 |
VOOZH | about |
|
VOOZH | about |
Word Embeddings are numeric representations of words in a lower-dimensional space, that capture semantic and syntactic information. They play a important role in Natural Language Processing (NLP) tasks. Here, we'll discuss some traditional and neural approaches used to implement Word Embeddings, such as TF-IDF, Word2Vec, and GloVe.
Above images represent the Process and an Example of Word Embeddings in Natural Language Processing.
Word Embedding is an approach for representing words and documents. Word Embedding or Word Vector is a numeric vector input that represents a word in a lower-dimensional space.
Words ----> Numeric representation ----> Use in Training or Inference.
Let's take an example to understand how word vector is generated by taking emotions which are most frequently used in certain conditions and transform each emoji into a vector and the conditions will be our features.
In a similar way, we can create word vectors for different words as well on the basis of given features. The words with similar vectors are most likely to have the same meaning or are used to convey the same sentiment.
The conventional method involves compiling a list of distinct terms and giving each one a unique integer value or id, and after that, insert each word's distinct id into the sentence. Every vocabulary word is handled as a feature in this instance. Thus, a large vocabulary will result in an extremely large feature size. Common traditional methods include:
1.1 One-Hot Encoding
One-hot encoding is a simple method for representing words in natural language processing (NLP). In this encoding scheme, each word in the vocabulary is represented as a unique vector, where the dimensionality of the vector is equal to the size of the vocabulary. The vector has all elements set to 0, except for the element corresponding to the index of the word in the vocabulary, which is set to 1.
Following are the disadvantages:
Output:
Vocabulary: {'mat', 'the', 'bird', 'hat', 'on', 'in', 'cat', 'tree', 'dog'}
Word to Index Mapping: {'mat': 0, 'the': 1, 'bird': 2, 'hat': 3, 'on': 4, 'in': 5, 'cat': 6, 'tree': 7, 'dog': 8}
One-Hot Encoded Matrix:
cat: [0, 0, 0, 0, 0, 0, 1, 0, 0]
in: [0, 0, 0, 0, 0, 1, 0, 0, 0]
the: [0, 1, 0, 0, 0, 0, 0, 0, 0]
hat: [0, 0, 0, 1, 0, 0, 0, 0, 0]
dog: [0, 0, 0, 0, 0, 0, 0, 0, 1]
on: [0, 0, 0, 0, 1, 0, 0, 0, 0]
the: [0, 1, 0, 0, 0, 0, 0, 0, 0]
mat: [1, 0, 0, 0, 0, 0, 0, 0, 0]
bird: [0, 0, 1, 0, 0, 0, 0, 0, 0]
in: [0, 0, 0, 0, 0, 1, 0, 0, 0]
the: [0, 1, 0, 0, 0, 0, 0, 0, 0]
tree: [0, 0, 0, 0, 0, 0, 0, 1, 0]
1.2 Bag of Word (Bow)
Bag-of-Words (BoW) is a text representation technique that represents a document as an unordered set of words and their respective frequencies. It discards the word order and captures the frequency of each word in the document, creating a vector representation. Limitations are as follows:
Output:
Bag-of-Words Matrix:
[[0 1 1 1 0 0 1 0 1]
[0 2 0 1 0 1 1 0 1]
[1 0 0 1 1 0 1 1 1]
[0 1 1 1 0 0 1 0 1]]
Vocabulary (Feature Names): ['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
1.3 Term frequency-inverse document frequency (TF-IDF)
Term Frequency-Inverse Document Frequency, commonly known as TF-IDF, is a numerical statistic that reflects the importance of a word in a document relative to a collection of documents (corpus). It is widely used in natural language processing and information retrieval to evaluate the significance of a term within a specific document in a larger corpus. TF-IDF consists of two components:
The TF-IDF score for a term t in a document d is then given by multiplying the TF and IDF values:
Where:
Term Frequency (TF):
Inverse Document Frequency (IDF):
The higher the TF-IDF score for a term in a document, the more important that term is to that document within the context of the entire corpus. This weighting scheme helps in identifying and extracting relevant information from a large collection of documents, and it is commonly used in text mining, information retrieval, and document clustering.
Steps are as follows:
Output:
Document 1:
dog: 0.3404110310756642
lazy: 0.3404110310756642
over: 0.3404110310756642
jumps: 0.3404110310756642
fox: 0.3404110310756642
brown: 0.3404110310756642
quick: 0.3404110310756642
the: 0.43455990318254417
Document 2:
step: 0.3535533905932738
single: 0.3535533905932738
with: 0.3535533905932738
begins: 0.3535533905932738
miles: 0.3535533905932738
thousand: 0.3535533905932738
of: 0.3535533905932738
journey: 0.3535533905932738
Some of the disadvantages of TF-IDF are:
2.1 Word2Vec
Word2Vec is a neural approach for generating word embeddings. It belongs to the family of neural word embedding techniques and specifically falls under the category of distributed representation models. It is a popular technique in natural language processing (NLP).
