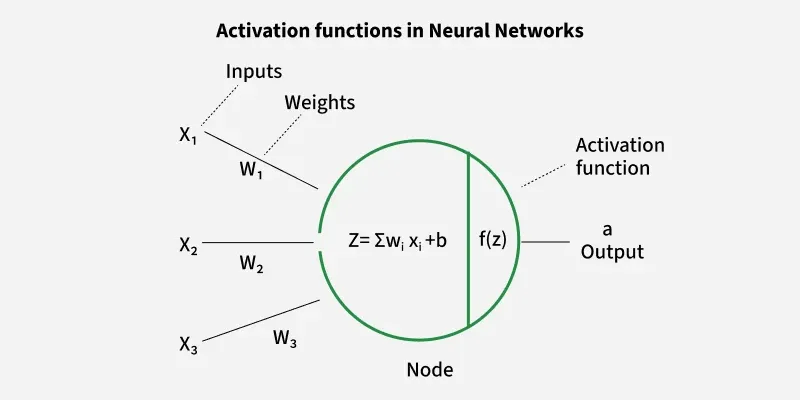
An activation function is applied to the weighted sum of inputs before producing the final output of a neuron. It introduces non-linearity, allowing the network to learn complex patterns.
Without it, the network behaves like a linear model
Importance of Non-Linearity
Real-world data is rarely linearly separable.
Non-linear functions allow neural networks to form curved decision boundaries, making them capable of handling complex patterns (e.g., classifying apples vs. bananas under varying colors and shapes).
They ensure networks can model advanced problems like image recognition, NLP and speech processing.
Mathematical Example
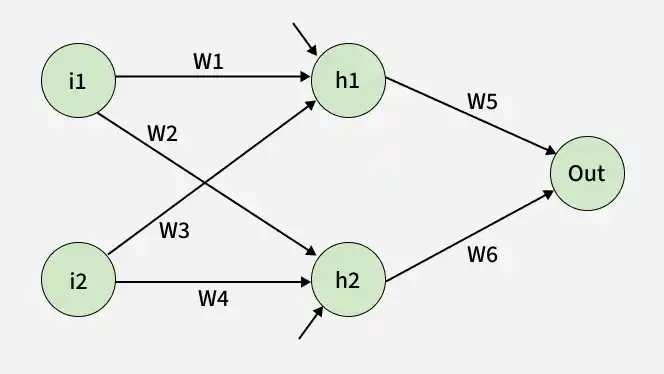
Consider a neural network with:
Inputs: i1, i2
Hidden layer: neurons h1 and h2
Output layer: one neuron (output)
Weights: w1, w2, w3, w4, w5, w6
Biases: b1 for hidden layer, b2 for output layer
Each circle represents a neuron (node) and a group of neurons forms a layer.
The hidden layer outputs are:
The output before activation is:
Without activation, these are linear equations.
To introduce non-linearity, we apply a sigmoid activation:
This gives the final output of the network after applying the sigmoid activation function in output layers, introducing the desired non-linearity.
Types of Activation Functions in Deep Learning
1. Linear Activation Function
Linear Activation Function resembles straight line define by y=x. No matter how many layers the neural network contains if they all use linear activation functions the output is a linear combination of the input.
The range of the output spans from .
