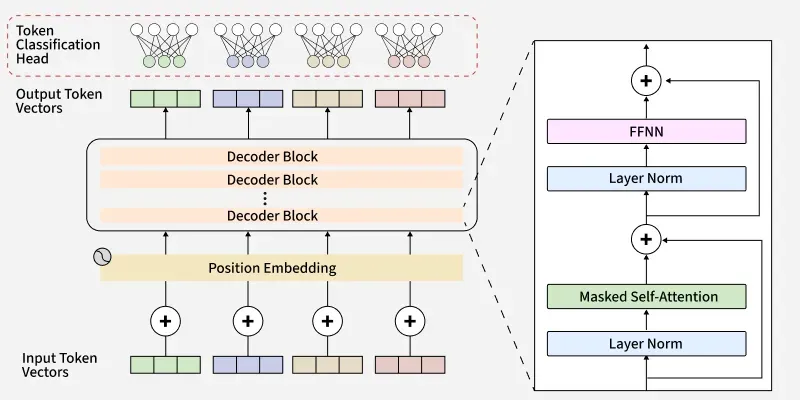
A decoder in deep learning, especially in Transformer architectures, is the part of the model responsible for generating output sequences from encoded representations. In sequence-to-sequence tasks like machine translation, text summarization, or image captioning, the decoder takes the output from the encoder and converts it into a target language or format. It does this step-by-step, attending to both the encoded input and the already generated outputs.
In English-to-French translation, the encoder processes the English sentence, and the decoder generates the French sentence one word at a time, using previously generated words and attention to the encoded sentence.
Mathematical Representation
Masked Self-Attention:
Encoder-Decoder Attention:
Feedforward Network:
Each decoder layer can be defined as:
Where,
X: Input to the decoder
E: Encoder output
Transformer Decoder Implementation
1. Imports
PyTorch and Math libraries are imported for model building and numerical operations.
2. PositionalEncoding class
Adds sinusoidal positional information to token embeddings.
Helps the model understand token positions since transformers lack recurrence.
Values are added to embeddings before input to the attention layers.
3. TransformerDecoderLayer class
Defines one decoder layer containing:
Masked multi-head self-attention to attend to previous tokens.
Multi-head encoder-decoder attention to focus on encoder output.
Feedforward network for non-linear transformation.
Layer normalization and dropout for training stability.
4. TransformerDecoder class
Builds the complete decoder by stacking multiple decoder layers.
Converts token indices to embeddings.
Adds positional encodings.
Applies a sequence of decoder layers.
Uses a final linear layer to map outputs to vocabulary logits.
5. Hyperparameter setup
The hyperparameter setup includes embedding dimension size, attention heads, feedforward layer hidden size, decoder layers, output tokens, input shape for dummy test.
6. Model instantiation
An instance of the TransformerDecoder is created using defined hyperparameters.
Sample input:
tgt: random integers simulating target token indices.
memory: random tensor simulating encoder output.
Forward pass:
Inputs are passed through the decoder to get output logits.
Output shape is (seq_len, batch_size, vocab_size), suitable for classification of each token position over the vocabulary.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}