 |
VOOZH | about |
|
VOOZH | about |
GloVe (Global Vectors for Word Representation) is an unsupervised learning algorithm that generates dense word embeddings by analyzing co-occurrence patterns in a large text corpus, capturing semantic relationships between words.
GloVe provides pre-trained dense vectors learned from large corpora (e.g., 6 billion tokens), with embeddings available for a large vocabulary of unique words. These embeddings represent words as numerical vectors that capture semantic relationships.
The GloVe algorithm works using the following process
First, we split the text into individual words (tokenization) so that we can work with them.
Example:
Input text: "The peon is ringing the bell"
Tokenized words: ['The', 'peon', 'is', 'ringing', 'the', 'bell']
After tokenization, we create a list of all unique words in the text and then count how often each word appears.
Example:
Vocabulary with word frequencies:
{'The': 2, 'peon': 1, 'is': 1, 'ringing': 1, 'the': 1, 'bell': 1}
After this, the words are typically sorted by frequency.
Now, we build a co-occurrence matrix where we count how often each word appears near other words in a given context (usually within a window of fixed size around the word).
Example: Let's say we choose a window size of 2 (2 words before and after each word). The co-occurrence matrix might look something like this
| The | peon | is | ringing | the | bell | |
|---|---|---|---|---|---|---|
| The | 0 | 1 | 1 | 1 | 1 | 0 |
| peon | 1 | 0 | 1 | 1 | 0 | 0 |
| is | 1 | 1 | 0 | 1 | 1 | 0 |
| ringing | 1 | 1 | 1 | 0 | 1 | 1 |
| the | 1 | 0 | 1 | 1 | 0 | 1 |
| bell | 0 | 0 | 0 | 1 | 1 | 0 |
In this matrix, the value at (i, j) represents how often word i and word j appear together in the context window.
The aim is to learn word vectors such that the dot product of two word vectors reflects how often the words co-occur in the context. This ensures that words that appear in similar contexts will have similar vector representations.
Example:
"The" and "is" are frequently seen together, so their vectors will be close in the embedding space.
"peon" and "bell" don't co-occur much, so their vectors will be far apart.
The model learns word embeddings by adjusting vectors based on how often words appear together. It aims to capture meaningful relationships between words using co-occurrence information.
Example:
"The" and "is" will have vector adjustments that make their dot product similar to their co-occurrence probability, ensuring their vectors are close to each other.
"peon" and "bell" will be adjusted to have distant vectors since their co-occurrence is low.
After training, the model outputs an embedding matrix where each word is represented by a dense vector. These vectors are able to capture the semantic and syntactic relationships between words.
Example: The resulting word vectors in the embedding matrix might look like this:
| Word | Vector |
|---|---|
| The | [0.3, 0.1, 0.5] |
| peon | [0.2, 0.4, 0.3] |
| is | [0.6, 0.3, 0.4] |
| ringing | [0.1, 0.8, 0.7] |
| the | [0.3, 0.1, 0.5] |
| bell | [0.2, 0.3, 0.1] |
Here we will see step by step implementation
We will be importing necessary libraries to handle text processing and numerical operations.
We will be defining a list of words (texts) that we want to use for building a vocabulary. These words represent our small sample text corpus that the tokenizer will later process.
We will be initializing the Tokenizer object and fitting it on the texts corpus to create a dictionary of words and their corresponding integer indices. The tokenizer will break the words into unique tokens and assign each token an integer ID.
Output:
Number of unique words in dictionary = 6
Dictionary is = {'text': 1, 'the': 2, 'leader': 3, 'prime': 4, 'natural': 5, 'language': 6}
We will be defining the function embedding_for_vocab that loads pre-trained GloVe word vectors and creates an embedding matrix for the vocabulary.
Inside the function:
We will be downloading the GloVe dataset from Stanford's NLP repository. This dataset contains pre-trained word embeddings, and we will be specifically using the 50-dimensional embeddings (glove.6B.50d.txt).
Output:
We will be specifying the embedding dimension (50 in this case, matching the GloVe file) and providing the path to the GloVe file. We then call the previously defined function embedding_for_vocab to load the GloVe embeddings and generate the embedding matrix for our vocabulary.
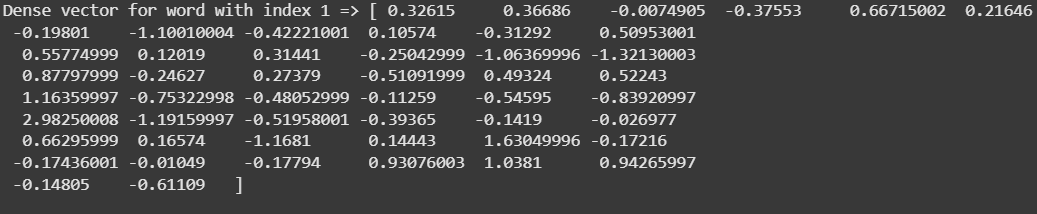
We will be accessing the embedding vector for a specific word in the tokenizer’s index. In this case, we're accessing the vector for the word with index 1, which corresponds to the word "text" in the vocabulary.
GloVe embeddings are widely used in various NLP tasks due to their ability to capture word semantics. Key applications include
{kind=link}
{kind=link}
{kind=link}