 |
VOOZH | about |
|
VOOZH | about |
A decision tree is a supervised learning algorithm used for both classification and regression tasks. It has a hierarchical tree structure which consists of a root node, branches, internal nodes and leaf nodes. It works like a flowchart that helps in making step-by-step decisions, where:
Decision trees are widely used due to their interpretability, flexibility and low preprocessing needs.
A decision tree splits the dataset based on feature values to create pure subsets ideally all items in a group belong to the same class. Each leaf node represents the final output, which can be a class label (in classification) or a continuous value (in regression). Let’s understand this with an example.
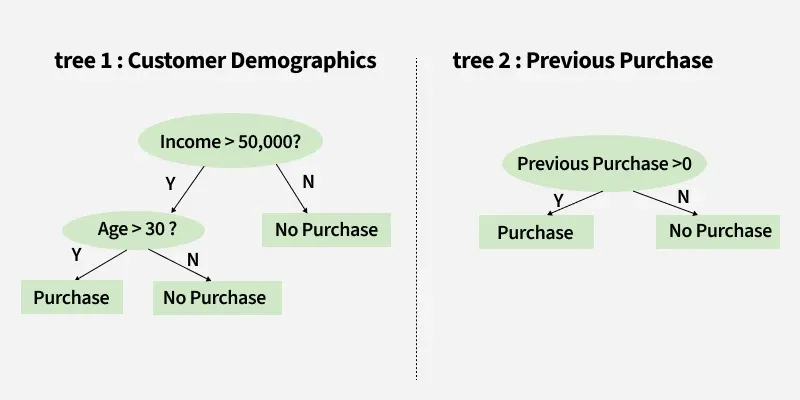
Let’s consider a decision tree for predicting whether a customer will buy a product based on age, income and previous purchases: Here's how the decision tree works:
1. Root Node (Income)
First Question: "Is the person’s income greater than $50,000?"
2. Internal Node (Age):
If the person’s income is greater than $50,000, ask: "Is the person’s age above 30?"
3. Internal Node (Previous Purchases):
Example: A decision tree makes predictions using a single tree structure by following decision paths from root to leaf.
First tree asks two questions:
1. "Income > $50,000?"
2. "Age > 30?"
"Previous Purchases > 0?"
Once we have predictions from both trees, we can combine the results to make a final prediction. If Tree 1 predicts "Purchase" and Tree 2 predicts "No Purchase", the final prediction might be "Purchase" or "No Purchase" depending on the weight or confidence assigned to each tree. This can be decided based on the problem context.
Till now we have discovered the basic intuition and approach of how decision tree works, so let's just move to the attribute selection measure of decision tree. We have two popular attribute selection measures used:
Information Gain tells us how useful a question (or feature) is for splitting data into groups. It measures how much the uncertainty decreases after the split. A good question will create clearer groups and the feature with the highest Information Gain is chosen to make the decision.
For example if we split a dataset of people into "Young" and "Old" based on age and all young people bought the product while all old people did not, the Information Gain would be high because the split perfectly separates the two groups with no uncertainty left
