 |
VOOZH | about |
|
VOOZH | about |
Linear Regression is a fundamental supervised learning algorithm used to model the relationship between a dependent variable and one or more independent variables. It predicts continuous values by fitting a straight line that best represents the data.
For example, suppose we want to predict a student’s exam score based on the number of hours studied. As study hours increase, exam scores generally increase as well. Here:
Linear regression uses the independent variable to predict the dependent variable.
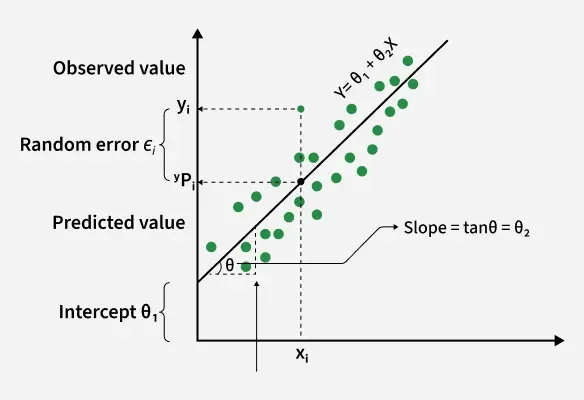
In linear regression, the best-fit line is the straight line that best represents the relationship between the independent variable (input) and the dependent variable (output). The goal is to minimize the difference between the actual data points and the predicted values generated by the model.
The goal of linear regression is to find a straight line that minimizes the error (the difference) between the observed data points and the predicted values. This line helps us predict the dependent variable for new, unseen data.
Here Y is called a dependent or target variable and X is called an independent variable also known as the predictor of Y.
There are many types of functions or modules that can be used for regression. A linear function is the simplest type of function. Here, X may be a single feature or multiple features representing the problem.
For simple linear regression (with one independent variable), the best-fit line is represented by the equation
Where:
The best-fit line will be the one that optimizes the values of m (slope) and b (intercept) so that the predicted y values are as close as possible to the actual data points.
To determine the best-fit line, linear regression uses the Least Squares Method, which minimizes the difference between actual and predicted values. These differences are called residuals. These differences are called residuals.
The formula for residuals is:
Residual =
Where:
The least squares method minimizes the sum of the squared residuals:
This method ensures that the line best represents the data where the sum of the squared differences between the predicted values and actual values is as small as possible.
In linear regression some hypothesis are made to ensure reliability of the model's results.
Limitations:
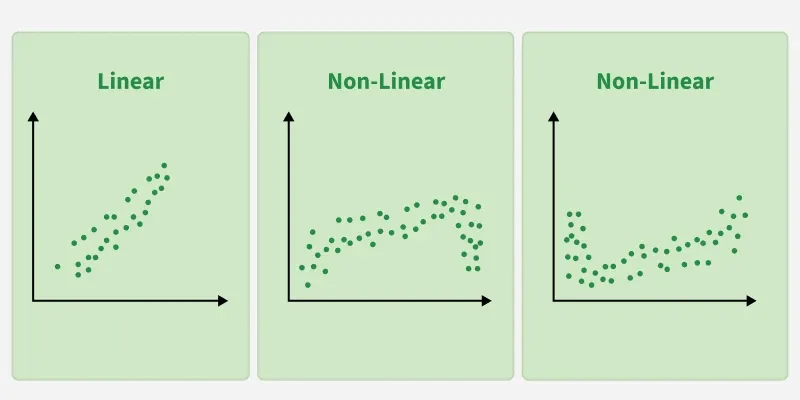
- Assumes Linearity: The method assumes the relationship between the variables is linear. If the relationship is non-linear, linear regression might not work well.
- Sensitivity to Outliers: Outliers can significantly affect the slope and intercept, skewing the best-fit line.
In linear regression, the hypothesis function is the equation used to make predictions about the dependent variable based on the independent variables. It represents the relationship between the input features and the target output.
For a simple case with one independent variable, the hypothesis function is:
Where:
For multiple linear regression (with more than one independent variable), the hypothesis function expands to:
Where:
In Linear Regression, the cost function measures how far the predicted values are from the actual values (Y). It helps identify and reduce errors to find the best-fit line. The most common cost function used is Mean Squared Error (MSE), which calculates the average of squared differences between actual and predicted values.
Here:
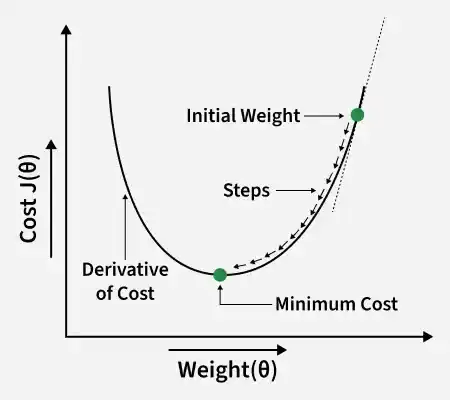
Gradient descent is an optimization technique used to train a linear regression model by minimizing the prediction error. It works by starting with random model parameters and repeatedly adjusting them to reduce the difference between predicted and actual values.
