Multiclass classification is a supervised machine learning task in which each data instance is assigned to one class from three or more possible categories. In scikit-learn, implementing multiclass classification involves preparing the dataset, selecting the appropriate algorithm, training the model and evaluating its performance. Common multiclass classifiers include Decision Tree, Support Vector Machine (SVM), K-Nearest Neighbors (KNN) and Naive Bayes, each offering a different approach for handling multiple class labels within the data. Real-world examples include digit recognition, species identification and product categorization.
Features: Measurable properties of instances (e.g., flower petal length).
Labels/Classes: Discrete categories (e.g., 'setosa', 'versicolor', 'virginica' in the Iris dataset).
Step-by-Step Implementation
Let's see the step-by-step implementation of Multiclass Classification along with various classifiers,
Step 1: Import Libraries
We will import the required libraries,
sklearn.datasets: Provides standard datasets (like iris) useful for testing and practicing ML methods.
sklearn.model_selection.train_test_split: This function splits arrays or matrices into random train and test subsets, enabling fair evaluation of models.
sklearn.metrics.accuracy_score, confusion_matrix: Tools for evaluating the correctness of model predictions; accuracy measures percent correct, confusion matrix details classification mistakes.
matplotlib.pyplot: A plotting library for creating static, interactive and animated visualizations in Python.
seaborn: A high-level data visualization library built on matplotlib; it helps produce visually appealing statistical graphics (like heatmaps).
Step 2: Load and Explore the Dataset
The Iris dataset is a famous collection of 150 flower samples, representing three Iris species, setosa, versicolor and virginica. Each sample has four numeric features: sepal length, sepal width, petal length and petal width.
iris.data is a 2D NumPy array of shape (150, 4), where each row represents a single flower’s measured features.
iris.target is a 1D array of length 150, where each entry is an integer (0, 1 or 2) that denotes the species label for the corresponding row in iris.data.
Step 3: Split the Data
We will split the data for training and testing,
train_test_split separates the feature (X) and label (y) arrays into training and testing sets. Here, 70% of the data is used to train the models (X_train, y_train) and 30% is used to evaluate them (X_test, y_test).
Setting random_state ensures we always get the same split, allowing reproducibility.
Step 4: Model Training and Visualization
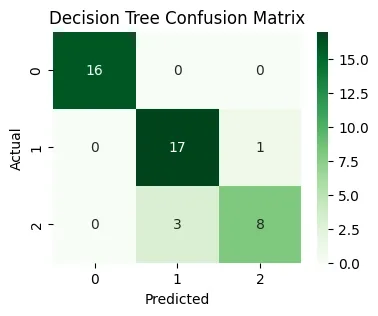
1. Decision Tree Classifier:Decision Tree Classifier is a model that predicts class labels by learning simple decision rules arranged in a tree structure, where each node makes a decision based on a feature until a class label is assigned at the leaf.
Instantiates the classifier object, setting a limit of 2 for tree depth.
.fit(X_train, y_train) trains the model using the training data.
.predict(X_test) generates predicted labels for the test data.
accuracy_score(y_test, dtree_preds) computes how many test samples were correctly classified.
confusion_matrix(y_test, dtree_preds) gives a table indicating, for each actual class, how many times the model predicted each possible class.
The seaborn heatmap visualizes which classes the model predicts well or struggles with.
2. Support Vector Machine(SVM) Classifier: Support Vector Machine Classifier is a model that separates data into classes by finding the optimal hyperplane that maximizes the margin between different class groups in the feature space.
Creates a linear SVC (Support Vector Classifier) object.
Fits the model with training data.
Predicts test set labels.
Calculates accuracy and confusion matrix.
Visualizes the confusion matrix, showing per-class predictions.
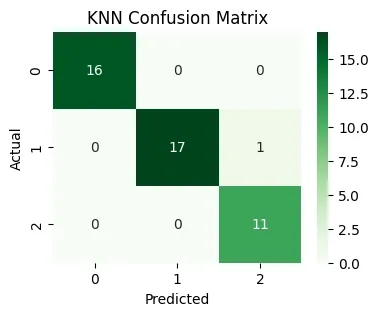
3. K-Nearest Neighbors(KNN) Classifiers:k-Nearest Neighbors Classifier is a model that classifies a data point by looking at the majority class among its k-nearest neighbors, based on distance in feature space.
Sets up a KNN classifier to consider 7 neighbors.
Models the training data (essentially, stores it).
Predicts the labels by 'voting' among the nearest neighbors.
Derives accuracy and confusion statistics.
Plots the confusion matrix to visualize strengths and errors in class assignment.
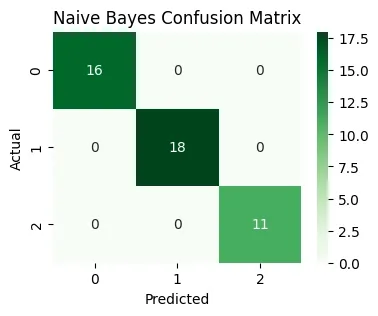
4. Naive Bayes Classifier:Naive Bayes Classifier is a probabilistic model based on Bayes' theorem, which assumes that features are independent given the class and predicts the most probable class for new data.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}