 |
VOOZH | about |
|
VOOZH | about |
Neural Machine Translation (NMT) is a standard task in NLP that involves translating a text from a source language to a target language. BLEU (Bilingual Evaluation Understudy) is a score used to evaluate the translations performed by a machine translator. In this article, we'll see the mathematics behind the BLEU score and its implementation in Python.
Table of Content
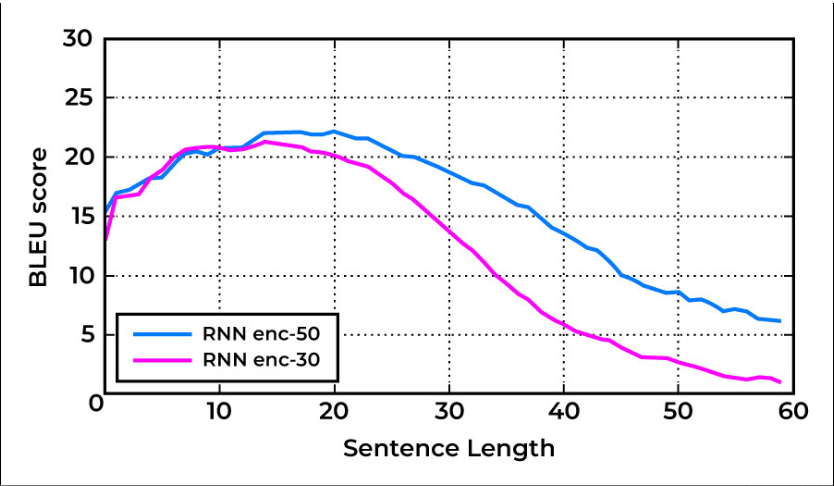
As stated above BLEU Score is an evaluation metric for Machine Translation tasks. It is calculated by comparing the n-grams of machine-translated sentences to the n-gram of human-translated sentences. Usually, it has been observed that the BLEU score decreases as the sentence length increases. This, however, might vary depending upon the model used for translation. The following is a graph depicting the variation of the BLEU Score with the sentence length.
👁 ImageMathematically, BLEU Score is given as follows:
Here,
- BP stands for Brevity Penalty
- is the weight for n-gram precision of order i (typically weights are equal for all i)
- is the n-gram modified precision score of order i.
- N is the maximum n-gram order to consider (usually up to 4)
The modified precision is indeed calculated as the ratio between the number of n-grams in the candidate translation that match exactly n-grams in any of the reference translations, clipped by the number of n-grams in the candidate translation.
Here,
- Count Clips is a function that clips the number of matched n-grams ( )by the maximum count of the n-gram across all reference translations (.
- is the number of n-grams of order i that match exactly between the candidate translation and any of the reference translations.
- is the maximum number of occurrences of the specific n-gram of order i found in any single reference translation.
- is the total number of n-grams of order i present in the candidate translation.
Brevity Penalty penalizes translations that are shorter than the reference translations. The mathematical expression for Brevity Penalty is given as follows:
Here,
- r is the length of the candidate translation
- c is the average length of the reference translations.
For a better understanding of the calculation of the BLEU Score, let us take an example. Following is a case for French to English Translation:
We can clearly see that the translation done by the machine is not accurate. Let's calculate the BLEU score for the translation.
For n = 1, we'll calculate the Unigram Modified Precision:
| Unigram | Count in Machine Translation | Max count in Ref | Clipped Count = min (Count in MT, Max Count in Ref) |
|---|---|---|---|
| the | 2 |
1 | 1 |
| picture | 2 |
1 | 1 |
| by | 1 |
1 | 1 |
| me | 1 |
1 | 1 |
Here the unigrams (the, picture, by, me) are taken from the machine-translated text. Count refers to the frequency of n-grams in all the Machine Translated Text, and Clipped Count refers to the frequency of unigram in the reference texts collectively.
For n = 2, we'll calculate the Bigram Modified Precision:
| Bigrams | Count in MT | Max Count in Ref | Clipped Count = min (Count in MT, Max Count in Ref) |
|---|---|---|---|
| the picture | 2 |
1 | 1 |
| picture the | 1 |
0 | 0 |
| picture by | 1 |
0 | 0 |
| by me | 1 |
1 | 1 |
For n = 3, we'll calculate the Trigram Modified Precision:
| Trigram | Count in MT | Max Count in Ref | Clipped Count = min (Count in MT, Max Count in Ref) |
|---|---|---|---|
| the picture the | 1 |
0 | 0 |
| picture the picture | 1 |
0 | 0 |
| the picture by | 1 |
0 | 0 |
| picture by me | 1 |
0 | 0 |
For n =4, we'll calculate the 4-gram Modified Precision:
| 4-gram | Count | Max Count in Ref | Clipped Count = min (Count in MT, Max Count in Ref) |
|---|---|---|---|
| the picture the picture | 1 |
0 | 0 |
| picture the picture by | 1 |
0 | 0 |
| the picture by me | 1 |
0 | 0 |
Now we have computed all the precision scores, let's find the Brevity Penalty for the translation:
Finally, the BLEU score for the above translation is given by:
On substituting the values, we get,
Finally, we have calculated the BLEU score for the given translation.
Having calculated the BLEU Score manually, one is by now accustomed to the mathematical working of the BLEU score. However, Python's NLTK provides an in-built module for BLEU score calculation. Let's calculate the BLEU score for the same translation example as above but this time using NLTK.
Code:
Output:
0.7186082239261684
We can see that the BLEU score computed using Python is the same as the one computed manually. Thus, we have successfully calculated the BLEU score and understood the mathematics behind it.
{kind=link}
{kind=link}