Adagrad is an optimization method that adapts the learning rate for each parameter based on past gradients, improving learning for features with different frequencies.
Adjusts learning rate individually for each parameter
Uses accumulated past gradients to scale updates
Works well for sparse data and varying feature magnitudes
Reduces learning rate over time for frequently updated parameters
Working of Adagrad Algorithm
Adagrad adapts the learning rate for each parameter by using the accumulated sum of squared gradients, allowing more efficient and stable training.
1. Initialization: Adagrad begins by initializing the parameter values randomly, just like other optimization algorithms. Additionally, it initializes a running sum of squared gradients for each parameter which will track the gradients over time.
2. Gradient Calculation: For each training step, the gradient of the loss function with respect to the model's parameters is calculated, just like in standard gradient descent.
3. Adaptive Learning Rate: Adagrad adjusts the learning rate for each parameter based on the accumulated sum of squared gradients, instead of using a fixed rate.
Learning rate is updated as:
is the global learning rate (a small constant value)
is the sum of squared gradients for a given parameter up to time step
is a small value added to avoid division by zero (often set to )
As increases, the learning rate decreases over time
This helps stabilize training and prevents large updates
4. Parameter Update: The model's parameters are updated by subtracting the product of the adaptive learning rate and the gradient at each step:
Where:
is the current parameter
is the gradient of the loss function with respect to the parameter
Use Cases of Adagrad
Works well for sparse data such as NLP and recommender systems
Useful when features have different importance or frequency
Suitable for tasks that prefer stable learning over very fast convergence
May not perform well when a consistent learning rate is needed
In such cases, optimizers like RMSProp or Adam are often preferred
Variants of Adagrad Optimizer
To overcome Adagrad’s rapidly decreasing learning rate, improved variants have been developed.
1. RMSProp (Root Mean Square Propagation):
RMSProp improves Adagrad by using an exponentially decaying average of squared gradients instead of accumulating them, preventing the learning rate from shrinking too quickly.
Uses moving average of squared gradients
Prevents rapid decay of learning rate
Improves performance in deep neural networks
Provides more stable and efficient training
Formula:
Where:
is the accumulated gradient
is the decay factor (typically set to 0.9)
is the gradient
Parameter update:
2. AdaDelta
AdaDelta is an improved version of Adagrad that avoids excessive accumulation of past gradients by using moving averages, leading to more stable and consistent updates.
Uses moving average of squared gradients instead of full accumulation
Prevents learning rate from shrinking too quickly
Provides more stable and bounded updates
Reduces the need to manually tune the learning rate
Formula:
Where:
is the running average of past squared parameter updates
3. Adam (Adaptive Moment Estimation)
Adam is an optimization algorithm that combines the benefits of momentum and adaptive learning rates, making it robust and widely used in deep learning.
Uses moving average of gradients (momentum)
Uses moving average of squared gradients (adaptive learning rate)
Provides fast and stable convergence
Works well across a wide range of tasks and models
Adam has the following update rules
First moment estimate ():
Second moment estimate ():
Corrected moment estimates:
Parameter update:
Adagrad Optimizer Implementation
Below are examples of how to implement the Adagrad optimizer in TensorFlow and PyTorch.
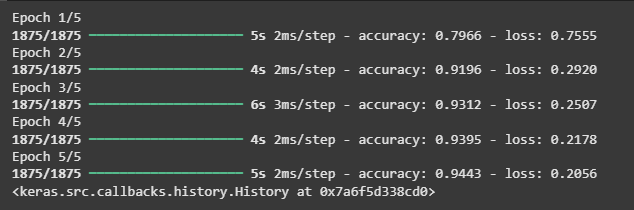
1. TensorFlow Implementation
In TensorFlow, implementing Adagrad is easier as it's already included in the API. Here's an example where:
mnist.load_data() loads the MNIST dataset.
reshape() flattens 28x28 images into 784-length vectors.
Division by 255 normalizespixel values to [0,1].
tf.keras.Sequential() builds the neural network model.
By applying Adagrad in appropriate scenarios and complementing it with other techniques like RMSProp and Adam, practitioners can achieve faster convergence and improved model performance.
Advantages
Adapts learning rates for each parameter, helping with sparse features and noisy data.
Works well with sparse data by giving rare but important features appropriate updates.
Automatically adjusts learning rates, eliminating the need for manual tuning.
Improves performance in cases with varying gradient magnitudes, enabling efficient convergence.
Limitations
Learning rates shrink continuously during training which can slow convergence and cause early stopping.
Performance depends heavily on the initial learning rate choice.
Lacks momentum, making it harder to escape shallow local minima.
Learning rates decrease as gradients accumulate which helps avoid overshooting but may hinder progress later in training.

{kind=link}
{kind=link}
{kind=link}