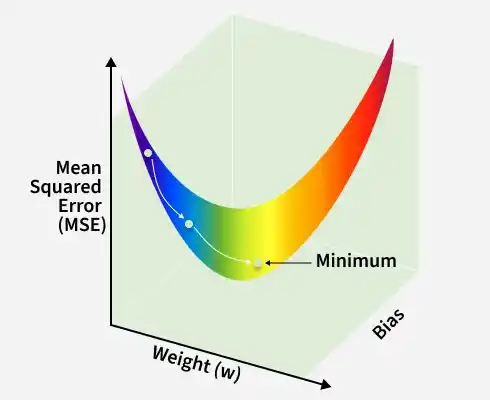
Gradient Descent is an optimization algorithm used to minimize the error of a machine learning model by updating parameters in the direction of decreasing loss.
Linear Regression is a supervised learning algorithm used to predict continuous numerical values by modeling the relationship between input variables and the output using a best-fit line.
Gradient Descent helps the Linear Regression model find the best values of weight and bias so that the prediction error becomes as small as possible. It starts with random values and gradually adjusts them in the direction that reduces the loss.
Calculates how the loss changes with respect to weight and bias
Updates these parameters step by step to reduce prediction error
Repeats the process until the loss becomes very small and the best line is found
Implementation
Creates a dataset: Generates 200 sample data points with some random noise.
Initializes parameters: Starts with initial values for weight and bias, and sets the learning rate and number of iterations.
Trains the model: In each iteration, the model makes predictions, calculates the error and updates the parameters using Gradient Descent.
Tracks the loss: Stores the loss value in every iteration to observe how the error changes.
Plots the loss graph: Shows how the error decreases over iterations.
Plots the fitted line: Displays the data points along with the final regression line learned by the model.
Output:
2. Logistic Regression
Logistic Regression is a supervised learning algorithm used for binary classification, predicting the probability that a data point belongs to a specific class.
Used for binary classification tasks
Outputs probabilities between 0 and 1 using the sigmoid function
Converts probabilities into class labels (e.g., 0 or 1)
Gradient descent helps logistic regression find optimal parameter values by reducing prediction error over time.
Computes how cross-entropy loss changes with respect to model parameters
Updates parameters step by step to improve probability predictions
Iteratively reduces loss until the model converges to better performance
Implementation
Creates a dataset: Generates sample data with two classes.
Trains the model using Gradient Descent: The model predicts probabilities, calculates the error using cross entropy loss and updates the weights and bias to reduce the loss.
Shows learning progress: Plots a graph of loss vs iterations to show how the error decreases during training.
Shows the final classification boundary: Displays the data points and the decision boundary learned by the model.
Output:
3. Softmax Regression
Softmax Regression is an extension of logistic regression used for multi-class classification, predicting probabilities across multiple classes.
Gradient descent helps the softmax regression model learn optimal parameters by reducing prediction error and improving class probabilities.
Computes how multiclass cross-entropy loss changes with respect to the weights
Updates weights step by step to improve probability of the correct class
Iteratively reduces loss until the model achieves better performance
Implementation
Creates a dataset: Generates sample data with three different classes.
Trains the model using Gradient Descent: The model calculates class probabilities using the softmax function, computes the error using cross entropy loss and updates the weights and bias to reduce the loss.
Shows learning progress: Plots a graph of loss vs iterations to show how the error decreases during training.
Shows the final class regions: Displays the data points and the regions learned by the model for each class.
Output:
4.Neural Network
A neural network with one hidden layer can learn complex patterns that linear models cannot capture by introducing non-linearity through activation functions.
Uses a hidden layer to model complex relationships
Applies activation functions like ReLU for non-linearity
Uses softmax in the output layer to predict class probabilities
Gradient descent helps a neural network learn optimal weights by reducing prediction error, working together with backpropagation to improve performance.
Uses gradients from backpropagation to update weights in each layer
Adjusts weights step by step to reduce prediction error
Iteratively improves learning until the model captures better patterns
Implementation
Creates the dataset and neural network: Generates data with three classes and builds a neural network with one hidden layer.
Trains the model: The network makes predictions, calculates the loss and updates the weights using backpropagation and Gradient Descent.
Shows the results: Plots the training loss over epochs and displays the decision regions learned by the neural network.
Output:
5. Support Vector Machine
A Support Vector Machine is a supervised learning algorithm used for classification and regression that finds the best boundary to separate data points.
Creates a decision boundary (hyperplane) to separate classes
Maximizes the margin between different classes
Uses support vectors (critical data points) to define the boundary
Applies hinge loss to penalize incorrect or close predictions
Where:
: weight vector
: bias term
: input
: class label
: regularization strength
: hinge loss
: total SVM objective
Role of Gradient Descent
Gradient Descent helps the SVM model find the best parameters so that the classification boundary separates the classes as clearly as possible. It adjusts the parameters by reducing hinge loss and improving the margin between classes.
Updates the model parameters to reduce hinge loss
Adjusts the boundary when points are misclassified or too close to it
Repeats the process to improve the margin and classification accuracy
Implementation
Creates a dataset: Generates sample data with two classes and converts labels into values suitable for SVM training.
Trains the SVM using Gradient Descent: Calculates hinge loss, updates the model parameters step by step and improves the decision boundary during training.
Shows the results: Plots the objective value over iterations and displays the final decision boundary separating the two classes.
Output:
6. Matrix Factorization
Matrix Factorization is used in recommender systems to find hidden patterns in user item ratings. It breaks the rating matrix into smaller latent factors representing user preferences and item features, which are used to predict missing ratings.
Reconstruction:
Loss:
Where:
: rating matrix
: user latent matrix
: item latent matrix
: observed user-item pairs
: actual rating
: predicted rating
: regularization strength
: reconstruction loss
Role of Gradient Descent
Gradient Descent helps the Matrix Factorization model learn the best user and item factors so that the predicted ratings become closer to the actual ratings. It:
Updates user and item latent vectors using observed ratings
Reduces the difference between predicted and actual ratings
Repeats the process to learn better user and item representations
Implementation
Creates a rating dataset: Generates a user item rating matrix and keeps only some ratings as observed data.
Trains the model using Gradient Descent: Updates user and item latent factors using the observed ratings to reduce prediction error.
Shows learning progress: Plots the loss over epochs to show how the reconstruction error decreases.
Shows the reconstructed matrix: Displays the observed ratings and the reconstructed full matrix learned by the model.

{kind=link}
{kind=link}
{kind=link}