Adam (Adaptive Moment Estimation) optimizer combines the advantages of Momentum and RMSprop techniques to adjust learning rates during training. It works well with large datasets and complex models because it uses memory efficiently and adapts the learning rate for each parameter automatically.
Working of Adam Optimizer
Adam combines two optimization techniques, Momentum and RMSProp, to achieve faster and more stable training.
1. Momentum
Momentum accelerates gradient descent by using a moving average of past gradients, helping reduce oscillations and speed up convergence. The update rule with momentum is:
where:
is the moving average of the gradients at time
is the learning rate
and are the weights at time and , respectively
The momentum term is updated recursively as:
where:
is the momentum parameter (typically set to 0.9)
is the gradient of the loss function with respect to the weights at time
2. RMSprop (Root Mean Square Propagation)
RMSprop is an adaptive learning rate optimization method that improves AdaGrad by using an exponentially weighted moving average of squared gradients. This prevents the learning rate from decreasing too quickly during training. The update rule for RMSprop is:
where:
is the exponentially weighted average of squared gradients:
is a small constant (e.g., ) added to prevent division by zero
Combining Momentum and RMSprop to form Adam Optimizer
Adam optimizer combines the momentum and RMSprop techniques to provide a more balanced and efficient optimization process. The key equations governing Adam are as follows:
First moment (mean) estimate:
Second moment (variance) estimate:
Bias correction: Since both and are initialized at zero, they tend to be biased toward zero, especially during the initial steps. To correct this bias, Adam computes the bias-corrected estimates:
Final weight update: The weights are then updated as:
Key Parameters
: The learning rate or step size (default is 0.001)
and : Decay rates for the moving averages of the gradient and squared gradient, typically set to and
: A small positive constant (e.g., ) used to avoid division by zero when computing the final update
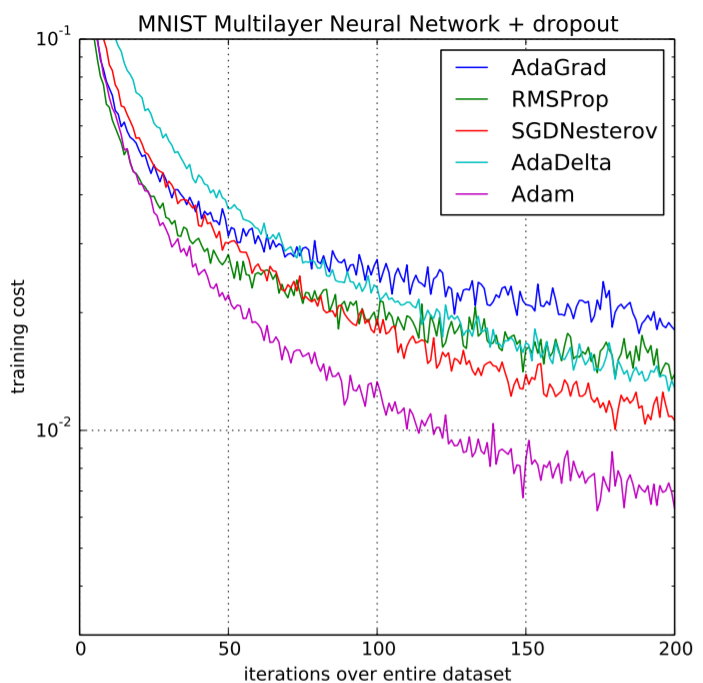
Performance of Adam Optimizer
Adam delivers strong performance in training deep learning models and large datasets by combining adaptive learning rates with momentum.
Uses adaptive learning rates for each parameter based on past gradients and their magnitudes
Helps reduce oscillations and move past local minima effectively
Applies bias correction to prevent instability during early training stages
Requires less hyperparameter tuning compared to optimizers like SGD
Provides efficient, stable, and reliable optimization across different tasks

{kind=link}
{kind=link}
{kind=link}
{kind=link}