Categorical Cross-Entropy in Multi-Class Classification
Last Updated : 25 Nov, 2025
Categorical Cross-Entropy is widely used as a loss function to measure how well a model predicts the correct class in multi-class classification problems. It measures the difference between the predicted probability distribution and the true one-hot encoded labels, guiding the model to assign higher probabilities to the correct class.
It is used when there are more than two classes.
Works with softmax outputs where probabilities sum to 1.
Higher loss means the prediction is far from the true class, lower loss means the model is performing well.
Commonly used in image classification, text classification and speech recognition tasks.
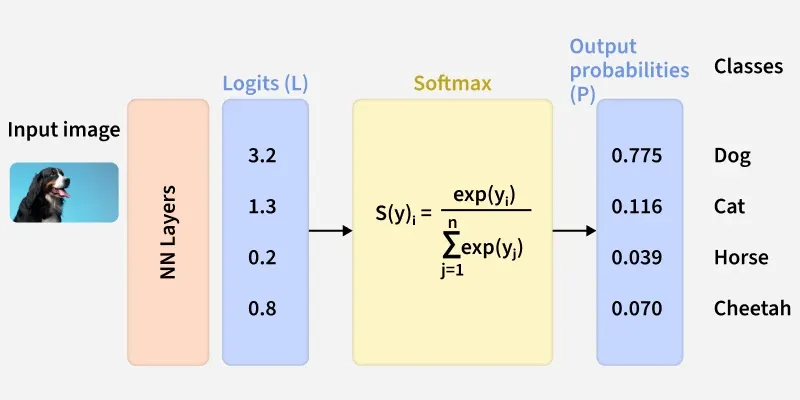
Here we see how neural networks are converted into Softmax probabilities and used in Categorical Cross-Entropy (CCE) to compute loss for the true class.
How Categorical Cross-Entropy Works
Categorical Cross-Entropy measures the difference between the true labels and the predicted probabilities of a model. It penalizes the model when it assigns low confidence to the correct class. Formula is:
where
: Categorical Cross-Entropy loss
: True label for class
: Predicted probability for class
: Number of classes
Categorical Cross-Entropy works through the following steps
Prediction of Probabilities: The model uses a Softmax layer to convert raw logits into probabilities for each class.
Comparison with True Class: Predicted probabilities are matched with one-hot encoded labels to determine the correct class.
Calculation of Loss: CCE calculates the negative log of the predicted probability for the true class, giving lower loss for higher confidence and higher penalty for low confidence.
Step-By-Step Implementation
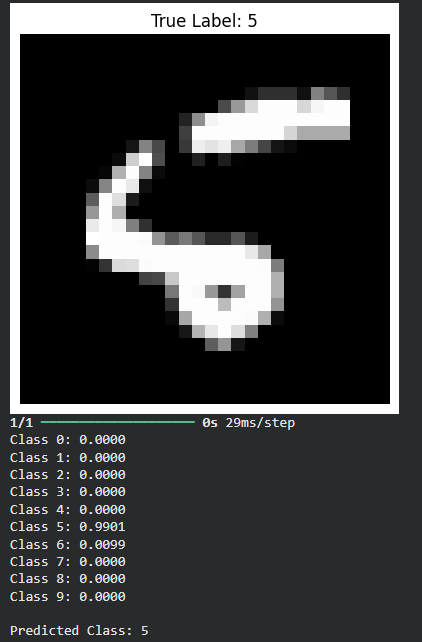
Here in this code we will train a neural network on the MNIST dataset using Categorical Cross-Entropy loss for multi-class classification. It allows predicting any test image and displays the probability of each class along with the predicted label.

{kind=link}
{kind=link}
{kind=link}