The Transformers library, developed by Hugging Face, is an open source toolkit for working with advanced machine learning models across text, images, audio and multimodal data. It is widely used in NLP, computer vision and generative AI applications.
Provides access to pre-trained models.
Supports text, image, audio, and multimodal tasks.
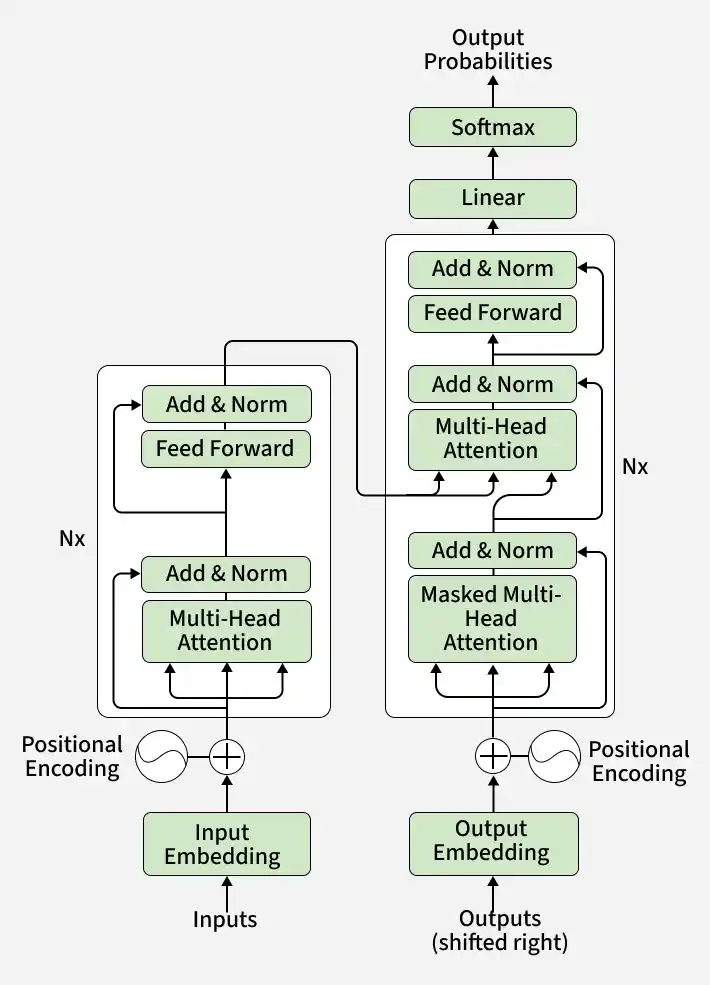
Transformer architecture is a neural network designed to process sequential data efficiently using self attention mechanisms. It follows an Encoder–Decoder structure, where the encoder learns representations from the input sequence and the decoder generates the output sequence.
Encoder: Extracts contextual information from the input data.
Decoder: Generates output by using information from the encoder.
Self-Attention: Captures relationships between different words or tokens in a sequence.
Feed-Forward Network: Processes and transforms the learned representations.
Residual Connections and Layer Normalization: Improve training stability and performance.
Key Components of the Transformers Library
1. Model Repository (Hugging Face Hub)
Provides access to millions of pre-trained models shared by the community and organizations.
Each model includes its weights, configuration files and tokenizer or preprocessor.
Allows users to easily download, share and fine-tune models for specific tasks.
2. Model Handling
Automatically loads the appropriate model architecture and pre-trained weights for a selected task.
Provides built in utilities for model training, fine-tuning, evaluation and optimization.
Allows users to add task specific layers or customize model outputs for specialized applications.
3. Tokenizers and Preprocessors
Provides efficient tokenization for handling text, special tokens and large vocabularies.
Includes fast tokenizers optimized for high performance processing.
Supports preprocessing for text, images and audio data.
Stores preprocessing configurations with models to ensure consistent and reproducible results.
Main Features of Transformers Library
1. Access to Pre-trained Models: Provides access to thousands of pre-trained models, including BERT, GPT, T5, Llama and Stable Diffusion, for a wide range of AI tasks.
2. Multi-Framework Support: Compatible with PyTorch, TensorFlow and JAX, allowing you to choose or switch frameworks as needed.
3. Support for Multiple Modalities
NLP: Sentiment analysis, translation, summarization, named entity recognition, question answering, text generation.
Multimodal: Tasks combining text, images, audio, tables and more.
4. Pipelines API: Offers the easy-to-use pipeline() function, which simplifies inference by automatically handling preprocessing and output generation.
5. Easy Fine-Tuning and Deployment: Provides tools for fine-tuning pre-trained models on custom datasets and deploying them efficiently in real world applications.
6. Integration with the Hugging Face Ecosystem : Integrates with the Hugging Face Hub, allowing users to access, share and deploy models and datasets easily.
Implementation
1. Install required libraries
Run the following command in you command prompt
pip install transformers
2. Import Required Libraries
Install the Transformers library and import the pipeline function.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}