Feature extraction transforms raw data into meaningful and structured features that machine learning models can easily interpret. It organizes complex data into clear and useful variables so that patterns and relationships in the data can be understood more easily. This step prepares the data in a form that supports effective analysis and prediction.
Converts raw and unstructured data into useful features
Represents the important characteristics of the dataset through clear variables
Helps machine learning models learn patterns and relationships in data by providing meaningful inputs
Importance of Feature Extraction
Reduces computation by simplifying complex raw data.
Improves model performance using relevant features.
Provides better insights by removing noise.
Helps prevent overfitting by reducing feature complexity.
Key Techniques for Feature Extraction
1. Statistical Methods
Statistical methods are used in feature extraction to summarize and explain patterns of data. Common data attributes include:
These statistical methods can be used to represent the center trend, spread and links within a collection.
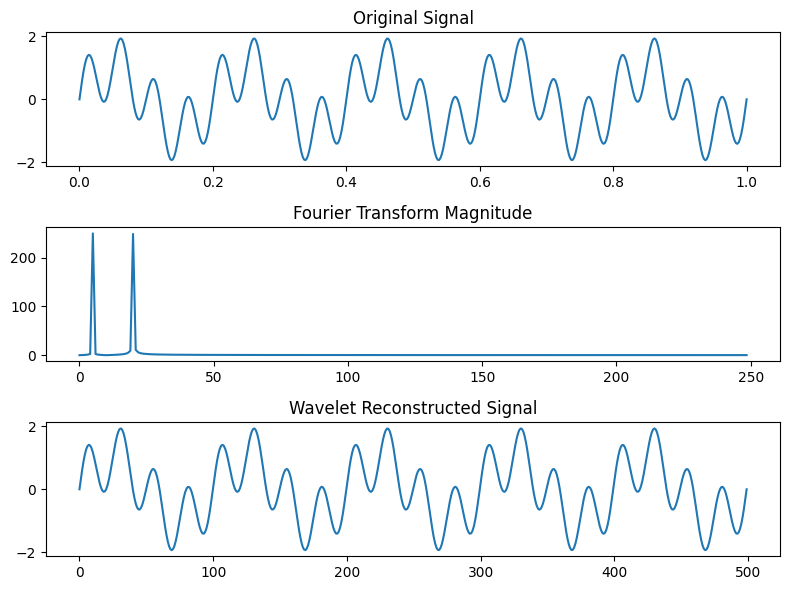
2. Dimensionality Reduction
Dimensionality reduction reduces the number of features without losing important information. Some popular methods are:
Principal Component Analysis: It transforms original features into new orthogonal components that capture maximum variance in the data.
Linear Discriminant Analysis (LDA): It finds the best combination of features to separate different classes, maximizing class separability for better classification.
Histogram of Oriented Gradients (HOG): This technique finds the distribution of intensity gradients or edge directions in an image. It's used in object detection and recognition tasks.
Selecting the appropriate feature extraction method depends on the type of data and the specific problem we're solving. It requires careful consideration and often domain expertise.
Information Loss: Feature extraction might simplify the data too much, potentially losing important information in the process.
Computational Complexity: Some methods, especially for large datasets can be computationally expensive and may require significant resources.
Feature Selection vs. Feature Extraction
Since Feature Selection and Feature Extraction are related but not the same, let’s quickly see the key differences between them for a better understanding:
Aspect
Feature Selection
Feature Extraction
Definition
Selecting a subset of relevant features from the original set
Transforming the original features into a new set of features
Purpose
Reduce dimensionality
Transform data into a more manageable or informative representation
Process
Filtering, wrapper methods, embedded methods
Signal processing, statistical techniques, transformation algorithms
Output
Subset of selected features
New set of transformed features
Computational Cost
Lower cost
May be higher, especially for complex transformations
Interpretability
Retains interpretability of original features
May lose interpretability depending on transformation
Tools and Libraries for Feature Extraction
There are several tools and libraries available for feature extraction across different domains. Let's see some popular ones:
Scikit-learn: It offers tools for various machine learning tasks including PCA, ICA and preprocessing methods for feature extraction.
OpenCV: A popular computer vision library with functions for image feature extraction such as SIFT, SURF and ORB.
TensorFlow / Keras: These deep learning libraries in Python provide APIs for building and training neural networks which can be used for feature extraction from image, text and other types of data.
PyTorch: A deep learning library enabling custom neural network designs for feature extraction and other tasks.
NLTK (Natural Language Toolkit): A popular NLP library providing feature extraction methods like bag-of-words, TF-IDF and word embeddings for text data.
Applications
Computer Vision and Image Processing: Used in autonomous vehicles to detect road signs and pedestrians by extracting key visual features for safe navigation.
Natural Language Processing (NLP): Powers email spam filtering by extracting textual features to accurately classify messages as spam or legitimate.
Biomedical Engineering: Extracting features from EEG or MRI signals helps diagnose neurological disorders or detect early signs of disease.
Industrial and Equipment Monitoring: Predictive maintenance uses sensor data features to foresee machine failures, reducing downtime and repair costs.
Financial and Fraud Detection: Analyzes transaction patterns to identify fraudulent activities and prevent financial losses.
Advantages
Simplifies Data: Reduces complex data into a manageable form for easier analysis and visualization.
Boosts Model Performance: Removes irrelevant data, making algorithms faster and more accurate.
Highlights Key Patterns: Filters out noise to focus on important features for quicker insights.
Improves Generalization: Helps models perform better on new, unseen data by emphasizing informative features.
Speeds Up Training and Prediction: Fewer features mean faster model training and real-time predictions.
Challenges
Managing High-Dimensional Data: Extracting relevant features from large, complex datasets can be difficult.
Risk of Overfitting or Underfitting: Too many or too few features can hurt model accuracy and generalization.
Computational Costs: Complex methods may require heavy resources, limiting use with big or real-time data.
Redundant or Irrelevant Features: Overlapping or noisy features can confuse models and reduce efficiency.

{kind=link}
{kind=link}
{kind=link}
{kind=link}