 |
VOOZH | about |
|
VOOZH | about |
An encoder is a neural network component that transforms input sequences (like text) into meaningful numerical representations called embeddings. In transformers, the encoder processes the entire input sequence to capture relationships between all positions. The encoder maps variable-length input sequences to fixed-dimensional feature representations. A common use case is encoding a sentence for classification or question answering.
The encoder functions as the first half of the transformer model, facilitating the internal representation of input elements. It does not merely compress input into vector space but attempts to encode inter-token dependencies via operations that are both parallel and non-local. The encoder architecture learns invariant and position-aware features without relying on recurrence or convolution.
The encoder serves as a significant component in the transformer architecture and plays an important role:
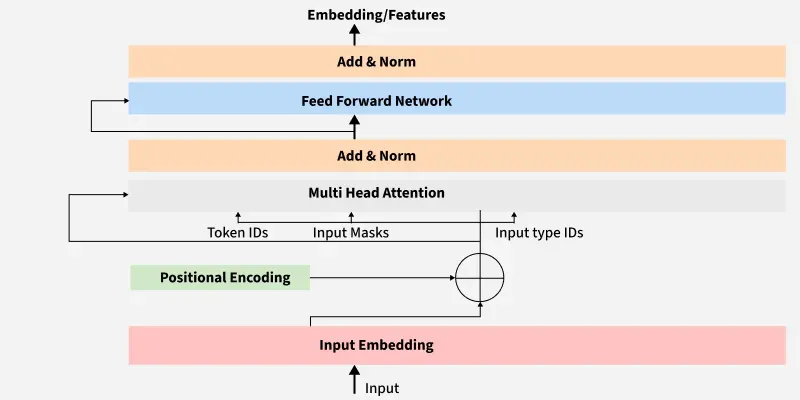
The encoder follows a encoding and representing approach:
You can refer to these articles to understand more about these libraries: Torch, NN, Math
Transformers don’t have recurrence or convolution, so they need positional information to understand the order of tokens.
This class adds sinusoidal positional encodings to token embeddings. These are deterministic and help the model differentiate between positions using sin/cos functions based on dimension.
This module allows the model to attend to different parts of the sequence simultaneously. It splits the input into multiple "heads", computes scaled dot-product attention for each, and then concatenates the results. This helps capture diverse relationships between tokens more effectively than single-head attention.
Each token's representation is passed through a two-layer MLP with ReLU activation, applied independently. This enhances the model's ability to transform and abstract the attended features, enabling richer representations beyond just attention-based mixing.
This is a single layer of the Transformer encoder. It combines multi-head self-attention and feed-forward sub-layers, each followed by residual connections and layer normalization.
This setup helps the model learn stable and expressive representations of sequences.
This stacks multiple Encoder Layer modules to form the full encoder block. It starts with token and positional embeddings, applies dropout, and passes the result through each encoder layer.
The output is a context-rich representation of the input sequence suitable for downstream tasks like translation or classification.
In this example, the encoder is initialized with hyperparameters (embedding size, number of layers/heads, etc.). A random batch of token sequences is passed through, along with a mask to ignore padded tokens during attention. The final output represents the encoded features and the shape.
You can download the source code .
{kind=link}
{kind=link}
{kind=link}