There are two neural embedding methods for Word2Vec: Continuous Bag of Words (CBOW) and Skip-gram.
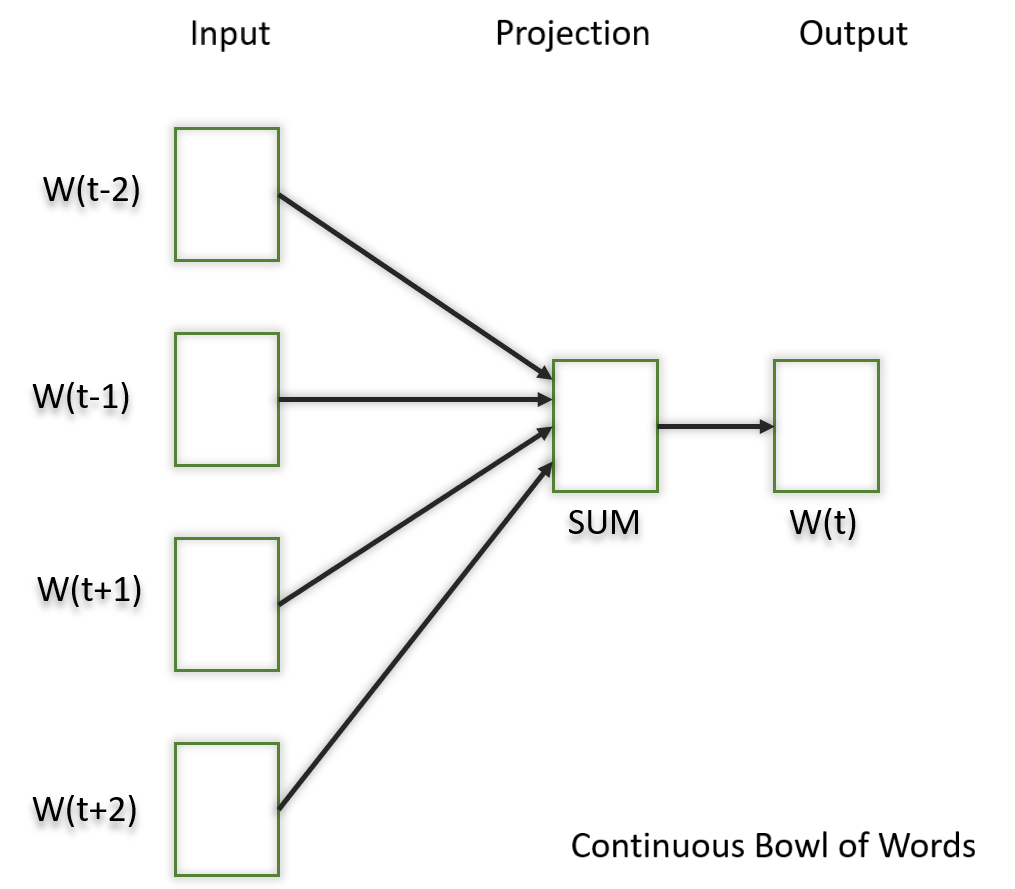
2.2 Continuous Bag of Words(CBOW)
Continuous Bag of Words (CBOW) is a type of neural network architecture used in the Word2Vec model. The primary objective of CBOW is to predict a target word based on its context, which consists of the surrounding words in a given window. Given a sequence of words in a context window, the model is trained to predict the target word at the center of the window.
The hidden layer contains the continuous vector representations (word embeddings) of the input words.
Output:
Embedding for 'embeddings': [[-2.7053456 2.1384873 0.6417674 1.2882394 0.53470695 0.5651745
0.64166373 -1.1691749 0.32658175 -0.99961764]]
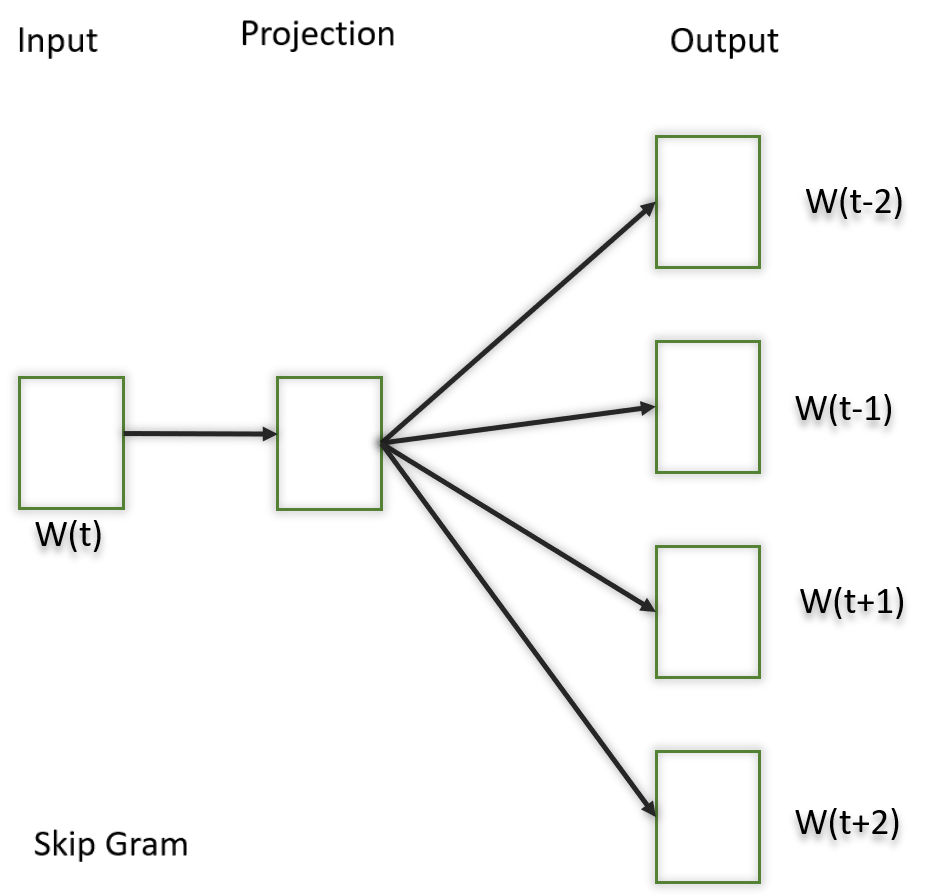
2.3 Skip-Gram
The Skip-Gram model learns distributed representations of words in a continuous vector space. The main objective of Skip-Gram is to predict context words (words surrounding a target word) given a target word. This is the opposite of the Continuous Bag of Words (CBOW) model, where the objective is to predict the target word based on its context. It is shown that this method produces more meaningful embeddings.
Note: Word2Vec models can perform better with larger datasets. If you have a large corpus, you might achieve more meaningful word embeddings.
Output:
Vector representation of 'word': [-9.5800208e-03 8.9437785e-03 4.1664648e-03 9.2367809e-03
6.6457358e-03 2.9233587e-03 9.8055992e-03 -4.4231843e-03
-6.8048164e-03 4.2256550e-03 3.7299085e-03 -5.6668529e-03
--------------------------------------------------------------
2.8835384e-03 -1.5386029e-03 9.9318363e-03 8.3507905e-03
2.4184163e-03 7.1170190e-03 5.8888551e-03 -5.5787875e-03]
The choice between CBOW and Skip-gram depends on data and the task.
Pre-trained word embeddings are representations of words that are learned from large corpora and are made available for reuse in various Natural Language Processing (NLP) tasks. These embeddings capture semantic relationships between words, allowing the model to understand similarities and relationships between different words in a meaningful way.
3.1 GloVe