How it works:
This helps the model find the best-fit line for the data.
When there is only one independent feature it is known as Simple Linear Regression or Univariate Linear Regression and when there are more than one feature it is known as Multiple Linear Regression or Multivariate Regression.
Simple linear regression is used when we want to predict a target value (dependent variable) using only one input feature (independent variable). It assumes a straight-line relationship between the two.
Formula:
Where:
Example: Predicting a person’s salary (y) based on their years of experience (x).
Multiple linear regression involves more than one independent variable and one dependent variable. The equation for multiple linear regression is:
Where:
The goal is to find the best-fit line that predicts Y accurately for given inputs X.
Use Cases:
1. Linearity: The relationship between inputs (X) and the output (Y) is a straight line.
2. Independence of Errors: The errors in predictions should not affect each other.
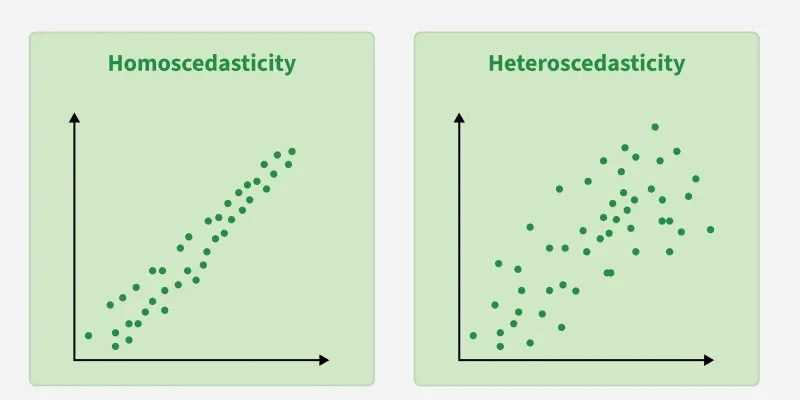
3. Constant Variance (Homoscedasticity): The errors should have equal spread across all values of the input. If the spread changes (like fans out or shrinks), it's called heteroscedasticity and it's a problem for the model.
4. Normality of Errors: The errors should follow a normal (bell-shaped) distribution.
5. No Multicollinearity (for multiple regression): Input variables shouldn’t be too closely related to each other.
6. No Autocorrelation: Errors shouldn't show repeating patterns, especially in time-based data.
7. Additivity: The total effect on Y is just the sum of effects from each X, no mixing or interaction between them.
To understand Multicollinearity in detail refer to this article: Multicollinearity.
A variety of evaluation measures can be used to determine the strength of any linear regression model. These assessment metrics often give an indication of how well the model is producing the observed outputs.
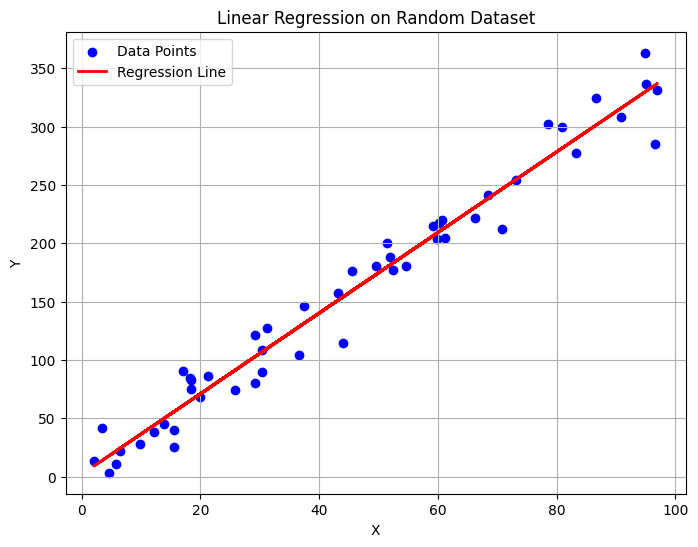
Importing NumPy for numerical operations, Matplotlib for visualization, and Scikit-learn for building the linear regression model.
Creating a sample input and output data for training the linear regression model.
Initialize the model and train it using the generated dataset.
Using the trained model to predict output values for the input data.
Plot the original data points along with the best-fit regression line.
Output:
Print the learned slope and intercept values of the regression model.
Output:
Slope (Coefficient): 3.4553132007706204
Intercept: 1.9337854893777546
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}