 |
VOOZH | about |
|
VOOZH | about |
Machine translation is the process of converting text from one language to another using AI models. Modern systems, such as Google Translate, rely on advanced architectures like Transformers to understand and generate accurate translations.
Transformer are deep learning models widely used in NLP because they can capture relationships between words, even when they are far apart in a sentence.
Transformers have improved the quality and efficiency of machine translation models. Here we will be using hugging Face's transformer models to perform English to Hindi translation.
Before starting make sure that we have the required libraries installed in our environment. If not then use the following commands to install them:
We will use cfilt/iitb-english-hindi dataset available on Hugging face.
Load the dataset from Hugging Face. It provides splits like "train", "validation" and "test" which we will use to train and evaluate our model.
We will be using the pre-trained model Helsinki-NLP/opus-mt-en-hi for English to Hindi translation. The AutoTokenizer and AutoModelForSeq2SeqLM classes from the Hugging Face transformers library allow us to load the tokenizer and model. The tokenizer converts text to tokens and the model performs the translation.
Test the model with a sentence from the validation set. The input sequence is: 'Rajesh Gavre, the President of the MNPA teachers association, honoured the school by presenting the award'.
Output:
'एमएनएपी शिक्षकों के राष्ट्रपति, राजस्वीवर ने इस पुरस्कार को पेश करके स्कूल की प्रतिष्ठा की'
Let's check the expected output using the following code.
Output:
'मनपा शिक्षक संघ के अध्यक्ष राजेश गवरे ने स्कूल को भेंट देकर सराहना की।'
To fine-tune the model, we need to preprocess the dataset. This involves tokenizing both the input (English) and target (Hindi) sentences and check that they are properly formatted for the model.
We map each of the examples of our dataset using the map function.
DataCollatorForSeq2Seq helps to batch the tokenized data with proper padding and formatting for seq2seq training. It handles tasks such as padding sequences to the maximum length in a batch helps in creating attention masks and organizing the data.
To fine-tune the model, we need to specify training parameters. In this case, we freeze some layers and train only the last few layers to fine-tune the model effectively.
We use SacreBLEU for evaluating the model's performance. BLEU (Bilingual Evaluation Understudy) is a metric used for evaluating machine translation models.
We define the training parameters using Seq2SeqTrainingArguments from Hugging Face.
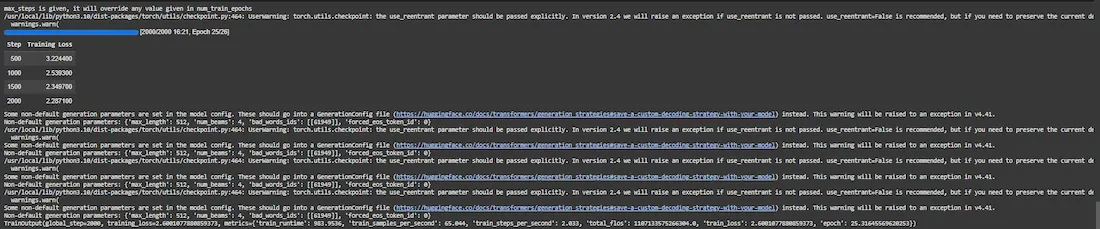
We start training with Seq2SeqTrainer.
Output:
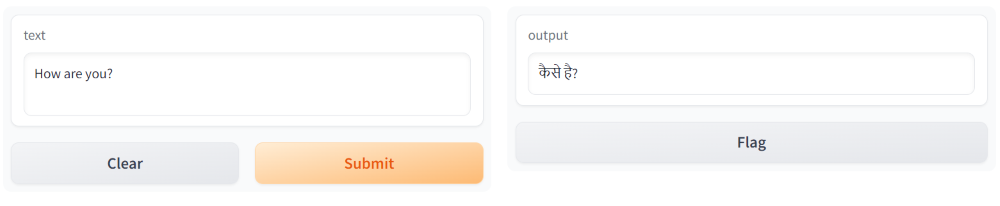
We can create an interactive Gradio app to translate English sentences to Hindi.
Output:
Get complete Notebook Link from here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}