 |
VOOZH | about |
|
VOOZH | about |
Convolutional Neural Networks (CNNs), are neural network architectures inspired by the human visual system, designed to process image data by capturing spatial relationships between pixels.
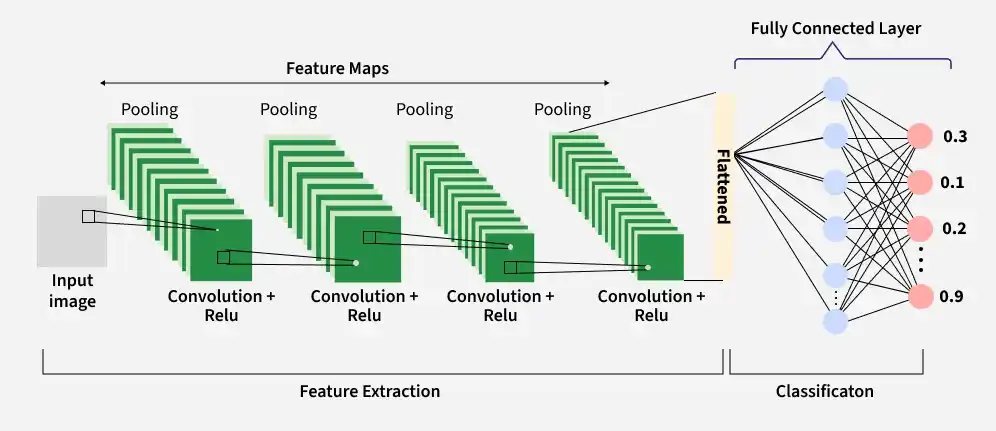
A complete Convolution Neural Networks architecture is also known as covnets. A covnets is a sequence of layers and every layer transforms one volume to another through a differentiable function. Let’s take an example by running a covnets on of image of dimension 32 x 32 x 3.
The input layer receives the raw image data and passes it to the network for processing. In CNNs, input is typically a 3D volume (width × height × depth).
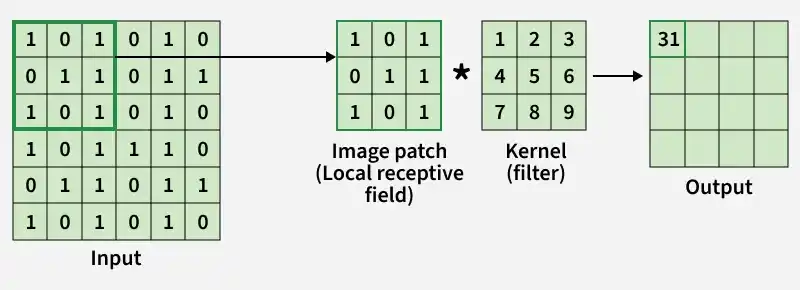
The Convolutional Layer is responsible for extracting important features from the input data. It applies a set of learnable filters (kernels) that slide over the image and compute the dot product between the filter weights and corresponding image patches, producing feature maps.
Example: Using 12 filters results in an output volume of 32 × 32 × 12.
The Activation Layer introduces non-linearity into the network by applying an element-wise activation function to the output of the convolution layer. This enables the model to learn complex patterns beyond linear relationships.