Output is a linear combination of inputs
Using it in all layers makes the network behave like a linear model
Limits the ability to learn complex patterns
Commonly used in the output layer for regression tasks
Often combined with non-linear functions in hidden layers for better learning
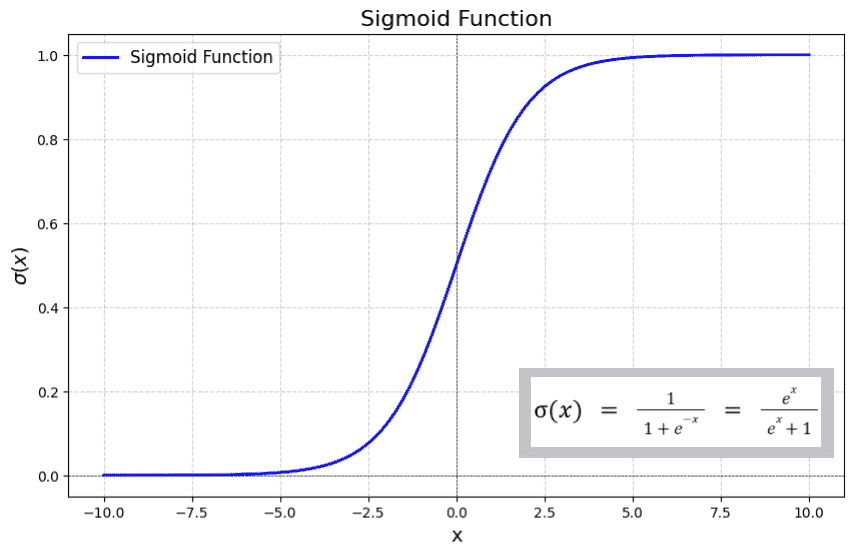
Sigmoid Activation Function is characterized by 'S' shape. It is mathematically defined as. This formula ensures a smooth and continuous output that is essential for gradient-based optimization methods.
It allows neural networks to handle and model complex patterns that linear equations cannot.
The output ranges between 0 and 1, hence useful for binary classification.
The function exhibits a steep gradient when x values are between -2 and 2. This sensitivity means that small changes in input x can cause significant changes in output y which is critical during the training process.
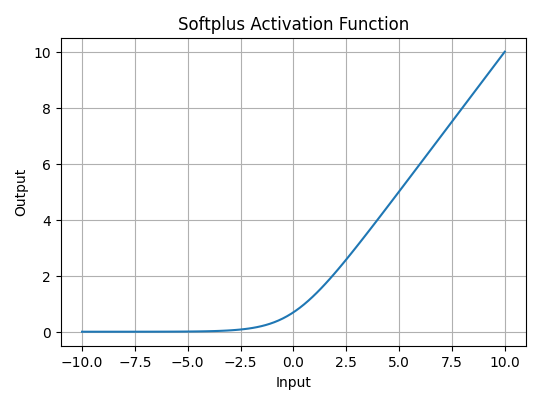
Softplus function is defined mathematically as: . It is similar to ReLU but avoids sharp transitions by being fully differentiable.
The Softplus function is non-linear.
The function outputs values in the range , similar to ReLU, but without the hard zero threshold that ReLU has.
Softplus is a smooth, continuous function, meaning it avoids the sharp discontinuities of ReLU which can sometimes lead to problems during optimization.
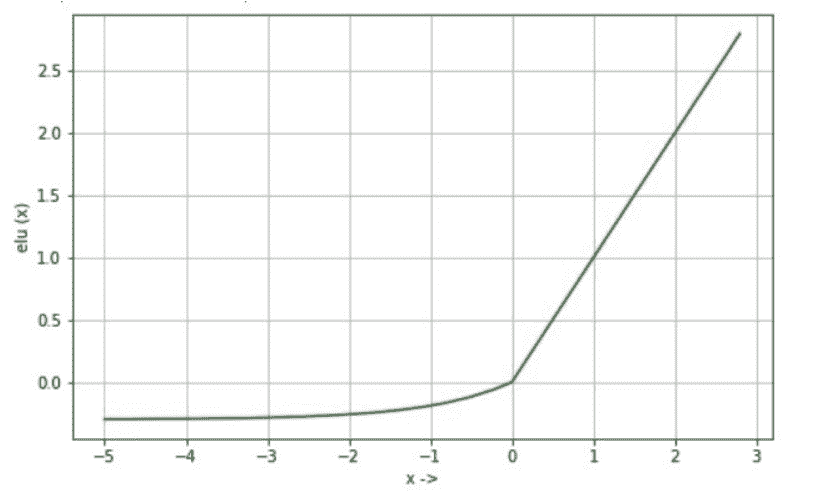
ELU (Exponential Linear Unit) is a non-linear activation function that improves learning speed and helps reduce the vanishing gradient problem. It behaves like ReLU for positive inputs but allows smooth negative values.
