RMSProp is an adaptive optimization algorithm that improves training speed and stability by adjusting the learning rate for each parameter based on recent gradients.
Adapts the learning rate individually for each parameter
Uses the magnitude of recent gradients to scale updates
Handles non-stationary objectives effectively
Works well with sparse gradients
Commonly used in deep learning for faster and more stable training
Need of RMSProp Optimizer
RMSProp was developed to overcome limitations of earlier methods like SGD and Adagrad by improving learning rate adaptation.
SGD uses a constant learning rate, which can be inefficient
Adagrad decreases the learning rate too quickly over time
RMSProp uses a moving average of squared gradients to adapt learning rates
Maintains a balance between fast convergence and training stability
Widely used in deep learning for efficient optimization
Working of RMSProp Optimizer
RMSProp works by maintaining a moving average of squared gradients to normalize updates and adapt the learning rate for each parameter.
Keeps a moving average of squared gradients
Prevents learning rate from becoming too small (issue in Adagrad)
Scales updates appropriately for each parameter
Handles non-stationary objectives effectively
Suitable for training deep neural networks
Formula:
1. Compute the gradient at time step t
2. Update the moving average of squared gradients
where is the decay rate.
3. Update the parameter using the adjusted learning rate
where is the learning rate and is a small constant added for numerical stability.
Parameters Used in RMSProp
Learning Rate (): Controls the step size during the parameter updates. RMSProp typically uses a default learning rate of 0.001, but it can be adjusted based on the specific problem.
Decay Rate (): Determines how quickly the moving average of squared gradients decays. A common default value is 0.9 which balances the contribution of recent and past gradients.
Epsilon (): A small constant added to the denominator to prevent division by zero and ensure numerical stability. A typical value for is 1e-8.
Implementing RMSprop in Python
We will use the following code line for initializing the RMSProp optimizer with hyperparameters
We load the MNIST dataset, normalize pixel values to [0,1] and one-hot encode labels.
mnist.load_data() loads images and labels.
Normalization improves training stability.
to_categorical() converts labels to one-hot vectors.
3. Building the Model
We define a neural network using Sequential with input flattening and dense layers.
Flatten converts 2D images to 1D vectors.
Dense layers learn patterns with ReLU and softmax activations.
4. Compiling the Model
We compile the model using the RMSprop optimizer for adaptive learning rates, categorical cross-entropy loss for multi-class classification and track accuracy metric.
RMSprop adjusts learning rates based on recent gradients (parameter rho controls decay rate).
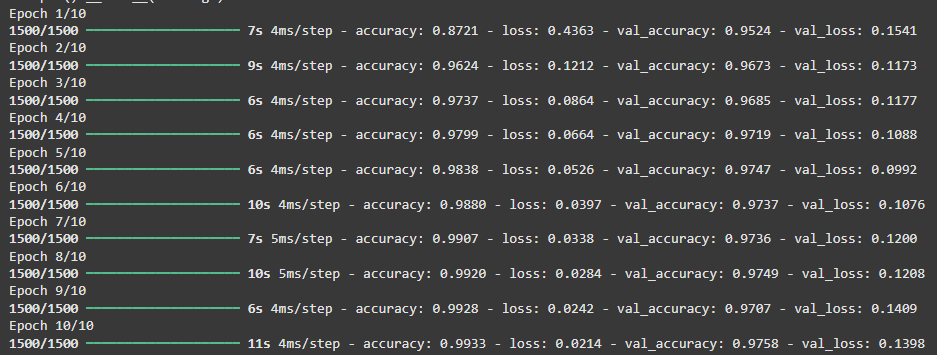
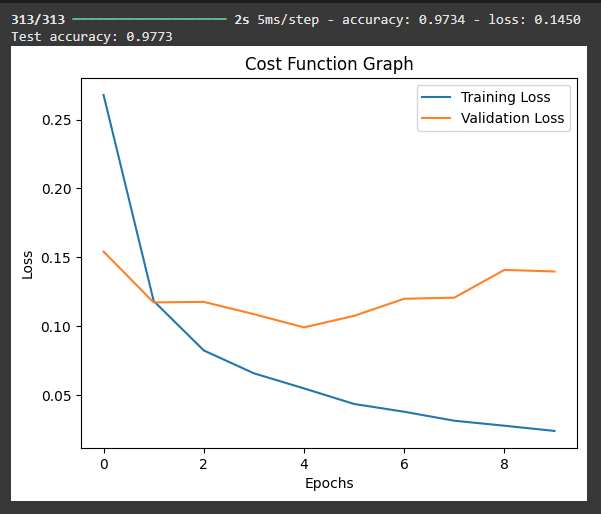
We train the model over 10 epochs with batch size 32 and validate on 20% of training data. validation_split monitors model performance on unseen data each epoch.

{kind=link}
{kind=link}
{kind=link}