GloVe is trained on global word co-occurrence statistics. It leverages the global context to create word embeddings that reflect the overall meaning of words based on their co-occurrence probabilities. this method, we take the corpus and iterate through it and get the co-occurrence of each word with other words in the corpus. We get a co-occurrence matrix through this. The words which occur next to each other get a value of 1, if they are one word apart then 1/2, if two words apart then 1/3 and so on.
Let's see how the matrix is created. Corpus:
It is a nice evening.
Good Evening!
Is it a nice evening?
| it | is | a | nice | evening | good | |
|---|---|---|---|---|---|---|
| it | 0 | |||||
| is | 1+1 | 0 | ||||
| a | 1/2+1 | 1+1/2 | 0 | |||
| nice | 1/3+1/2 | 1/2+1/3 | 1+1 | 0 | ||
| evening | 1/4+1/3 | 1/3+1/4 | 1/2+1/2 | 1+1 | 0 | |
| good | 0 | 0 | 0 | 0 | 1 | 0 |
The upper half of the matrix will be a reflection of the lower half. We can consider a window frame as well to calculate the co-occurrences by shifting the frame till the end of the corpus. This helps gather information about the context in which the word is used.
You can refer to the library used in this approach: Gensim
Output:
Similarity between 'learn' and 'learning' using GloVe: 0.802
Similarity between 'india' and 'indian' using GloVe: 0.865
Similarity between 'fame' and 'famous' using GloVe: 0.589
3.2 Fasttext
Developed by Facebook, FastText extends Word2Vec by representing words as bags of character n-grams. This approach is particularly useful for handling out-of-vocabulary words and capturing morphological variations.
Output:
Similarity between 'learn' and 'learning' using Word2Vec: 0.642
Similarity between 'india' and 'indian' using Word2Vec: 0.708
Similarity between 'fame' and 'famous' using Word2Vec: 0.519
3.3 BERT (Bidirectional Encoder Representations from Transformers)
BERT is a transformer-based model that learns contextualized embeddings for words. It considers the entire context of a word by considering both left and right contexts, resulting in embeddings that capture rich contextual information.
Output:
Similarity between 'learn' and 'learning' using BERT: 0.930
Similarity between 'india' and 'indian' using BERT: 0.957
Similarity between 'fame' and 'famous' using BERT: 0.956
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}