 |
VOOZH | about |
|
VOOZH | about |
Python provides many NLP libraries that help process, analyze and understand text data efficiently. These libraries support tasks such as tokenization, sentiment analysis, named entity recognition and topic modelling.
Regex is used for pattern matching and text processing in NLP. It helps clean text, extract useful information and perform text transformations efficiently.
Output:
NLTK is a Python library used for text analysis and NLP tasks such as tokenization, stemming, lemmatization and part-of-speech tagging.
spaCy is a high-performance NLP library used for fast text processing tasks such as named entity recognition and dependency parsing.
This code loads SpaCy’s English model, processes the text and identifies named entities such as organizations and locations.
Output:
Apple ORG
California GPE
TextBlob is a simple NLP library used for tasks such as sentiment analysis and language translation. It is beginner-friendly and useful for quick NLP applications.
This code analyzes the sentiment of the text and returns polarity and subjectivity scores.
Output:
Sentiment(polarity=0.5, subjectivity=0.6)
Textacy is an NLP library built on top of spaCy that provides tools for preprocessing, feature extraction and topic modeling.
This code removes punctuation from the text using Textacy preprocessing functions.
Output:
Hello Welcome to NLP with Textacy
VADER is a rule-based sentiment analysis tool designed for analyzing social media and informal text. It can understand sentiment in text containing emojis, slang and informal expressions.
This code analyzes the sentiment of the text and returns sentiment scores for positive, negative, neutral and compound sentiment.
Output:
{'neg': 0.0, 'neu': 0.458, 'pos': 0.542, 'compound': 0.7959}
Gensim is an NLP library used for topic modeling, document similarity analysis and word embeddings. It is designed to efficiently process large text datasets.
This code preprocesses the text and converts it into lowercase tokens using Gensim.
Output:
['gensim', 'is', 'useful', 'for', 'topic', 'modeling', 'and', 'nlp']
KerasNLP is a deep learning NLP library built on TensorFlow and Keras that provides pre-trained models and tools for tasks such as text classification, generation, and translation.
This code loads a pre-trained BERT model and performs text classification on the input text.
Output:
Stanza is an NLP library developed by Stanford that provides pre-trained models for tasks such as tokenization, named entity recognition and dependency parsing. It is built on PyTorch for efficient and scalable NLP processing.
This code loads Stanza’s English model, processes the text and displays each word with its part-of-speech tag.
Output:
PyTorch-NLP is an NLP library built on PyTorch that provides utilities and preprocessing tools for deep learning-based NLP applications.
This code tokenizes and converts the text into numerical token IDs using PyTorch-NLP.
Output:
tensor([5, 6, 7, 8])
PyNLPl is an NLP library used for tasks such as corpus processing, syntactic parsing, and linguistic analysis. It is useful for multilingual NLP and research based text processing.
This code tokenizes the sentence into individual words using PyNLPl.
Output:
['Natural', 'Language', 'Processing', 'is', 'interesting', '.']
Hugging Face Transformers is an NLP library that provides transformer-based models such as BERT and GPT for advanced NLP tasks like text classification, generation and question answering.
This code uses a pre-trained transformer model to generate text based on the given input prompt.
Output:
Flair is a deep learning NLP library used for tasks such as named entity recognition and text classification. It provides high accuracy using modern language embedding techniques.
This code loads Flair’s NER model and identifies named entities in the sentence.
Output:
FastText is an NLP library developed by Facebook AI for fast text classification and word embedding generation. It is designed to efficiently handle large text datasets.
This code trains a simple FastText model and displays the word embedding vector for the word “NLP”.
Output:
Polyglot is a multilingual NLP library that supports more than 130 languages for tasks such as language detection, tokenization, and sentiment analysis.
This code detects the language of the given text using Polyglot.
Output:
Download full code form here
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
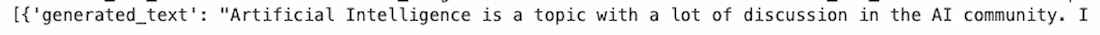{kind=link}
{kind=link}
{kind=link}
{kind=link}