 |
VOOZH | about |
|
VOOZH | about |
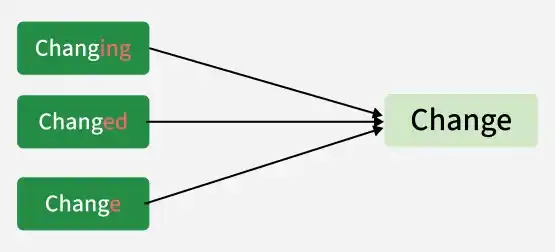
Lemmatization is a text preprocessing technique in Natural Language Processing (NLP) that converts words into their base or dictionary form called a lemma. Unlike stemming, it considers the meaning and part of speech of words, making the output more accurate and meaningful.
There are different techniques to perform lemmatization each with its own advantages and use cases
In rule-based lemmatization, predefined rules are applied to a word to remove suffixes and get the root form. This approach works well for regular words but may not handle irregularities well.
For example:
Rule: For regular verbs ending in "-ed," remove the "-ed" suffix.
Example: "walked" -> "walk"
While this method is simple and interpretable, it doesn't account for irregular word forms like "better" which should be lemmatized to "good".
It uses a predefined dictionary or lexicon such as WordNet to look up the base form of a word. This method is more accurate than rule-based lemmatization because it accounts for exceptions and irregular words.
For example:
- 'running' -> 'run'
- 'better' -> 'good'
- 'went' -> 'go
"I was running to become a better athlete and then I went home," -> "I was run to become a good athlete and then I go home."
By using dictionaries like WordNet this method can handle a range of words effectively, especially in languages with well-established dictionaries.
It uses algorithms trained on large datasets to automatically identify the base form of words. This approach is highly flexible and can handle irregular words and linguistic nuances better than the rule-based and dictionary-based methods.
For example:
A trained model may deduce that “went” corresponds to “go” even though the suffix removal rule doesn’t apply. Similarly, for 'happier' the model deduces 'happy' as the lemma.
Machine learning-based lemmatizers are more adaptive and can generalize across different word forms which makes them ideal for complex tasks involving diverse vocabularies.
Lets see step by step how Lemmatization works in Python:
In Python, the NLTK library provides an easy and efficient way to implement lemmatization. First, we need to install the NLTK library and download the necessary datasets like WordNet and the punkt tokenizer.
Now lets import the library and download the necessary datasets.
Now we can tokenize the text and apply lemmatization using NLTK's WordNetLemmatizer.
Output:
In this output, we can see that:
To improve the accuracy of lemmatization, it’s important to specify the correct Part of Speech (POS) for each word. By default, NLTK assumes that words are nouns when no POS tag is provided. However, it can be more accurate if we specify the correct POS tag for each word.
For example:
Output:
In this improved version:
Download code from here
{kind=link}
{kind=link}
{kind=link}
{kind=link}