 |
VOOZH | about |
|
VOOZH | about |
TF-IDF (Term Frequency–Inverse Document Frequency) is a statistical method used in natural language processing and information retrieval to evaluate how important a word is to a document in relation to a larger collection of documents. TF-IDF combines two components:
1. Term Frequency (TF): Measures how often a word appears in a document. A higher frequency suggests greater importance. If a term appears frequently in a document, it is likely relevant to the document’s content.
2. Inverse Document Frequency (IDF): Reduces the weight of common words across multiple documents while increasing the weight of rare words. If a term appears in fewer documents, it is more likely to be meaningful and specific.
This balance allows TF-IDF to highlight terms that are both frequent within a specific document and distinctive across the text document, making it a useful tool for tasks like search ranking, text classification and keyword extraction.
Let's take an example where we have a corpus (a collection of documents) with three documents and our goal is to calculate the TF-IDF score for specific terms in these documents.
Our goal is to calculate the TF-IDF score for specific terms in these documents. Let’s focus on the word "cat" and see how TF-IDF evaluates its importance.
For Document 1:
For Document 2:
For Document 3:
In Document 1 and Document 3 the word "cat" has the same TF score. This means it appears with the same relative frequency in both documents. In Document 2 the TF score is 0 because the word "cat" does not appear.
The TF-IDF score for "cat" is 0.029 in Document 1 and Document 3 and 0 in Document 2 that reflects both the frequency of the term in the document (TF) and its rarity across the corpus (IDF).
The TF-IDF score is the product of TF and IDF:
We will import scikit learn for this.
Here we are using TfidfVectorizer() from scikit learn to perform tf-idf and apply on our courpus using fit_transform.
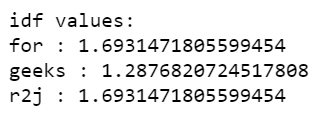
Output:
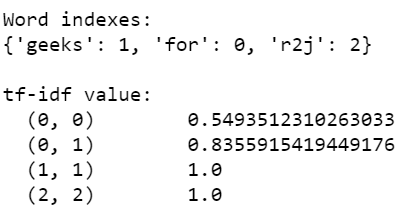
Output:
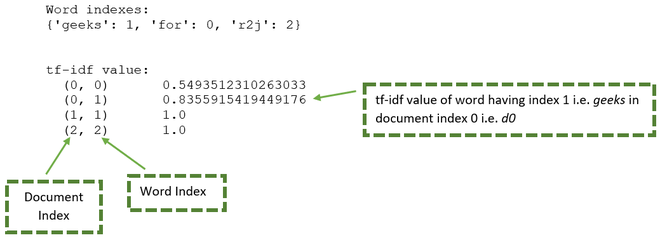
The result variable consists of unique words as well as the tf-if values. It can be elaborated using the below image:
From the above image the below table can be generated:
| Document | Word | Document Index | Word Index | tf-idf value |
|---|---|---|---|---|
| d0 | for | 0 | 0 | 0.549 |
| d0 | geeks | 0 | 1 | 0.8355 |
| d1 | geeks | 1 | 1 | 1.000 |
| d2 | r2j | 2 | 2 | 1.000 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}