 |
VOOZH | about |
|
VOOZH | about |
ECLAT stands for Equivalence Class Clustering and bottom-up Lattice Traversal. It is a data mining algorithm used to find frequent itemsets in a dataset. These frequent itemsets are then used to create association rules which helps to identify patterns in data. It is an improved alternative to the Apriori algorithm by providing better scalability and computational efficiency.
The main difference between the two lies in how they store and search through the data:
This vertical approach significantly reduces the number of database scans making ECLAT faster and more memory-efficient especially for large datasets.
Aspect | Apriori | ECLAT |
|---|---|---|
Data Format | Horizontal (transactions as rows) | Vertical (items linked to transaction IDs) |
Search Strategy | Breadth-First Search (BFS) | Depth-First Search (DFS) |
Database Scans | Multiple scans required | Fewer scans needed |
Memory Efficiency | Less memory-efficient | More memory-efficient |
Speed | Slower, especially with large datasets | Faster due to vertical representation |
Let’s walk through an example to better understand how ECLAT algorithm works. Consider the following transaction dataset represented in a Boolean matrix:
Transaction ID | Bread | Butter | Milk | Coke | Jam |
|---|---|---|---|---|---|
T1 | 1 | 1 | 0 | 0 | 1 |
T2 | 0 | 1 | 0 | 1 | 0 |
T3 | 0 | 1 | 1 | 0 | 0 |
T4 | 1 | 1 | 0 | 1 | 0 |
T5 | 1 | 0 | 1 | 0 | 0 |
T6 | 0 | 1 | 1 | 0 | 0 |
T7 | 1 | 0 | 1 | 0 | 0 |
T8 | 1 | 1 | 1 | 0 | 1 |
T9 | 1 | 1 | 1 | 0 | 0 |
The core idea of the ECLAT algorithm is based on the interaction of datasets to calculate the support of itemsets, avoiding the generation of subsets that are not likely to exist in the dataset. Here’s a breakdown of the steps:
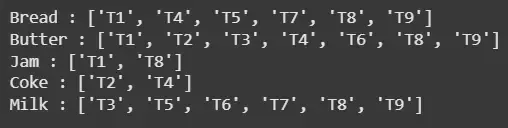
The first step is to generate the tidset for each individual item. A tidset is simply a list of transaction IDs where the item appears. For example: k = 1, minimum support = 2
| Item | Tidset |
|---|---|
| Bread | {T1, T4, T5, T7, T8, T9} |
| Butter | {T1, T2, T3, T4, T6, T8, T9} |
| Milk | {T3, T5, T6, T7, T8, T9} |
| Coke | {T2, T4} |
| Jam | {T1, T8} |
ECLAT then proceeds by recursively combining the tidsets. The support of an itemset is determined by the intersection of tidsets. For example: k = 2
| Item | Tidset |
|---|---|
| {Bread, Butter} | {T1, T4, T8, T9} |
| {Bread, Milk} | {T5, T7, T8, T9} |
| {Bread, Coke} | {T4} |
| {Bread, Jam} | {T1, T8} |
| {Butter, Milk} | {T3, T6, T8, T9} |
| {Butter, Coke} | {T2, T4} |
| {Butter, Jam} | {T1, T8} |
| {Milk, Jam} | {T8} |
The algorithm continues recursively by combining pairs of itemsets (k-itemsets) checking the support by intersecting the tidsets. The recursion continues until no further frequent itemsets can be generated. Now k = 3
| Item | Tidset |
|---|---|
| {Bread, Butter, Milk} | {T8, T9} |
| {Bread, Butter, Jam} | {T1, T8} |
The algorithm stops once no more itemset combinations meet the minimum support threshold. k = 4
| Item | Tidset |
|---|---|
| {Bread, Butter, Milk, Jam} | {T8} |
We stop at k = 4 because there are no more item-tidset pairs to combine. Since minimum support = 2, we conclude the following rules from the given dataset:-
| Items Bought | Recommended Products |
|---|---|
| Bread | Butter |
| Bread | Milk |
| Bread | Jam |
| Butter | Milk |
| Butter | Coke |
| Butter | Jam |
| Bread and Butter | Milk |
| Bread and Butter | Jam |
Let's see how ECLAT Algorithm works with the help of an example,
We will import necessary libraires and provide the dataset.
Output:
Recursively build larger itemsets by intersecting tidsets (depth-first). How it works:
Data structure: we use frequent_itemsets dict with frozenset(itemset) -> support_count.
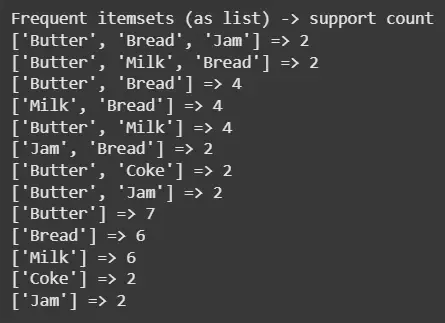
Call the recursive function, then inspect the found frequent itemsets (with support counts).
Output:
{kind=link}
{kind=link}
{kind=link}