For example if a dataset has an equal number of "Yes" and "No" outcomes (like 3 people who bought a product and 3 who didn’t), the entropy is high because it’s uncertain which outcome to predict. But if all the outcomes are the same (all "Yes" or all "No") the entropy is 0 meaning there is no uncertainty left in predicting the outcome
Suppose is a set of instances, is an attribute, is the subset of with = and Values () is the set of all possible values of , then
Example:
For the set X = {a,a,a,b,b,b,b,b}
Total instances: 8
Instances of b: 5
Instances of a: 3
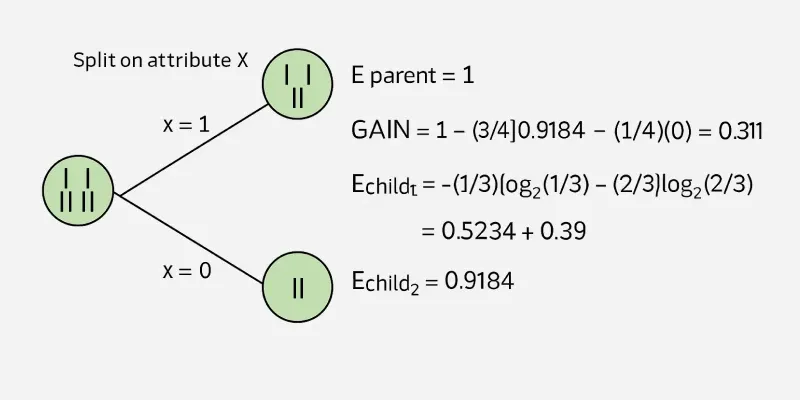
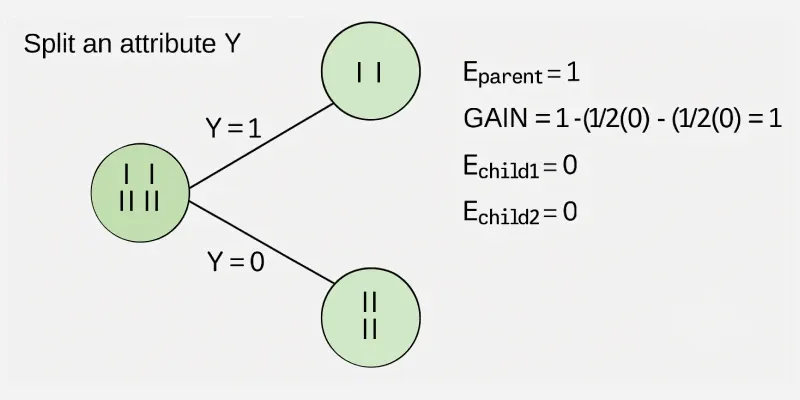
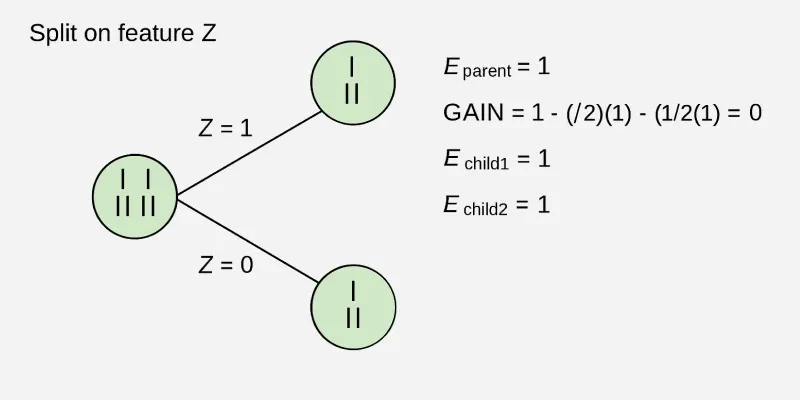
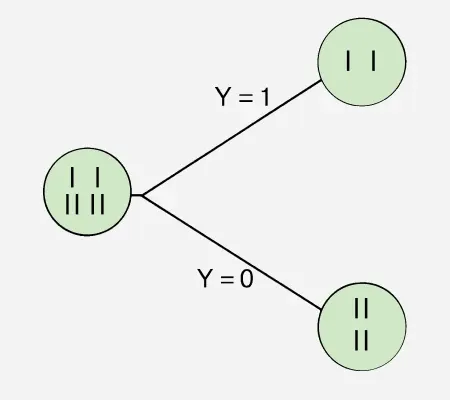
Example: Now let us draw a Decision Tree for the following data using Information gain. Training set: 3 features and 2 classes
| X | Y | Z | C |
|---|---|---|---|
| 1 | 1 | 1 | I |
| 1 | 1 | 0 | I |
| 0 | 0 | 1 | II |
| 1 | 0 | 0 | II |
Here, we have 3 features and 2 output classes. To build a decision tree using Information gain. We will take each of the features and calculate the information for each feature.
Gini Index is a metric to measure how often a randomly chosen element would be incorrectly identified. It means an attribute with a lower Gini index should be preferred. Sklearn supports “Gini” criteria for Gini Index and by default it takes “gini” value.
For example if we have a group of people where all bought the product (100% "Yes") the Gini Index is 0 indicate perfect purity. But if the group has an equal mix of "Yes" and "No" the Gini Index would be 0.5 show high impurity or uncertainty. Formula for Gini Index is given by :
Till now we have understood about the attributes and components of decision tree. Now lets jump to a real life use case in which how decision tree works step by step.
We begin with all the data which is treated as the root node of the decision tree.
Pick the best question to divide the dataset. For example ask: "What is the outlook?"
Possible answers: Sunny, Cloudy or Rainy.
Divide the dataset into groups based on the question:
For each subset ask another question to refine the groups. For example If the Sunny subset is mixed ask: "Is the humidity high or normal?"
When a subset contains only one activity, stop splitting and assign it a label:
To predict an activity follow the branches of the tree. Example: If the outlook is Sunny and the humidity is High follow the tree:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}