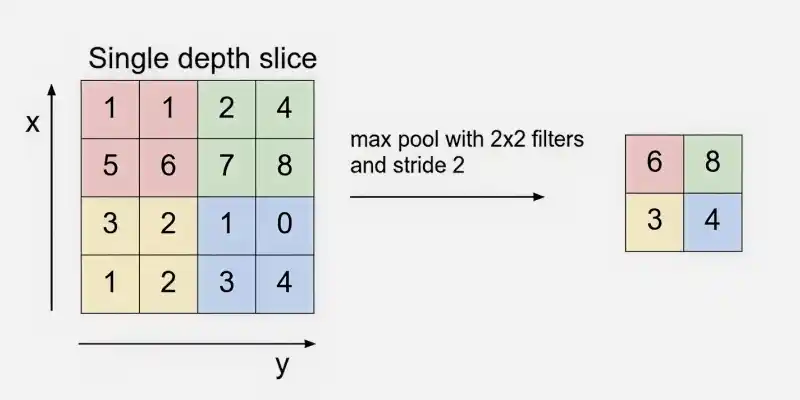
The Pooling Layer is used to reduce the spatial dimensions of the feature maps, making computation faster, reducing memory usage and helping to prevent overfitting. It is typically inserted between convolutional layers in a CNN.
Example: Using 2 × 2 max pooling with stride 2 reduces the volume from 32 × 32 × 12 to 16 × 16 × 12.
Flattening converts the multi-dimensional feature maps into a one-dimensional vector after convolution and pooling. This vector is then passed to the fully connected layer for classification or regression.
Example: Flattening 16 × 16 × 12 results in a vector of size 3072 (16 × 16 × 12).
The fully connected (dense) layer performs high-level reasoning using extracted features and produces the final classification scores.
Example: The 3072-length vector is connected to neurons for classification
The output layer converts final scores into probabilities using activation functions like Sigmoid (binary classification) or Softmax (multi-class classification).
Example: For 10 classes, Softmax produces 10 probability values each representing the likelihood of a class.
Here we implement a Convolutional Neural Network illustrating how each layer processes and transforms the input image.
Here we import TensorFlow for CNN operations and Matplotlib for visualization.
Load the image convert it to grayscale, resize it to 300×300 and normalize pixel values.
Output:
We define an edge detection filter (Laplacian kernel) to extract important image features.
The convolution layer applies the filter to the image to detect edges and features.
Output:
ReLU removes negative values and introduces non-linearity into the network.
Output:
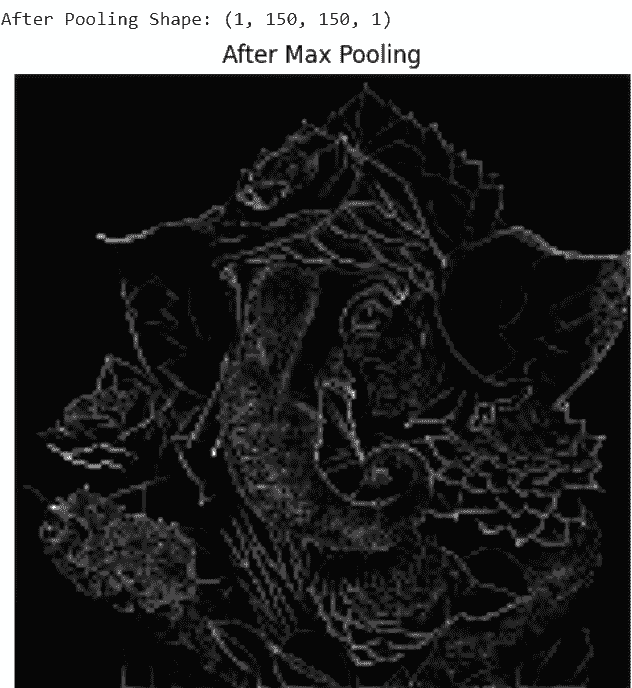
Max pooling reduces spatial dimensions while keeping important features.
Output:
The flatten layer converts 2D feature maps into a 1D feature vector for fully connected layers.
Output:
After Flatten Shape: (1, 22500)
First 20 values of Flattened Vector:
[135. 81. 81. 81. 81. 81. 81. 81. 81. 81. 81. 81. 81. 81.
81. 81. 81. 81. 81. 81.]
The fully connected layer learns high-level patterns from the flattened feature vector and produces output predictions.
Output:
After Fully Connected Layer Shape: (1, 64)
You can download full code from here
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}