FastText is a word embedding technique developed by Facebook that represents words using character level subwords. It handles unseen words effectively and captures both semantic and morphological information.
Uses character level subwords.
Handles out of vocabulary words.
Captures word meaning and structure.
Efficient for large text datasets.
FastText Architecture and Working
FastText extends traditional word embedding models by representing words as collections of character n-grams rather than treating them as single units. This approach helps capture word structure and generate embeddings for unseen words.
Character N-Gram Representation
FastText breaks each word into smaller groups of characters called n-grams. Instead of learning only the whole word, it also learns these smaller character patterns, helping it understand word structure and meaning. Consider the word "running":
3-grams: <ru, run, unn, nni, nin, ing, ng>
4-grams: <run, runn, unni, nnin, ning, ing>
5-grams: <runn, runni, unnin, nning, ning>
Here:
A 3-gram contains 3 consecutive characters.
A 4-gram contains 4 consecutive characters.
These subwords help FastText understand related words such as run, runner and running.
Hierarchical Softmax Optimization
Hierarchical Softmax is an optimization technique used by FastText to speed up training. Instead of comparing a word with every word in the vocabulary, it organizes words in a tree structure and performs fewer calculations.

{kind=link}
{kind=link}
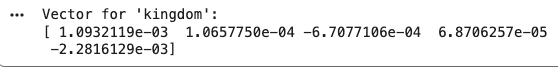{kind=link}
{kind=link}