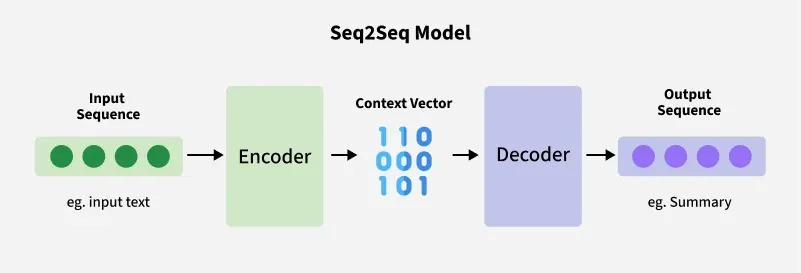
Sequence‑to‑Sequence (Seq2Seq) models are neural networks designed to transform one sequence into another, even when the input and output lengths differ and are built using encoder‑decoder architecture.
It processes an input sequence and generates a corresponding output sequence.
Handles variable‑length input and output sequences
It is used in NLP, machine translation, speech recognition and time-series prediction.
Both the input and the output are treated as sequences of varying lengths and the model is composed of two parts:
1. Encoder:
Processes the input sequence token by token.
Encodes the entire sequence into a fixed-length context vector (or a series of hidden states) that summarizes the important information from the input.
2. Decoder:
Takes the context vector as input.
Generates the output sequence one token at a time, predicting each token based on the context vector and previously generated tokens.
The model is commonly used in tasks where there is a need to map sequences of varying lengths such as converting a sentence in one language to another or predicting a sequence of future events based on past data i.e time-series forecasting.
Seq2Seq with RNNs
In the simplest Seq2Seq model RNNs are used in both the encoder and decoder to process sequential data. For a given input sequence , a RNN generates a sequence of outputs through iterative computation based on the following equation:
Here
represents hidden state at time step t
represents input at time step t
and represents the weight matrices
represents hidden state from the previous time step (t-1)
represents the the activation function (commonly tanh for RNN hidden states).
represents output at time step t
Limitations of Vanilla RNNs:
Vanilla RNNs struggle with long-term dependencies due to the vanishing gradient problem.
To overcome this, advanced RNN variants like LSTM (Long Short-Term Memory) or GRU (Gated Recurrent Unit) are used in Seq2Seq models. These architectures are better at capturing long-range dependencies.
How Does the Seq2Seq Model Work?
A Sequence-to-Sequence (Seq2Seq) model consists of two primary phases: encoding the input sequence and decoding it into an output sequence.
1. Encoding the Input Sequence
The encoder processes the input sequence token by token, updating its internal state at each step.
After processing the entire sequence, the encoder produces a context vector i.e a fixed-length representation summarizing the important information from the input.
2. Decoding the Output Sequence
The decoder takes the context vector and generates the output sequence one token at a time. For example, in machine translation:
Input: "I am learning"
Output: "Je suis apprenant"
Each token is predicted based on the context vector and previously generated tokens.
3. Teacher Forcing
During training, teacher forcing is commonly used. Instead of feeding the decoder’s own previous prediction as the next input, the actual target token from the training data is provided.
Benefits:
Accelerates training
Reduces error propagation
Teacher forcing is used only during training and not during inference, where the model relies on its own previous predictions.

{kind=link}
{kind=link}
{kind=link}