Output range is (−α,∞)(-\alpha, \infty)(−α,∞)
Introduces non-linearity for learning complex patterns
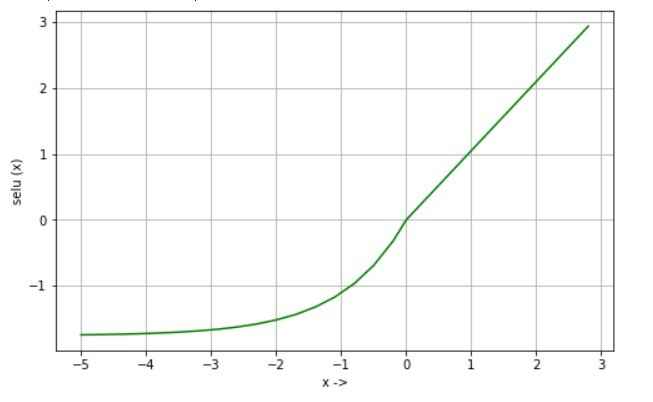
SELU is a scaled version of ELU designed for self-normalizing neural networks, helping maintain stable activations during training.
where λ ≈ 1.05 (scaling factor) and α ≈ 1.67
Output range is
Maintains near zero mean and unit variance (self-normalizing)
Helps prevent vanishing and exploding gradients
Works well in deep fully connected networks
Can reduce the need for batch normalization in some cases
👁 selu SELU (Scaled Exponential Linear Unit) Function
4. Output Layer Activation Functions
1. Sigmoid Activation Function
Sigmoid function produces an S-shaped curve and maps input values into a probability-like range between 0 and 1 and is used to find the final output of the neural network for binary classification problems. It is defined as:
Output range is (0,1)
Produces probability-like outputs
Commonly used in the output layer for binary classification
Smooth and differentiable, useful for gradient-based learning
Impact of Activation Functions on Model Performance
Activation functions play a key role in how efficiently a neural network learns and performs across different tasks.
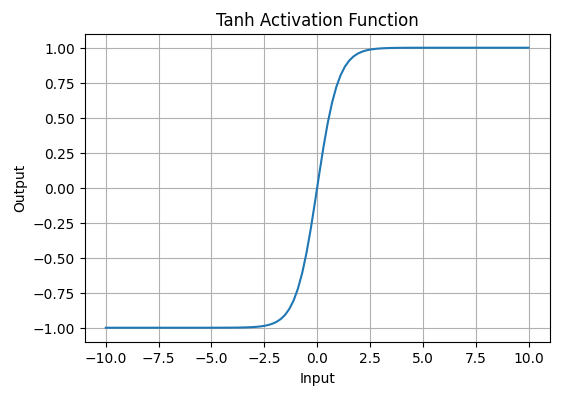
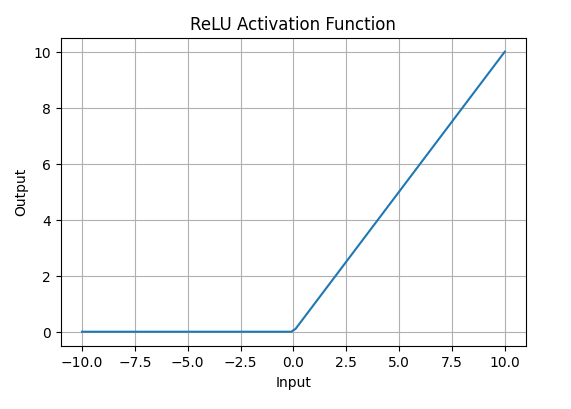
ReLU helps in faster training by avoiding the vanishing gradient problem, while Sigmoid and Tanh can slow down convergence in deep networks
ReLU maintains better gradient flow, allowing deeper layers to learn effectively, whereas Sigmoid may produce very small gradients
Softmax enables handling of multi-class classification problems, while functions like ReLU or Leaky ReLU are commonly used in hidden layers for efficient learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}