 |
VOOZH | about |
|
VOOZH | about |
In order to make the computer understand a written text, we can represent the words as numerical vectors. One way to do so is by Using Word embeddings, they are a way of representing words as numerical vectors. These vectors capture the meaning of the words and their relationships to other words in the language. Word embeddings can be generated using unsupervised learning algorithms such as Word2vec, GloVe, or FastText.
Word2vec is a neural network-based method for generating word embeddings, which are dense vector representations of words that capture their semantic meaning and relationships. There are two main approaches to implementing Word2vec:
Continuous Bag of Words (CBOW) is a popular natural language processing technique used to generate word embeddings. Word embeddings are important for many NLP tasks because they capture semantic and syntactic relationships between words in a language. CBOW is a neural network-based algorithm that predicts a target word given its surrounding context words. It is a type of "unsupervised" learning, meaning that it can learn from unlabeled data, and it is often used to pre-train word embeddings that can be used for various NLP tasks such as sentiment analysis, text classification, and machine translation.
The CBOW model uses the context words around the target word in order to predict it. Consider the above example "She is a great dancer." The CBOW model converts this phrase into pairs of context words and target words. The word pairings would appear like this ([she, a], is), ([is, great], a) ([a, dancer], great) having window size=2.
The model considers the context words and tries to predict the target term. The four 1∗W input vectors will be passed to the input layer if have four words as context words are used to predict one target word. The hidden layer will receive the input vectors and then multiply them by a W∗N matrix. The 1∗N output from the hidden layer finally enters the sum layer, where the vectors are element-wise summed before a final activation is carried out and the output is obtained from the output layer.
Let's implement a word embedding to show the similarity of words using the CBOW model. In this article I have defined my own corpus of words, you use any dataset. First, we will import all the necessary libraries and load the dataset. Next, we will tokenize each word and convert it into a vector of integers.
Output:
After converting our words in the corpus into vector of integers:
[[1, 3, 4, 5, 1, 6], [1, 7, 8, 2, 1, 9], [1, 10, 11, 2, 1, 12]]
Now, we will build the CBOW model having window size = 2.
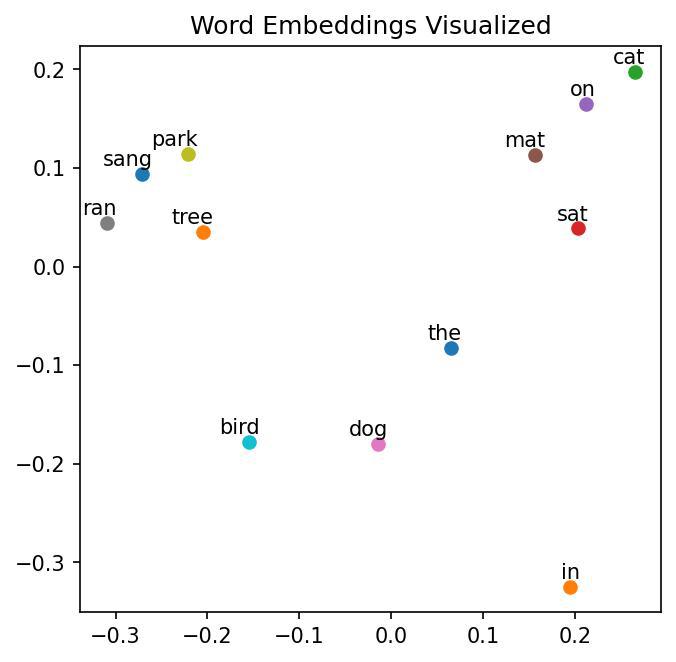
Next, we will use the model to visualize the embeddings.
Output:
This visualization allows us to observe the similarity of the words based on their embeddings. Words that are similar in meaning or context are expected to be close to each other in the plot.
{kind=link}
.png){kind=link}
-660.png){kind=link}
{kind=link}