, 2] correspond to the most relevant results from Multimodal dataset based on the input query. Each index represents a combination of text and image data retrieved from the dataset.

{kind=link}
{kind=link}
{kind=link}
{kind=link}